The next frontier for AI innovation should focus on transforming end-to-end workflows within vertical industries into step-by-step, iterable, and continuously optimizable `Agentic` processes.
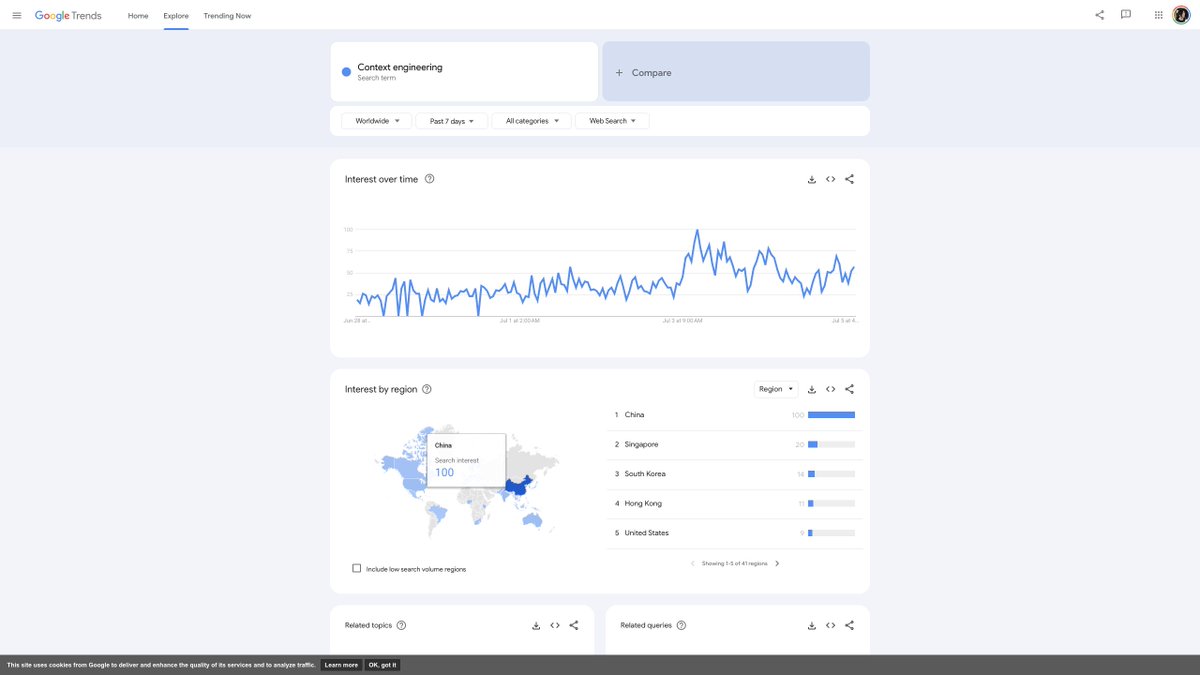
So, would it be fair to say that those active AI experts from China on Twitter and YouTube are intensely keeping up with new AI terminology like Context Engineering?
I get the feeling that AI is making a once-impractical playbook suddenly viable: rapidly assembling—or repackaging existing product lines into—something that resembles a newly funded startup, using it as a software marketing strategy to gain attention and collect GitHub stars.
In earlier days, posting on social media could reliably draw in readers, giving newsrooms a bit more flexibility with real-time content production. Now, with search taking the lead, content teams are under greater pressure to deliver faster and more efficiently.
A leading editor noted a dramatic drop in traffic from Facebook, decreasing from one-fifth to just one-twentieth. As user attention shifted, search engines have re-emerged as the dominant source of traffic.
"Hey Claude with computer use, watch this construction site video & write up things you see that dangerous or good, create a spreadsheet of critical issues to address" (sped up)
How firms use AI as manager, coach or panopticon is going to have a big impact on what work becomes.
Recently, our Japanese media crawler has frequently picked up the name Shunsaku Sagami. He's the 33-year-old founder of M&A Research Institute, a company specializing in using AI for corporate M&A. As of October 2023, his assets have reached $1.3 billion USD (~=42.3 billion TWD).
yesterday evening i gave a presentation to founders, investors, and the ai community at @aixventureshq on how to think about ai application development. it was well received so i'm going to reproduce it in full here on x the everything app (which is also now a slide deck app).
SQL injection-like attack on LLMs with special tokens
The decision by LLM tokenizers to parse special tokens in the input string (, <|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
!!! User input strings are untrusted data !!!
In SQL injection you can pwn bad code with e.g. the DROP TABLE attack. In LLMs we'll get the same issue, where bad code (very easy to mess up with current Tokenizer APIs and their defaults) will parse input string's special token descriptors as actual special tokens, mess up the input representations and drive the LLM out of distribution of chat templates.
Example with the current huggingface Llama 3 tokenizer defaults:
Two unintuitive things are happening at the same time:
1. The <|begin_of_text|> token (128000) was added to the front of the sequence.
2. The <|end_of_text|> token (128001) was parsed out of our string and the special token was inserted. Our text (which could have come from a user) is now possibly messing with the token protocol and taking the LLM out of distribution with undefined outcomes.
I recommend always tokenizing with two additional flags, disabling (1) with add_special_tokens=False and (2) with split_special_tokens=True, and adding the special tokens yourself in code. Both of these options are I think a bit confusingly named. For the chat model, I think you can also use the Chat Templates apply_chat_template.
With this we get something that looks more correct, and we see that <|end_of_text|> is now treated as any other string sequence, and is broken up by the underlying BPE tokenizer as any other string would be:
TLDR imo calls to encode/decode should never handle special tokens by parsing strings, I would deprecate this functionality entirely and forever. These should only be added explicitly and programmatically by separate code paths. In tiktoken, e.g. always use encode_ordinary. In huggingface, be safer with the flags above. At the very least, be aware of the issue and always visualize your tokens and test your code. I feel like this stuff is so subtle and poorly documented that I'd expect somewhere around 50% of the code out there to have bugs related to this issue right now.
Even ChatGPT does something weird here. At best it just deletes the tokens, at worst this is confusing the LLM in an undefined way, I don't really know happens under the hood, but ChatGPT can't repeat the string "<|endoftext|>" back to me:
Be careful out there.
Republican presidential candidate former President Donald Trump raises his fist as he is rushed off stage after an assassination attempt during a campaign rally in Butler, Pa. @apnews