Tweet fijado
toritonga
9.7K posts

toritonga
@toritonga
steamゲーやらスマホゲーやらを軸にオーディオや古書・骨董品、模型作りまで幅広く展開(着想から一年手付かず←)する事実上の無職なのでよろしくです♪ アニメ等の二次元全般・デジタル機器愛してる(断言)
Se unió Temmuz 2017
429 Siguiendo394 Seguidores

toritonga retuiteado

toritonga retuiteado

速すぎ
中国のAIチップ市場で国産勢が4割超を獲得、NVIDIAのシェア後退 | TECH+(テックプラス) news.mynavi.jp/techplus/artic…
日本語
toritonga retuiteado

Jamie Dimon warns private credit losses will be larger than feared ft.trib.al/lzBFTyn
English
toritonga retuiteado
toritonga retuiteado

toritonga retuiteado

DeepSeek の次の AI の動きが
グローバルなチップ競争を再構築する可能性
The Information
First Squawk@FirstSquawk
DeepSeek’s next AI move could reshape the global chip race - The Information
日本語
toritonga retuiteado

「つまんない株」が「群れ」に勝つ
イギリス株の話ですが、FTSE100構成銘柄のうち、フィナンシャルタイムズに取り上げられる回数が少なかった20銘柄をピックアップしたインデックスが、FTSE100をアウトパフォームした、という話
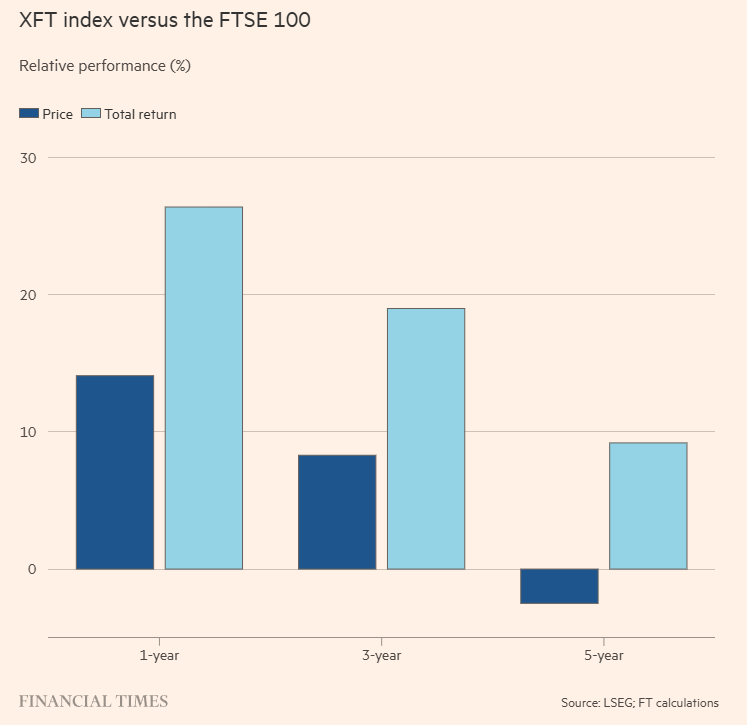
Financial Times@FT
Boring stocks are still beating the herd ft.trib.al/nrx6cvZ | opinion
日本語
toritonga retuiteado
市場を支えている石油備蓄が尽きかけている
IEAが市場に放出した4億バレルの石油は
わずか20日間しか持たないと述べられている
ブルームバーグ
GBX@GBX_Press
🚨 BREAKING Bloomberg: Oil reserves keeping the markets afloat are about to run out. It is stated that the 400 million barrels of oil released into the market by the IEA will only last for 20 days.
日本語
toritonga retuiteado

toritonga retuiteado

Google DeepMindの研究者らによるSSRN(※)論文。
「AIエージェントは、ネット上の情報そのものにだまされたり操られたりする危険がある」ことを改めて警告しています。
攻撃の種類は大まかに6つ。
①人には見えない命令を埋め込む攻撃
②推論をゆがめる表現の仕込み
③RAGやメモリの汚染
④行動の乗っ取り
⑤複数AIの集団的な暴走
⑥人間の確認ミスを誘う攻撃
こうしたAIエージェントをだます悪い仕掛けを全般的に「AI Agent Traps」と呼んでおり、
・エージェントが読む情報
・考える過程
・記憶
・行動
・複数エージェントの相互作用
・人間の監督者
など、いろいろな段階で攻撃されうると指摘しています。
攻撃者がAI本体を直接壊さなくても、Webページや画像、文書、外部知識ベースなどに細工を入れるだけで、AIに誤った判断をさせたり、秘密情報を漏らさせたり、不正な行動を取らせたりできる、という点が強調されています。
そのため「AIエージェントが普及するなら、モデル性能だけでなく、外部環境からの操作にどう耐えるかが安全性の中心課題になる」という結論。
(※)SSRN・・・エルゼビア社が運営する、社会科学や人文科学分野を中心としたプレプリントサーバー

日本語
toritonga retuiteado

CREO QUE ALGUIEN SERÁ DESPEDIDO
El gobierno de Indonesia hizo el ridículo total. Le dieron clasificación para mayores de 3 años a la novela visual Nukutashi, mientras que al juego de Uma Musume le clavaron el +18.
La incompetencia en su máximo esplendor.


