
Tweet épinglé

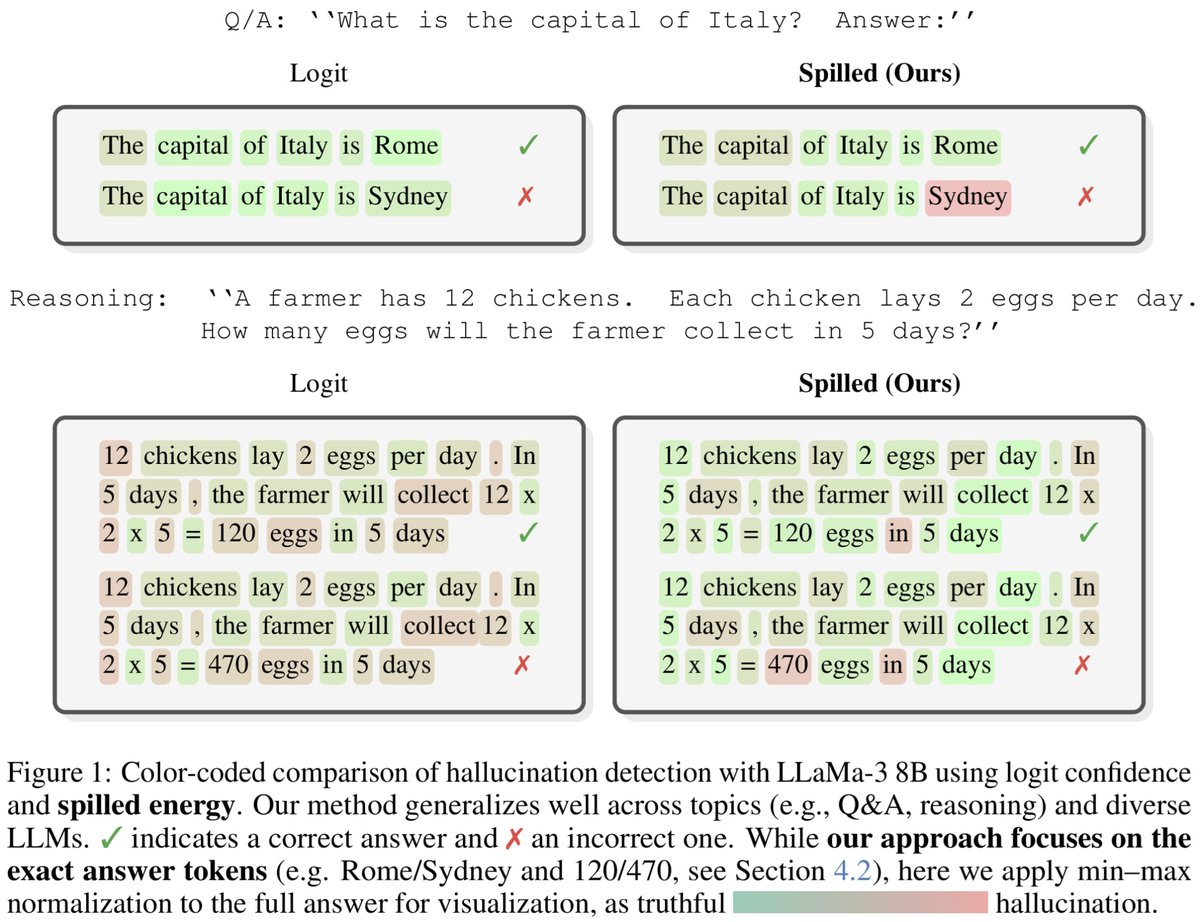
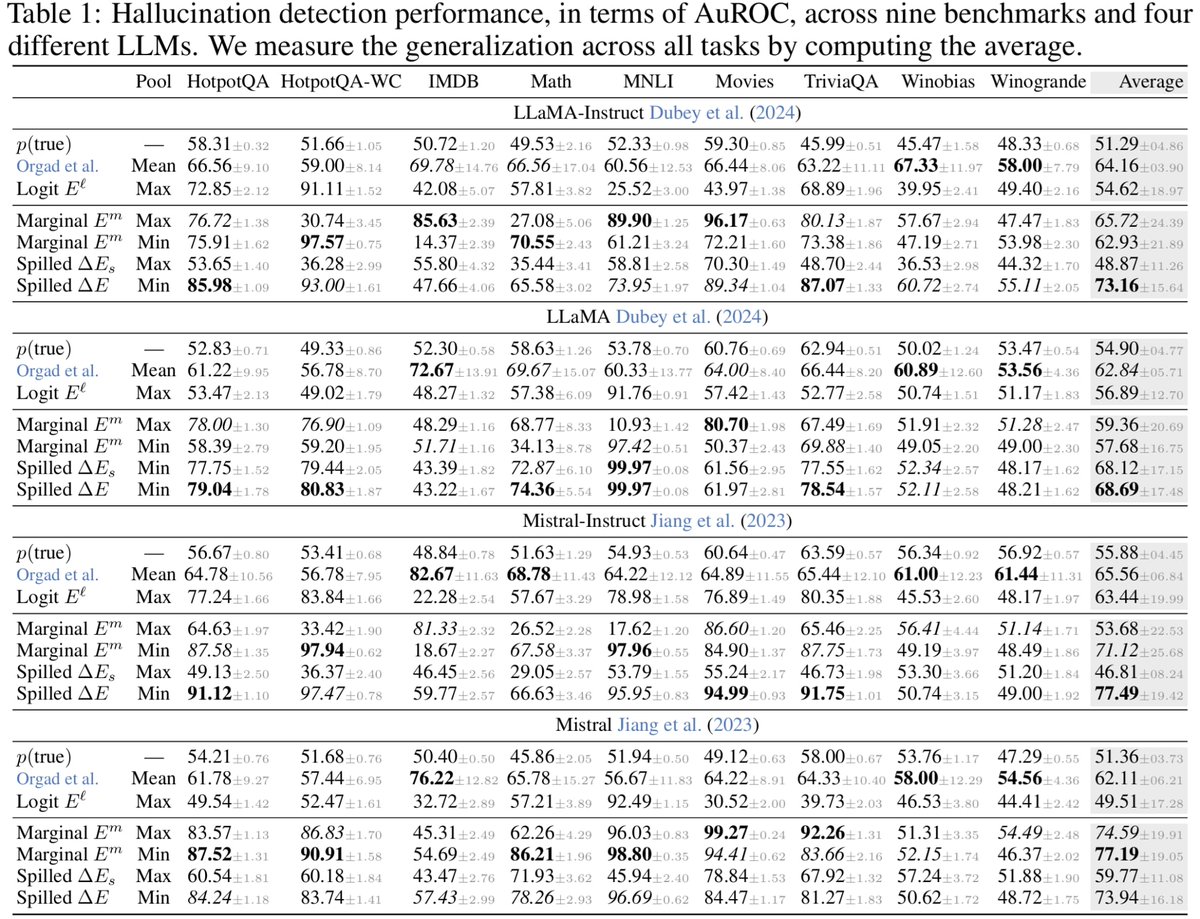
1/ Large Language Models leak energy when they hallucinate. We built a training-free method to catch the spill and keep them *grounded*.
Our #ICLR2026 paper introduces Spilled Energy for SOTA zero-shot detection.
TLDR: Hallucinations violate the probability chain rule.
English















