
Grieder 💻
408 posts


@Morett_the_best @samsantosb @ducaswtf perguntei mais por conta a adequacao desse novo workflow com IA e lembro de ter visto um post uns tempos atras de voces procurando esse perfil. Obrigado pela resposta
Português

@griederdev @samsantosb @ducaswtf não
nós não tinhamos mt dinheiro quando a empresa começou, n tinhamos dinheiro para contratar seniors
nosso time é feito muitos juniors/plenos e poucos seniors
Português

Agreed, the term FDE is now casually used. The truth is, not everyone treats "FDE" the same
True, complete FDE engagements are ones where:
- You embed deeply with customers, figure out the right thing to build, actually ship outcomes, continue to talk to customers and refine/iterate
- You take all the learnings, pain points, successes, gaps back to internal product and engineering and improve the platform/underlying product
- Build evals from the field and partner with research to improve models/agents
It's all about owning the outcome, shipping solutions that solve real problems and have impact, learning from every engagement, and making every future deployment easier, cheaper, faster, and more successful over time
At some point, the amount of work per FDE engagement should decrease if done successfully
Gergely Orosz@GergelyOrosz
I am sorry to say that the FDE roles in 2026 are ulikely to be like those in 2025. The recent FDE roles - standalone, enterprise consulting companies by OpenAI and Anthropic, standalone org unit with far lighter hiring requirements at Google - sound like SE / consultants tbh
English
@rponte @Shinobu_uwu seu conteudo eh fera, parabens! Suas talks ja me ajudaram bastante
Português

testes eh uma área que tive o prazer de curtir desde o inicio da carreira 😁
não sei bem oq vc manja ou pensa em aprofundar, mas um problema comum que se massificou com microservices+clean archi durante a pandemia foi o abuso de testes de unidade.
se tiver tempinho, vale a pena assistir essa talk
youtu.be/ZV4Fl1uEbqw?si…

YouTube
Português


Não sei vocês, mas eu passaria na entrevista do palindromo
Português

@griederdev @akinncar Tasks simples e sistema completo. Eu uso VS Code + GitHub Copilot Pro + GPT-5.4 + Agentmode + SDD. Se se interessar podemos trocar ideia inbox.
Português

@another_1x @samsantosb fluxo de front eh uma perdição sinceramente
Português

@griederdev @samsantosb Po, pior que tenho muita dificuldade em deixar um fluxo bom pra front, mesmo com tudo definido certinho
Português

Recomendo real virarem a chavinha pra usar 100% AI na entrega de código do dia a dia.
Aprendam a otimizar esse fluxo e revisar ele corretamente.
Vão produzir muito melhor e se adequar bem a nova realidade.
Ao meu ver o crucial é o tamanho das tasks.
Contexto sempre foi o maior problema pra fazer uma tarefa e trabalhar com "micro-tasks" aumenta muito a eficiência.
Tenho tido os melhores resultados com PRs de 300~400 linhas.
Português
@simplescuriosos @akinncar qual tamanho de task? e qual framework vc usou de sdd?
Português
@akinncar Quer um conselho? Faz um upgrade aí e vai para o SDD (Spec-Driven Development), coloca nas especificações que você quer TDD como uma das etapas do desenvolvimento. SDD é muito mais profundo do que TDD. Eu tô abismado com meus agentes usando SDD e o quanto eficaz eles se tornaram.
Português
quais são as melhores ferramentas para análise de vídeos com ia?
cc @sseraphini
Português
Grieder 💻 retuiteado


@Hi_Mrinal this second call to see the results what did you use on the endpoint
English

