
Today I am building a full stack chat application without any AI usage just for the kicks - only documentations, google search and muscle memory. Took the inspiration from @cneuralnetwork
#feelinglikeits2022

English
Satya Narayan
1.8K posts

@satyaxtwt
building local-native supermemory ai agent for individuals • ai research x product



Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use. Its capabilities exceed those of any model we’ve ever made generally available.
"i make things for myself" this is the best underlying principle for great business ideas. create smth that you wish to exist in the world for you. create smth that you feel the need in the world. your country. your city. or your village. as mentioned by @jasonfried and @dhh, "scratch your own itch" ppl often ask "how to get a unique idea for a project?" that's the way.




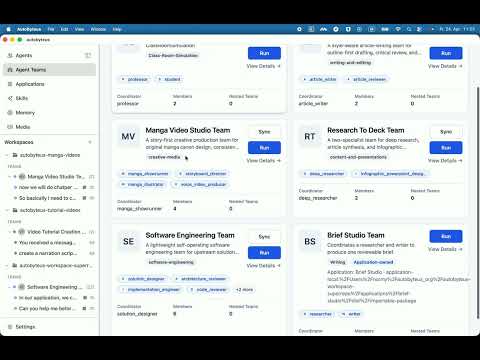

Agently: A platform to host, run and monitor AI Agents This is the updated README.md of the project which is at github.com/satyanvm/Agent… and currently the v1 is in build progress This is a deep dive into the architecture of it, enjoy the read: # Agently A **Durable Autonomous Agent Execution Platform** — a managed runtime and control plane for long-running, multi-agent, browser-capable AI workflows. > Agently is not an AI agent. It is the cloud that agents run on. > Start a workflow, close your laptop, come back days later, and inspect everything it did — > logs, reasoning traces, browser activity, and results. The defining promise — *"close your laptop, come back in two days, the work is still running and you can see everything it did"* — makes **durability**, not intelligence, the core problem. Almost every decision below is downstream of that promise. --- ## Architecture ### Product category A **durable autonomous agent execution substrate** — the "Vercel/Temporal for agents." We sell the layer agents run on (durable execution, observability, browser sessions, secrets, scheduling, notifications), not the agents themselves. | Layer | What it is | Who owns it | |---|---|---| | **Authoring** | How a workflow is defined (graph / DSL / code) | Pluggable — we host frameworks | | **Execution / Durability** | Running it for days, surviving crashes & disconnects | **Us. This is the moat.** | | **Observability** | Logs, reasoning traces, browser replay, results | **Us.** | Differentiation vs. adjacent tools: - **n8n** — integration automation; short deterministic steps, no autonomous reasoning over hours. - **CrewAI / LangGraph** — agent *frameworks* (libraries). They run *inside* Agently; they don't host it. - **Browserbase** — one *component* (the browser layer) of what we offer; no orchestration or durability. - **Relevance AI / Lindy** — packaged assistants for short tasks; not an open long-horizon execution substrate. ### Design principles 1. **Control plane / data plane split** — managing runs (API, DB, UI) is separate from executing them (workers). The control plane stays up even when agents crash. 2. **The database is the source of truth, not worker memory** — every meaningful step is persisted. Workers are cattle, not pets; the run survives any worker dying. 3. **Durable queue over Postgres first** — `claim_next_run()` + `FOR UPDATE SKIP LOCKED`. No Kafka/Temporal until usage earns the need. 4. **Append-only logs, streamed** — written once, never mutated, tailed live. 5. **The browser is an external, isolated service** — never in-process with the orchestrator. 