Tweet fijado

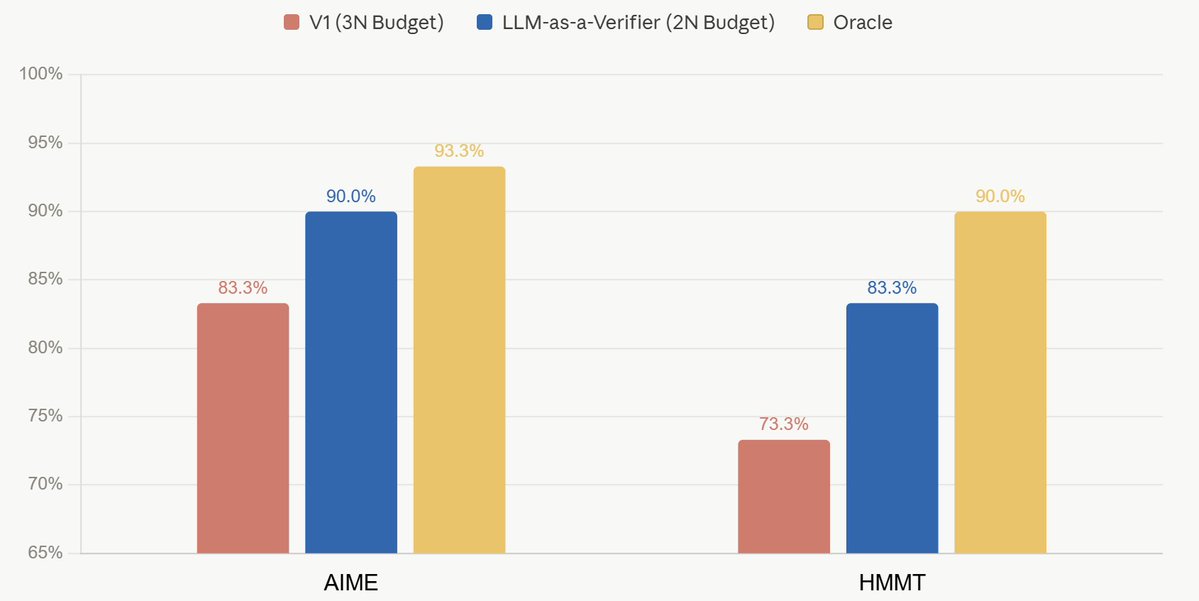
We release LLM-as-a-Verifier 🧠: A general-purpose verification framework that achieves SOTA 👑 on Terminal-Bench 2 (86.4%) and SWE-Bench Verified (77.8%) by scaling:
- scoring granularity
- repeated verification
- criteria decomposition
📄 Blog & Code: llm-as-a-verifier.notion.site

English