Tweet fijado

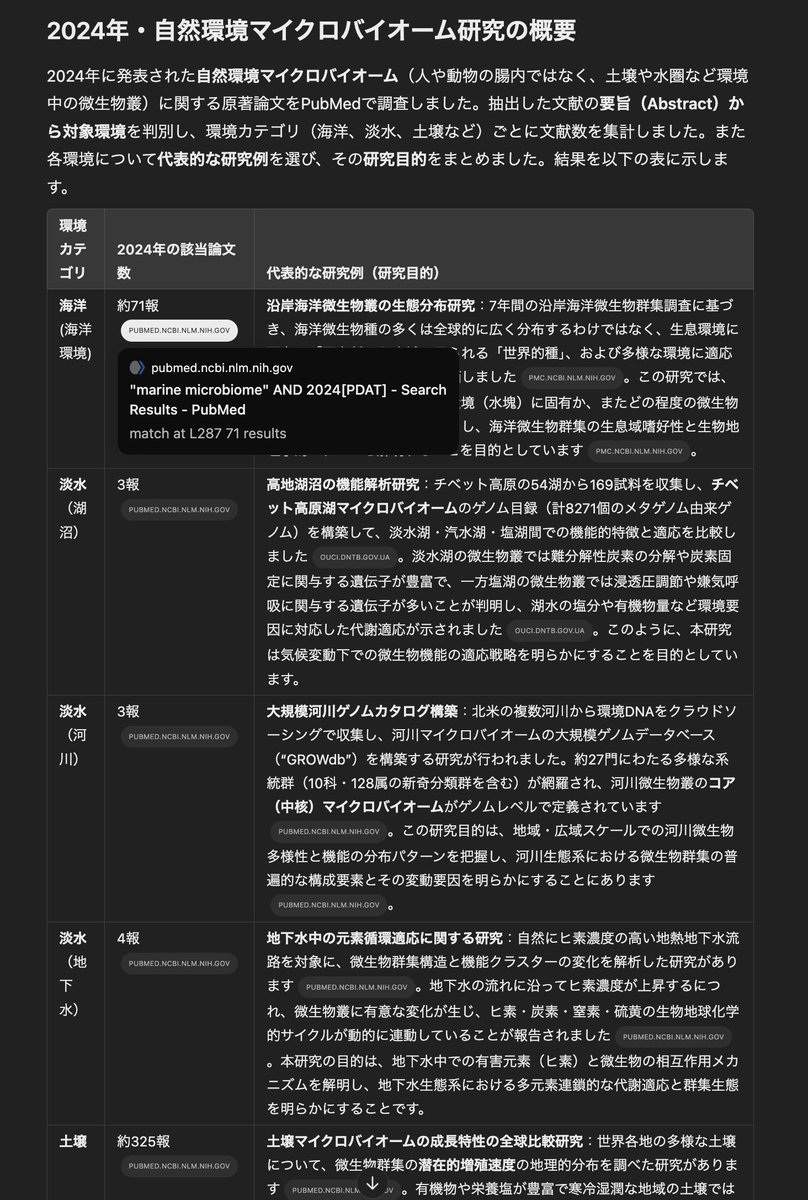
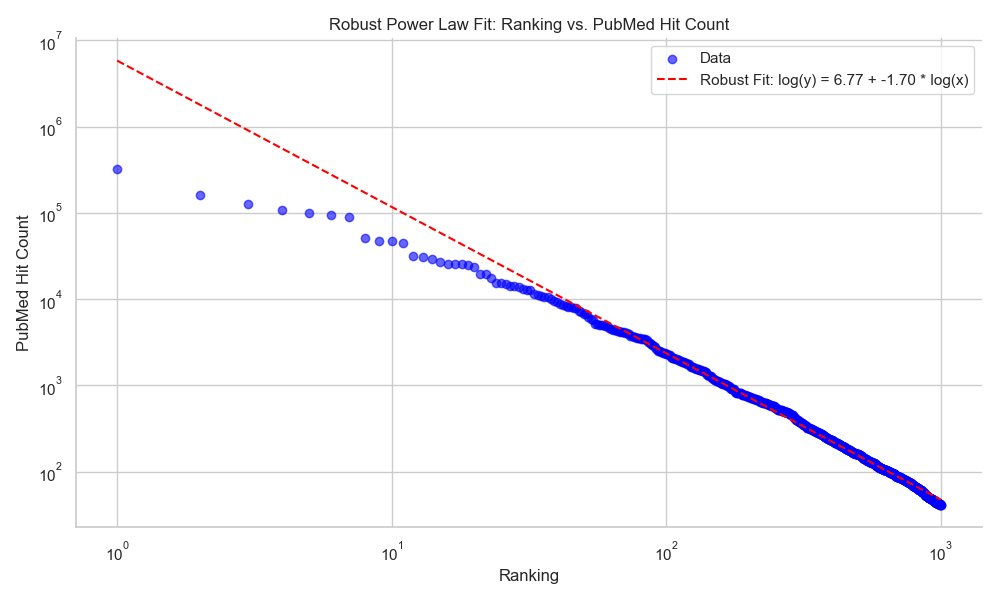
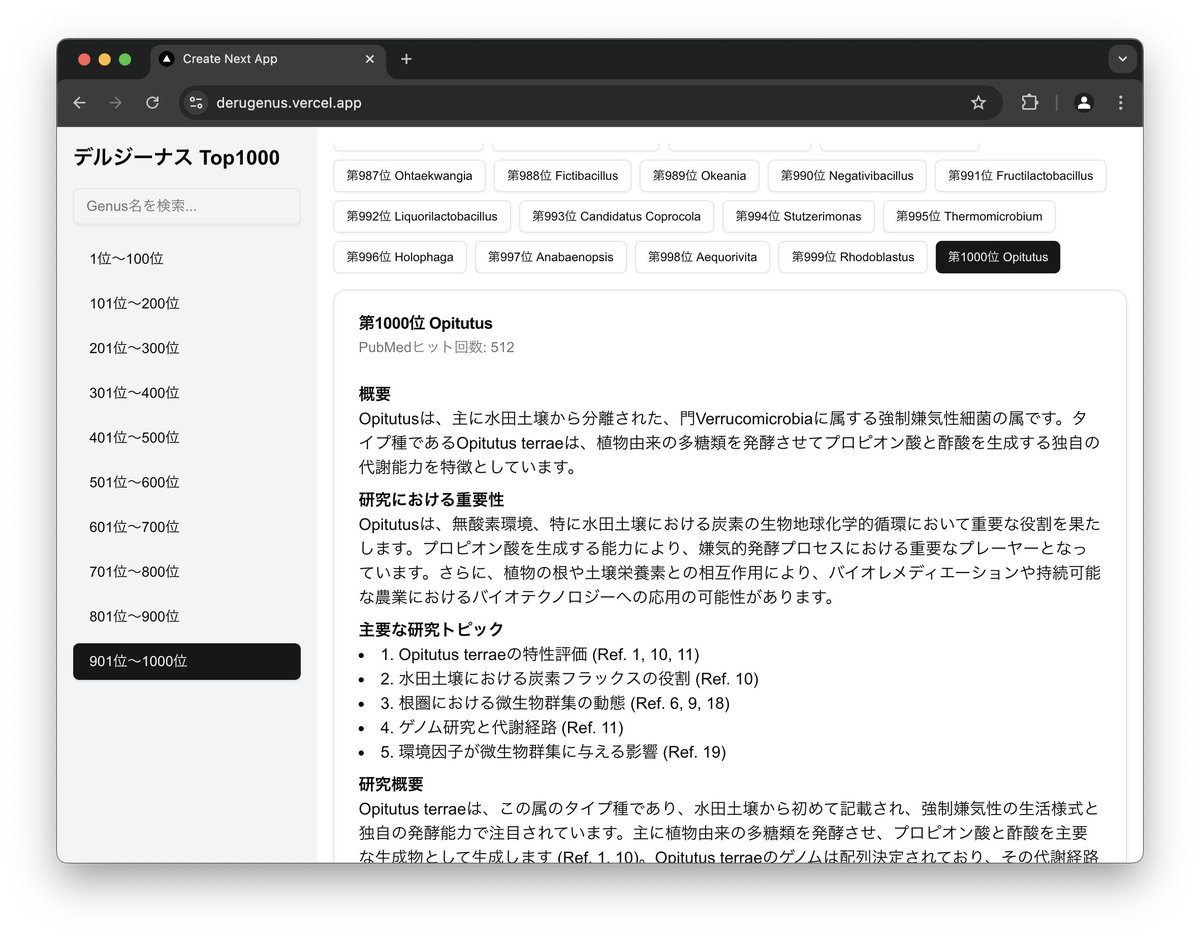
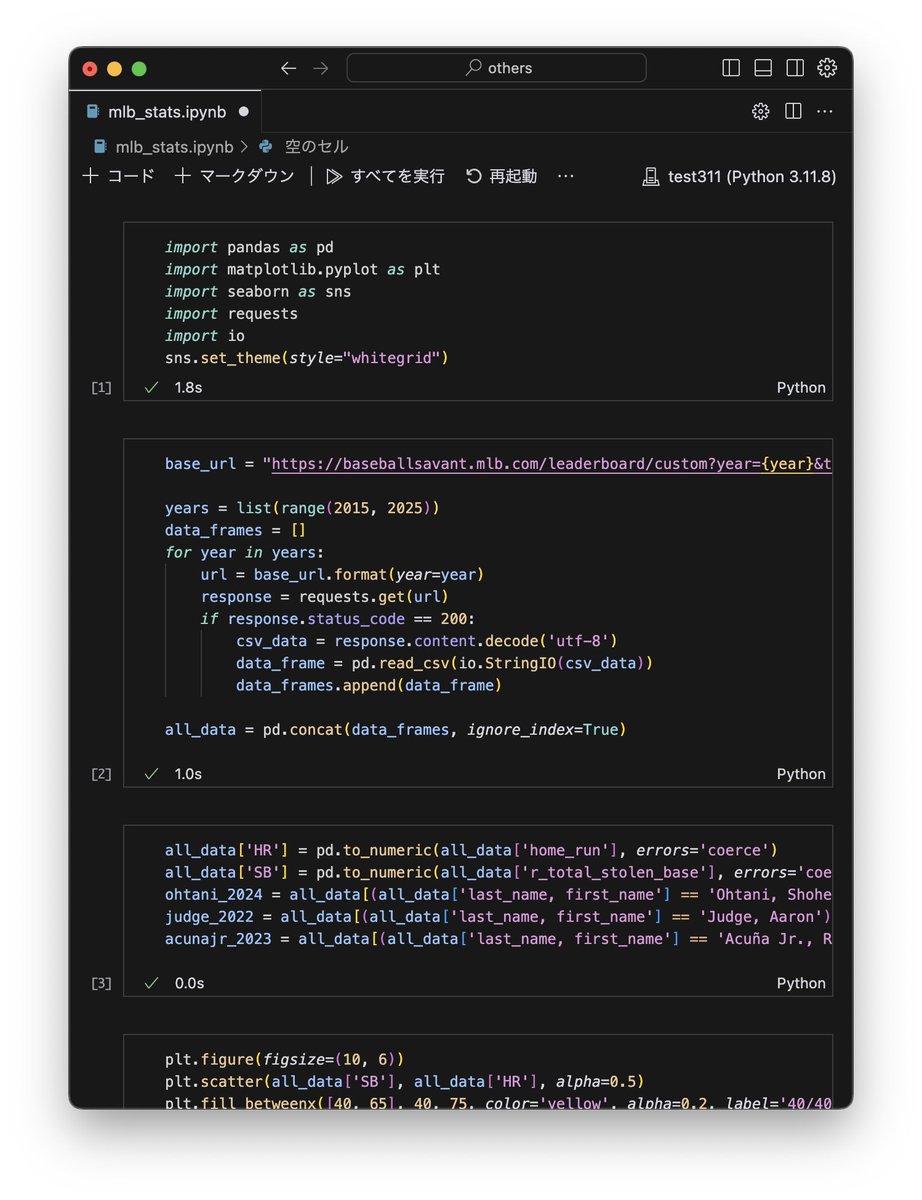
New preprint: A large language model (LLM) powered framework for fully automated extraction and harmonization of subject metadata from research papers.
Applied to human gut microbiome studies:
- 26,435 papers processed
- 400,000+ samples integrated
- Metadata now searchable
bioRxiv Bioinfo@biorxiv_bioinfo
Automated Harmonization and Large-Scale Integration of Heterogeneous Biomedical Sample Metadata Using Large Language Models biorxiv.org/cgi/content/sh… #biorxiv_bioinfo
English