Español
toritonga retuiteado

村田製作所、不正アクセスで情報流出-顧客や取引先、従業員 bloomberg.com/jp/news/articl…
日本語
toritonga retuiteado

toritonga retuiteado

注射1回で「脳内のごみ」大掃除に成功 米大学がアルツハイマー病の新治療をScienceで発表 マウスで実証
itmedia.co.jp/news/articles/…
日本語
toritonga retuiteado

🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.

English
toritonga retuiteado
OpenAI:
COOが役職を離れ
AGI部門のCEOが医療休暇を取得
※AGI(汎用人工知能:Artificial General Intelligence)
zerohedge@zerohedge
OPENAI COO SHIFTS OUT OF ROLE, AGI CEO TAKING MEDICAL LEAVE
日本語
toritonga retuiteado

【フォロー&RPキャンペーン】
抽選で1名の方に、レイニー役・上間江望さんのサイン色紙をプレゼント!🎁
◆参加方法
①@EXILIUMJPをフォロー
②この投稿をリポスト
◆締め切り 4月10日(金)23:59迄
※当選者へは当アカウントよりDMにてご連絡します
#ドールズフロントライン2
#ドルフロ2

日本語
toritonga retuiteado

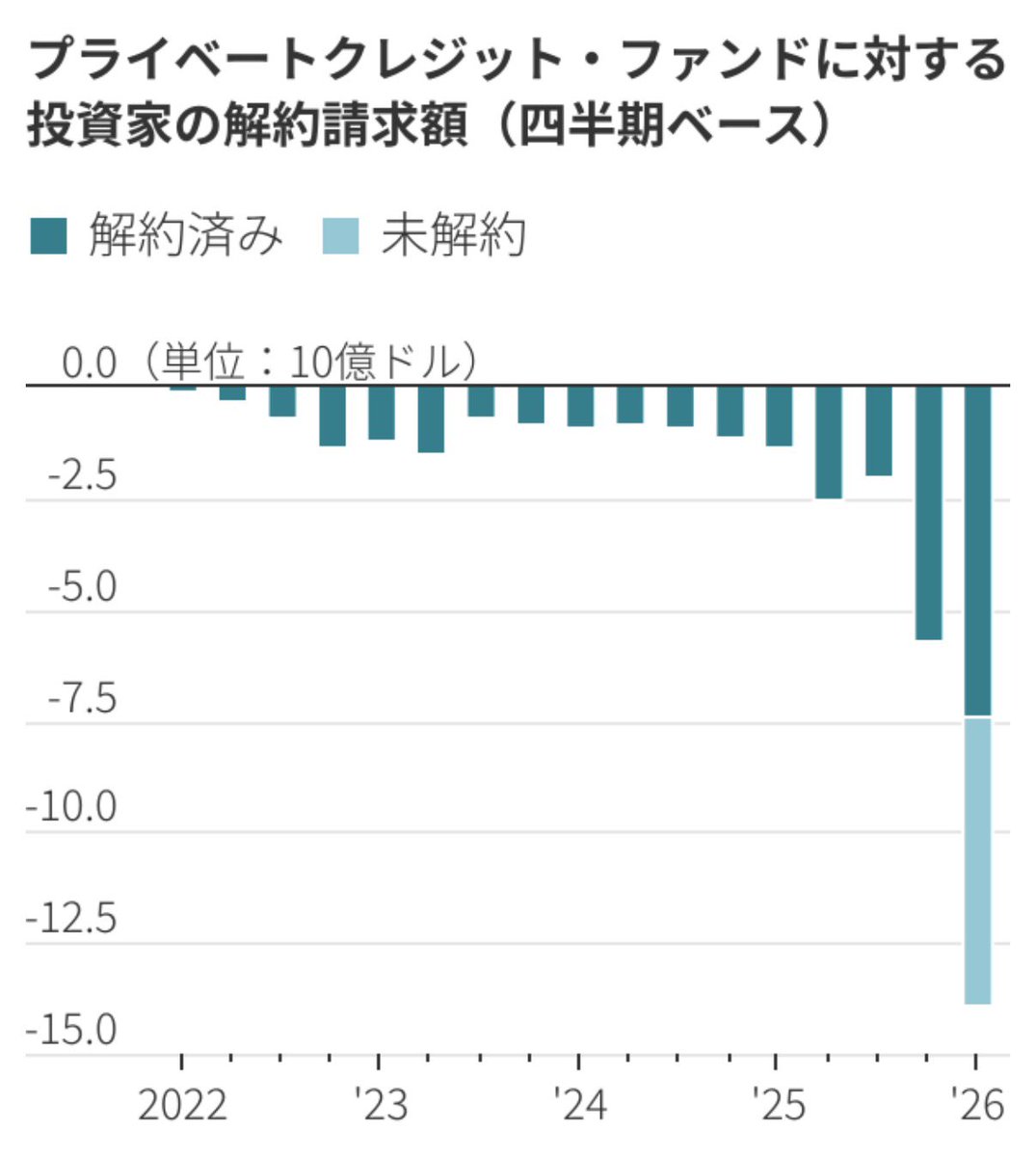
プライベートクレジットから投資家が雪崩を打って逃げ出しています。解約請求してるのに、払い戻せず未解約も急増中。
>プライベートクレジット問題をそもそも論から解説しました。 youtu.be/QVCJeikB9sU?si…

YouTube
日本語
toritonga retuiteado

不可視文字でマルウエア混入 GitHubなどで汚染拡大、開発基盤の信頼揺らぐ xtech.nikkei.com/atcl/nxt/colum…
日本語