Had a chill call with CTO for backend infra role at company in Dublin (January 7th, 2026)
While the conversation got to know they are running ecom dashboards which is taking nearly 500ms for every query (YESS I KNOW YOU KNOW WE ALL KNOW) crashed constantly during peak sales
Built a go proxy with redis on the call while explaining each and every part. The layer resets expiration on each access, the result first request nearly 230 - 249 ms and afterwards it dropped <10ms
it works because the cache learns from behaviour and backend load drops because only misses hit the database.
Cache pattern used ??
> cache aside with time to live reset on access
English
Fechou gente pra até o fim de Março.
E vou abrir uma ultima turma pra inicio de abril com os atrasados do ENEM.
DM abertas e se comentar aqui eu chamo também
Sam@samsantosb
Pessoal to pensando em montar uma pequena turma(max 5 pessoas) pra fev/mar pra lecionar alguns conteudos: - JS/TS - Node/Bun - Arquitetura de software - Tratamento de Erros - Serviços AWS com foco em startups de pequeno/medio porte - Conceitos de sistemas distribuidos, fintechs e web dev em escala uteis - Topicos de programção funcionais uteis no dia a dia de dev Web - Entrevistas de Node/TS no geral (pra qlqr senioridade) Algo que leve 6~8h 3~4 fds - 2h/fds (decidindo ainda) Se alguém tiver um interesse pode comentar aqui ou mandar DM
Português
@lcs_bttlm @LukeberryPi normalmente eh mesma stack mas o contexto ajuda sim
Português

@LukeberryPi Dúvida genuína: monorepo funciona somente com mesma stack? Tipo react + node ou é bom também pra stacks tipo java + react. Pra contexto do agente creio que seja bom independente da stack, mas pra compartilhar arquivos nao ficaria tão bom
Português

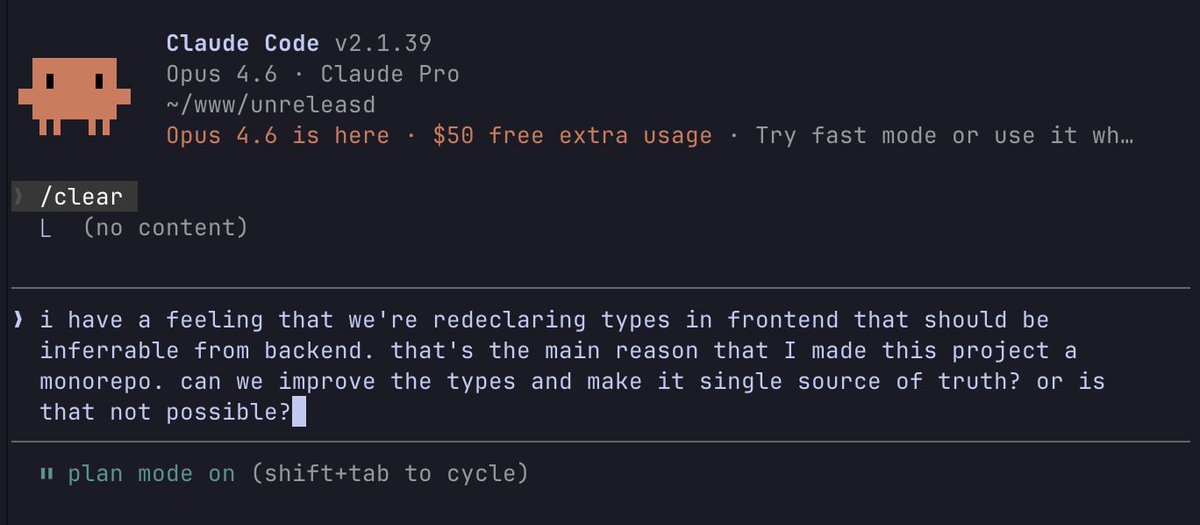
outro exemplo de prompt pro Claude Code Opus 4.6
como melhorar os tipos de um monorepo
vou voltar aqui com os resultados/diffs
Português

@Grimmacez não vi nenhum bench sobre o GC bem perceptível então?
Português
Pô, puta update foda no go 1.26
Agora o GreenTea GC, que é funciona diferente do atual, é padrão, trazendo um ganho de 10 a 30% de performance em relação aos ciclos de coleta, o que é mt foda
CGO também teve um boost de performance em runtime mt bom, mas é beeem fora do que eu trampo
Overall, um update mt bom
cc
@samsantosb @sseraphini @meunomeebero
Português