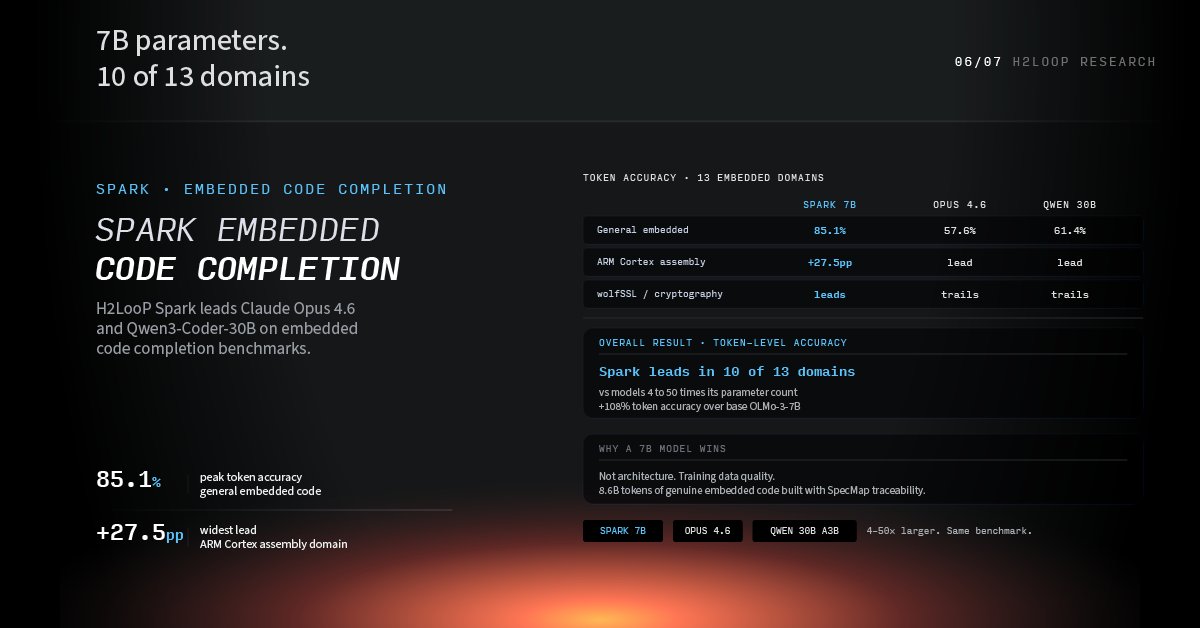
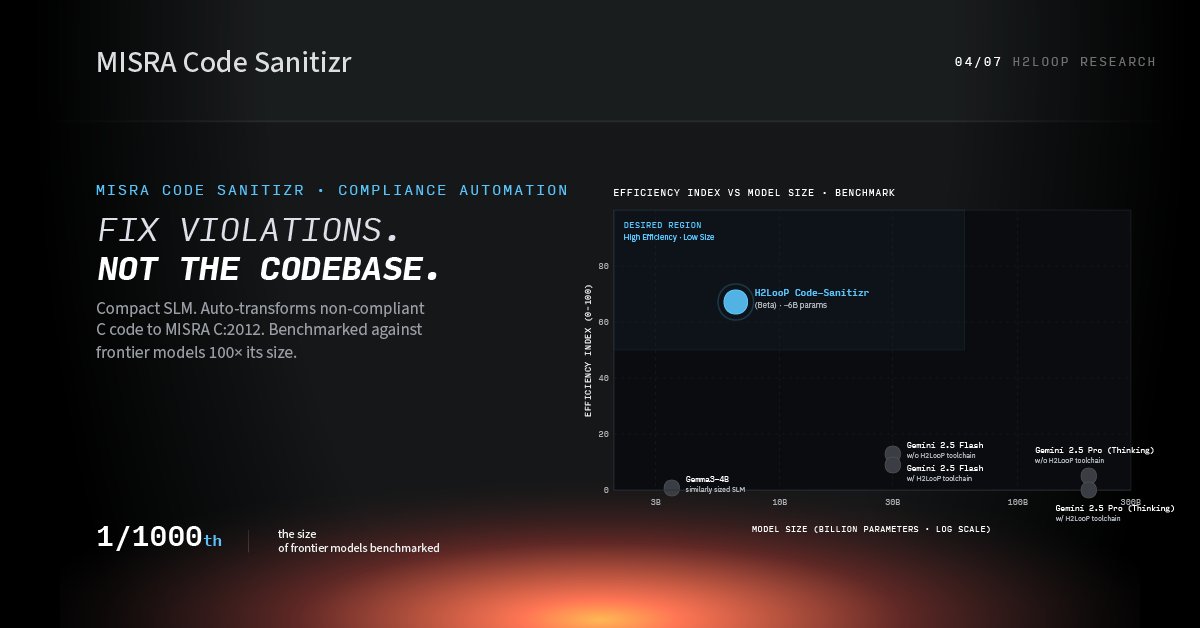
Tweet fijado

Civilization runs on system software. It cannot fail.
Most AI coding tools were not built for this domain. H2LooP was.
#h2loopai #EmbeddedSystems #SystemSoftware #AIInfrastructure
English
H2LooP
39 posts

@h2loopai
H2Loop is an AI lab building domain-specific intelligence for lower-level system software and enterprise infrastructure.