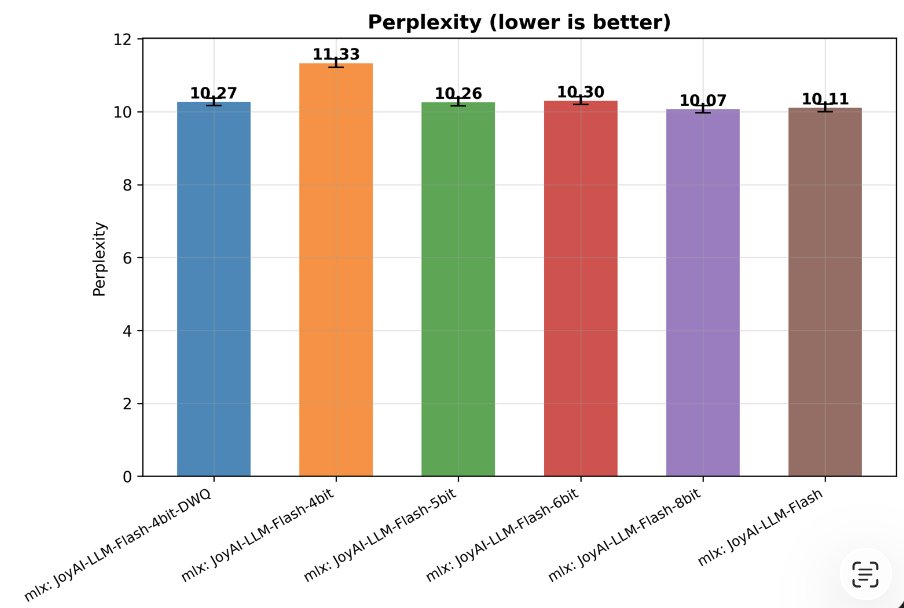
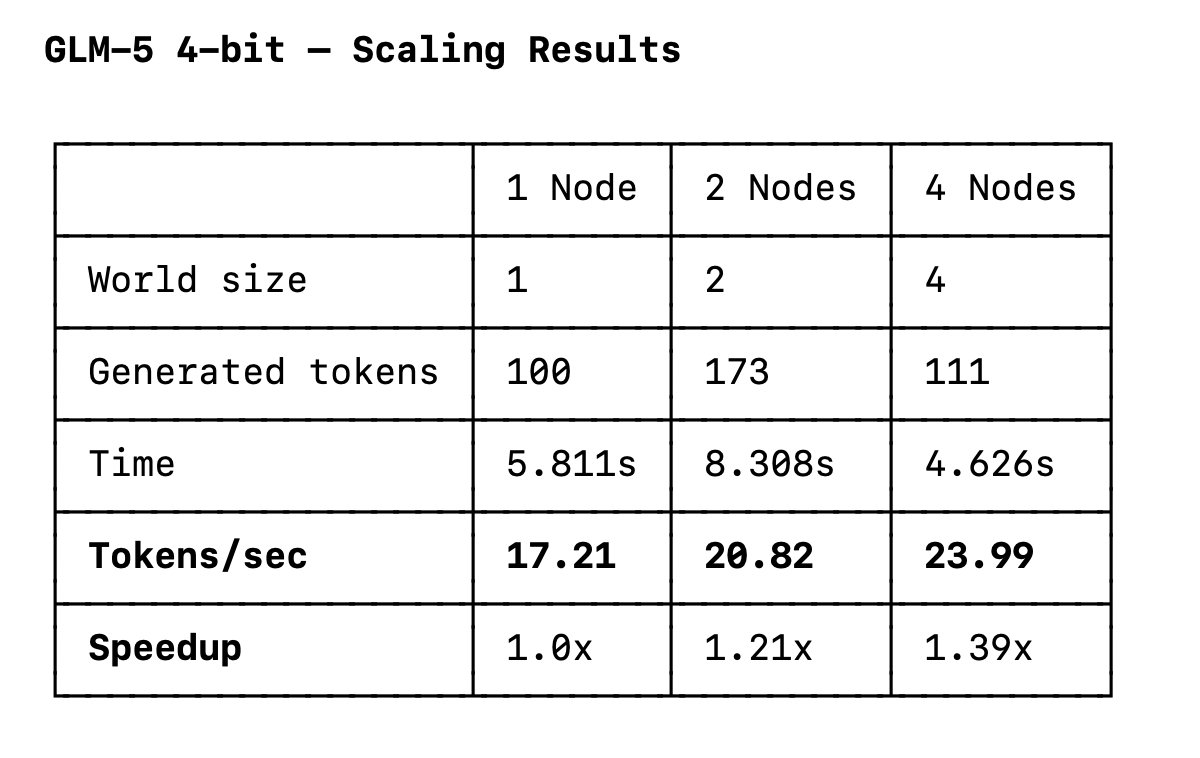
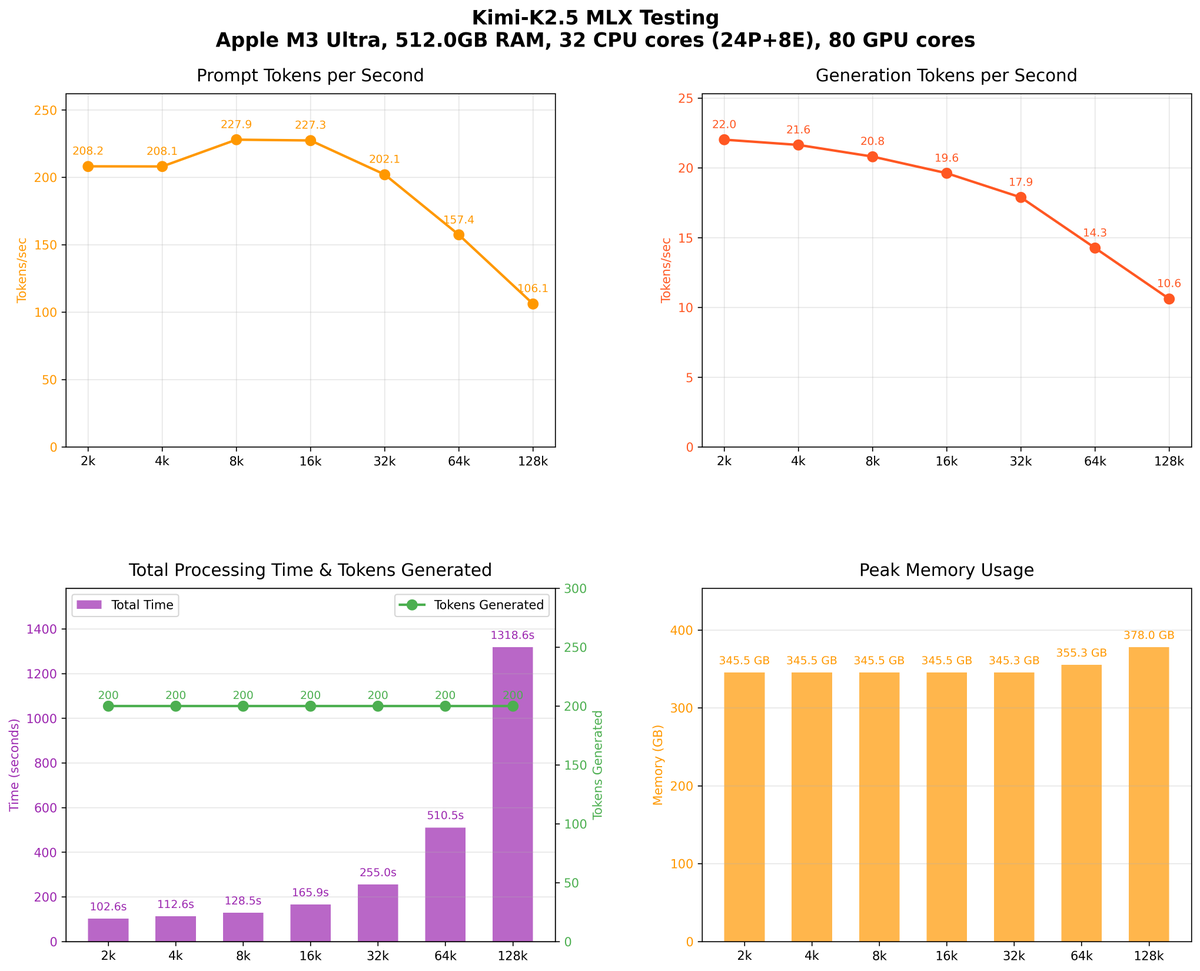
Tarjei Mandt retuiteado

Recently, @awnihannun asserted that 'According to benchmarks Qwen3.5 4B is as good as GPT 