6. **Treat the agent as semi-untrusted** — it acts on hostile web content (prompt injection), so isolate it from the control plane, not just users from each other. ### System overview ``` ┌──────────────────────────────────────────────┐ │ USERS │ │ (dashboard, run viewer, live logs/browser) │ └───────────────────────┬──────────────────────┘ │ HTTPS / WebSocket(SSE) ▼ ┌──────────────────────────────── CONTROL PLANE ──────────────────────────────────┐ │ ┌───────────────┐ ┌───────────────────┐ ┌────────────────────────┐ │ │ │ FRONTEND │◄────►│ API / BACKEND │─────►│ NOTIFICATION LAYER │ │ │ │ Next.js │ │ REST + WS/SSE │ │ email/webhook/slack │ │ │ │ (apps/web) │ │ authZ, run mgmt │ │ │ │ │ └───────────────┘ └─────────┬─────────┘ └────────────────────────┘ │ │ ▼ │ │ ┌───────────────────────────┐ │ │ │ STORAGE LAYER (truth) │ │ │ │ Postgres (Supabase) │ │ │ │ Object store (artifacts) │ │ │ │ Secrets vault (KMS) │ │ │ └─────────────┬─────────────┘ │ └────────────────────────────────────┼────────────────────────────────────────────┘ │ durable queue (runs table, SKIP LOCKED) ▼ poll / claim / lease / heartbeat ┌──────────────────────────────── DATA PLANE ─────────────────────────────────────┐ │ ┌──────────────────────────────────────────────────────────────────────┐ │ │ │ WORKER POOL (apps/worker) │ │ │ │ Orchestrator → claim/lease/retry/cancel/heartbeat │ │ │ │ Workflow Engine→ DAG: what runs next + checkpoint to Postgres │ │ │ │ Agent Runtime → prompt→LLM→tool loop (sandboxed); framework adapter │ │ │ └───────────────────────────────┬──────────────────────────────────────┘ │ │ │ CDP / API │ │ ▼ │ │ ┌──────────────────────────────────────────────────────────────────────┐ │ │ │ BROWSER LAYER (isolated) Browserbase (MVP) → self-hosted later │ │ │ │ one session per agent-run · live view · session replay │ │ │ └──────────────────────────────────────────────────────────────────────┘ │ │ LOGGING: workers append events → Postgres (index) + object store (blobs) │ │ + live stream to API (pub/sub) │ └──────────────────────────────────────────────────────────────────────────────────┘ ``` ### Components - **Frontend** (`apps/web`, Next.js) — authoring UI, run list, live run viewer (streaming logs, reasoning timeline, embedded browser live-view, artifacts). Stateless; talks only to the API. - **API / Backend** — auth, workflow CRUD, run lifecycle, log/artifact serving, live-event fan-out. Manages state and brokers streams; **does not execute agents**. - **Task Orchestrator** (worker) — claims runs via `claim_next_run()`, owns lease/heartbeat/retry/ timeout/cancel. The *"is this run alive and who owns it"* layer. - **Workflow Engine** (worker) — interprets the workflow DAG, decides what runs next, checkpoints to Postgres, passes outputs between agents. The *"what happens next"* durable state machine. - **Agent Runtime** (sandboxed, worker) — executes one agent step: prompt → LLM → tool → repeat, captures the reasoning trace. Framework adapter (native / LangGraph / CrewAI) lives here. - **Browser Layer** (external) — one isolated session per browser-using agent-run, with live view and replay. Browserbase in MVP, behind a `BrowserProvider` interface. - **Logging Layer** — append-only structured events; metadata/index in Postgres, large blobs in object storage, live-streamed to clients. - **Storage Layer** — Postgres (source of truth + queue + log index), object store (artifacts/ screenshots/recordings), KMS-backed secrets vault. - **Notification Layer** — reacts to run state transitions (completed/failed/needs-input) → email / webhook / slack / push. Decoupled and replayable. ### Execution flow ``` User defines workflow ─► API persists (versioned) ─► User clicks Run └► API creates workflow_runs row (status=queued) ─► returns run_id immediately (user can close laptop NOW) ◄── the core promise └► Worker calls claim_next_run() (FOR UPDATE SKIP LOCKED) ─► lease + heartbeat (worker dies → lease expires → another worker RESUMES FROM CHECKPOINT) └► Workflow Engine walks the DAG, checkpointing each node to Postgres └► Agent Runtime runs each step (LLM + tools), logging every reasoning/tool/LLM event └► Browser tool → isolated session via CDP; actions + screenshots logged; live-view + replay └► All nodes terminal ─► status=completed/failed ─► artifacts persisted ─► NOTIFICATION fires └► User returns later ─► full timeline, reasoning trace, browser replay, artifacts, cost ``` Durability invariants: progress lives in `workflow_runs` + checkpoints (never only in RAM); steps are idempotent/resumable (attempt counters, results written before advancing the frontier, idempotency keys for external side effects); any worker can be killed at any time without losing the run. ### Key decisions | Area | Decision | Why | |---|---|---| | **Orchestration** | Thin **custom orchestrator** + framework **adapters** (native first, LangGraph then CrewAI as guest executors) | Durability is the moat and can't be outsourced; frameworks plug in at the step boundary, keeping us framework-neutral. | | **Durable queue** | **Postgres `FOR UPDATE SKIP LOCKED`** (`claim_next_run()`), not Kafka/Temporal | Simple, debuggable, right-sized for 100–1k users; migrate when concurrency demands it. | | **Browser** | **Browserbase** behind a `BrowserProvider` interface | Live-view + replay are core and hard to build; a solo dev shouldn't run a Chromium fleet in MVP. Swap to self-hosted when it becomes the #1 cost driver (~1k users). | | **Cloud model** | **Managed cloud** for MVP; architect the `ComputeProvider` seam for future **BYOC** | Primary persona wants "click Run," not cross-account IAM. BYOC is a Phase-4 enterprise feature, enabled by the control/data-plane split. | | **LLM cost** | **Bring-your-own-LLM-key** by default, even in Managed | Removes the largest variable cost from our books and from runaway-loop risk. | ### Data model All entities root at `user_id`; **Row-Level Security** on every user-owned table. ``` users 1─N workflows 1─N workflow_runs 1─N agent_runs 1─N browser_sessions │ │ ├─N logs (also ref agent_runs / browser_sessions) ├─N artifacts └─N notifications agents (reusable definitions) ──< referenced by workflows.definition & agent_runs > secrets (KMS-encrypted refs) ──< owned by users > ``` - `workflows` — versioned definitions (DAG of agent steps + control flow + triggers); runs snapshot the version they used. - `workflow_runs` — one execution **and** the durable queue entry (lease/attempt/idempotency/ `engine_state` checkpoint fields). - `agent_runs` — one agent step; `parent_agent_run_id` enables hierarchical/manager sub-agents; multiple rows per workflow_run = parallel agents. - `logs` — append-only, ordered by `(workflow_run_id, seq)`; small payloads inline, large payloads in object storage; time-partitioned with retention by plan. - `browser_sessions`, `artifacts`, `notifications` — hang off `workflow_runs`. ### Security - **Secrets** — KMS envelope encryption; decrypted just-in-time into the sandbox, scoped to the step, never logged. - **User isolation** — RLS enforced in the database (defense in depth beyond the app layer). - **Browser isolation** — one fresh session per agent-run, network-segmented from the control plane; page content and downloads treated as hostile. - **Container isolation** — each agent step in an isolated sandbox (hardened containers → gVisor/ Firecracker at scale); default-deny egress with an LLM/browser/tool allowlist; per-run CPU/memory/ wall-clock/**token & browser-minute budgets** to contain runaway loops and cost bombs. ### Cost drivers Ranked: **browser sessions** → **worker compute** → **LLM tokens** (≈0 to us with BYO-key) → storage/ egress → DB. Levers baked in early: per-run budgets, BYO-LLM-key default, idle-suspension for mostly-waiting runs, log/artifact cold-tiering, and the browser-provider swap. ### Roadmap | Phase | Theme | Focus | |---|---|---| | **1 (4 wks)** | *Close your laptop* | Durable single-agent execution: schema + migrations (`0001_init`, `0002_rls`, `0003_queue`), claim/lease/heartbeat worker that **resumes after a kill**, streaming logs, email notify. | | **2 (8 wks)** | *Watch it work* | Browser via Browserbase, live-view + replay, reasoning timeline, artifacts, cost accounting, scheduled/webhook triggers, sandbox hardening + budgets. | | **3 (3 mo)** | *A team of agents* | Multi-agent DAG (parallel/conditional/loop/sub-agents), LangGraph then CrewAI adapters, Slack/push, human-in-the-loop `needs_input`, idle-suspension. | | **4 (6 mo)** | *Open it up* | Bring-Your-Own-Cloud, self-hosted browser pool, stronger isolation, teams/RBAC, templates/marketplace, possible Temporal migration. | --- ## Glossary **Lease** — a time-limited claim a worker takes on a run, recorded as `lease_expires_at` on the `workflow_runs` row. It answers *"is this run still owned?"