Mathew Koretsky retuiteado

NEW Resource: CARDBiomedBench: a benchmark for evaluating the performance of #LLMs in biomedical research.
Read it here: buff.ly/FQm6OEu
English
Mathew Koretsky
22 posts


@mkoretsky1
machine learning engineer | @DataTecnica | @NIH @BiomedArena | @uvmvermont | views/tweets are my own


Frontier models are moving fast, but are they getting better at biomedical research? We just ran a fresh benchmark update using CARDBiomedBench, our evaluation suite for genetics, disease associations, and drug discovery QA. Instead of looking only at “did it answer?”
🧬 New at BiomedArena.AI: smarter Biomedical Knowledge Agents + Knowledge Mode We just shipped the latest update to BiomedArena.AI, the world’s first platform for benchmarking LLMs on biomedical research tasks.
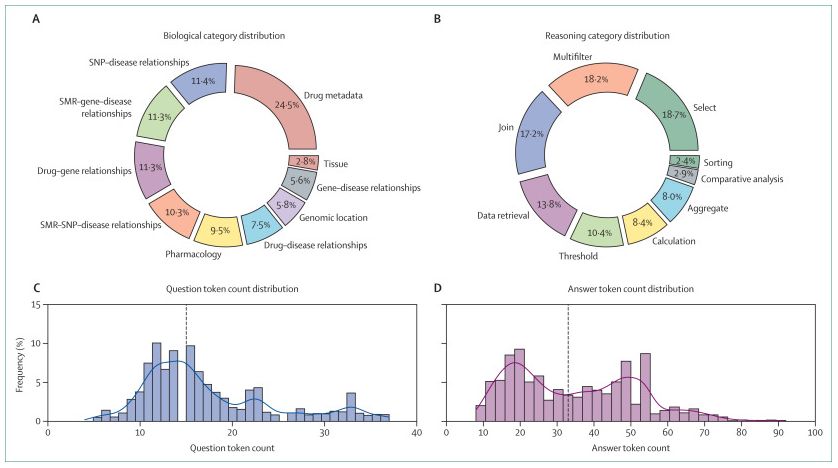
We evaluated 12 top models using CARDBiomedBench, a biomedical benchmark with 68K+ expert QA pairs across GWAS, SMR, drug discovery & more. 🧠 No model aced both safety and accuracy. 🤖 GPT-4o = bold but risky 🤔 Claude-4.0 = cautious but wrong More is coming soon.
🚀 New LLMs now LIVE on BiomedArena 🧬 Test GPT-5, Claude-4.1, Gemini 2.5 and more, on your toughest biomedical queries. All free. All benchmarked. biomedarena.ai 📉 Can AI be accurate and safe in biomedicine? See the surprising results 👇🧵
🧬 BiomedArena is here! We’re honored to partner with @DataTecnica and @NIH CARD, who developed BiomedArena to evaluate LLMs for biomedical discovery, and to help expand this domain-specific track in community-driven evaluations. 🧪 Biomedical science is complex, high-stakes, and constantly evolving. 📊 CARDBiomedBench & tabular reasoning tests show that no current model can reliably meet the reasoning & domain-specific knowledge demands of biomedical researchers. Learn more about BiomedArena in thread 👇 🧵 #AI #LLMs #BiomedicalAI #AIEvaluation #OpenScience #LMArena #BiomedArena #NIH




A new AI-assisted data standard accelerates interoperability in biomedical research medrxiv.org/cgi/content/sh… #medRxiv