4o.' This drew controversy: Is the 4B just benchmaxxed? How could a 4B be as good as GPT-4o? I tried to test this scientifically. The answer to the question is likely: yes, in most cases.
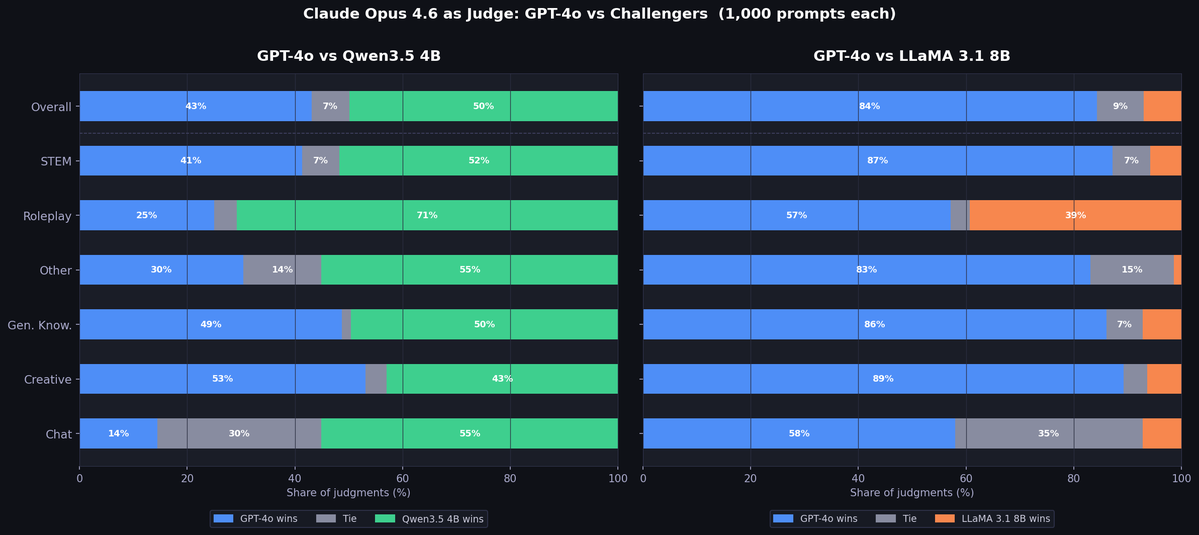
English