* When a worker claims a run it sets `claimed_by` and an expiry (e.g. `now + 30s`). The worker is responsible for the run only until that expiry — it rents the run, it doesn't own it forever. If the lease lapses, another worker may reclaim the run and resume it from the last checkpoint. This is what makes a crashed worker recoverable instead of leaving a run stuck in `running` forever. **Heartbeat** — the worker periodically renewing its lease while it is alive and working (e.g. every 10s push `lease_expires_at` forward). It answers *"is the owner still alive?"* The heartbeat is what distinguishes a *crashed* worker from one that is merely taking a long time on a legitimate hours- or days-long step. - Heartbeat interval must be **comfortably shorter** than the lease (rule of thumb: ~1/3). The gap `lease − heartbeat` is the safety margin: the lease covering several heartbeats means the worker can miss one or two renewals to a GC pause / network blip / clock skew **without** its run being falsely reclaimed. Renew == lease leaves zero slack and any jitter causes a false steal. - A missed heartbeat is **skipped, not queued** — it does not pile up and fire twice later. - Renewal is **idempotent**: it *sets* `lease_expires_at = now + duration` (absolute), it does not *add* time. Running it twice yields the same expiry as running it once, so concurrent or back-to-back renewals can never compound the lease. Together: short lease (fast crash detection) + heartbeat (lets live work run arbitrarily long) = automatic recovery from worker death with no double-execution. Backed by `claim_next_run()` + `FOR UPDATE SKIP LOCKED`, which lets many workers poll the queue without colliding. **Framework neutrality** — the user's agent framework (native loop, LangGraph, CrewAI) is a pluggable step-executor behind a common adapter, not baked into the core engine. Lets us ride every framework wave without a rewrite, is a real selling point to power users who already have framework code, and forces a clean separation between the durable engine we own and the agent logic that is swappable. **Native executor** — a minimal in-house agent loop (`prompt → LLM → tool → repeat`) with no hidden state. Built **first** because Phase 1 proves *durability*, not intelligence: with a trivial executor, any resume/checkpoint bug is unambiguously ours, not a framework's. Frameworks (with their own in-process state models) are integrated later, once durable resume is proven. **Egress** — data leaving our cloud out to the internet, which the cloud provider bills for (inbound is typically free). Relevant to live monitoring: streaming logs and especially the live browser view continuously push frames *out* to watching users, so egress scales with how many users actively watch runs and for how long. Favors lighter live-view encodings. **KMS (Key Management Service)** — a managed cloud service (AWS/GCP KMS) that stores and controls encryption keys so we never handle raw key material. User secrets (LLM keys, integration creds) are protected with **envelope encryption**: a KMS master key encrypts a per-secret data key, which encrypts the actual secret. A stolen database yields only ciphertext; every decryption is audited, and plaintext exists only briefly inside the sandbox for the step that needs it. **RLS (Row-Level Security)** — a Postgres feature (used heavily via Supabase) that enforces *"you can only see/touch your own rows"* **inside the database**, not just in app code. Policies key off the authenticated user id so even a buggy query (a missing `WHERE user_id = ...`) cannot cross tenant boundaries. Applied to every user-owned table as defense-in-depth for multi-tenancy; see `0002_rls.sql`. **Browserbase** — a paid managed headless-browser service (hosted Chromium + CDP + live view + session replay), billed roughly per browser-session-time. Used in MVP behind a `BrowserProvider` interface because live-view and replay are hard to build and a solo dev shouldn't run a Chromium fleet. Likely the #1 cost driver around ~1k users — the trigger to evaluate self-hosting; per-run browser-minute budgets guard against runaway bills.











