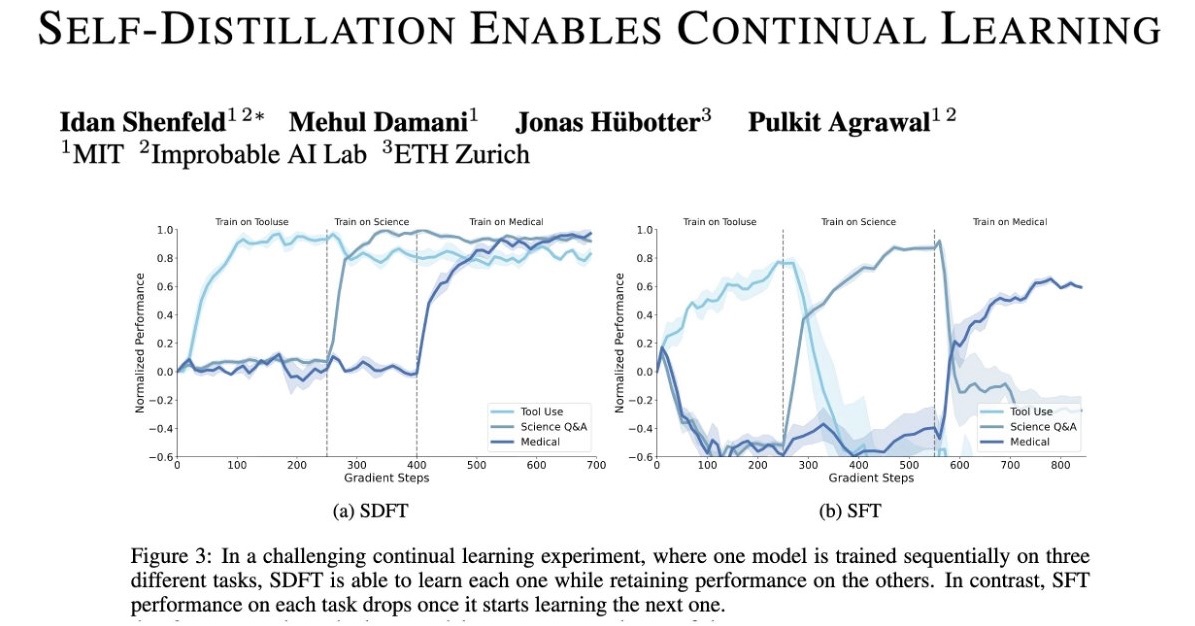
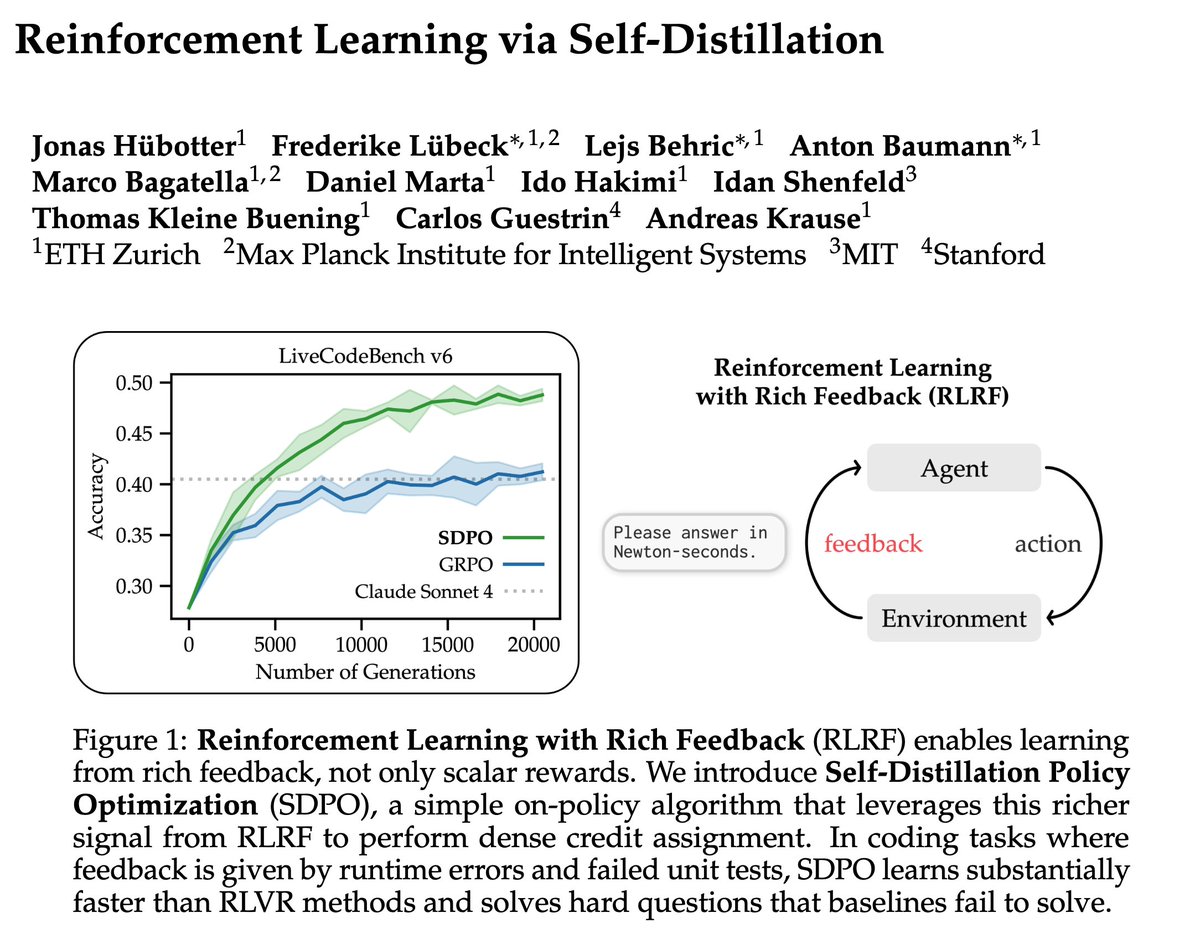
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works. I asked him if I could record it on my iPhone. The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory. So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made. Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required. The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.