Tweet épinglé

Grok 4.20 was the most complex training run yet. We optimized for the highest intelligence density at each step without trading off real world usability through a novel recipe. More improvements and evals to come as the beta matures 🚀
Arena.ai@arena
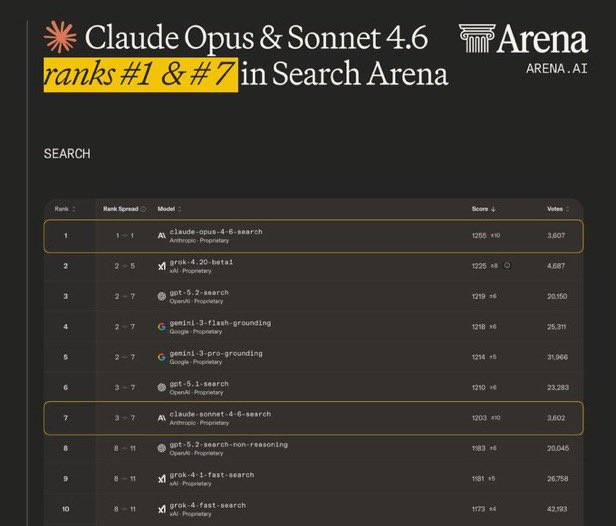
Grok 4.20 beta1 (single agent) debuts #1 on Search Arena, and #4 overall in Text Arena! Highlights: - #1 in Search, scoring 1226, leading GPT-5.2 and Gemini-3 - #4 in Text, scoring 1492 on par with Gemini 3.1 Pro Congrats to the @xAI team and @elonmusk on this impressive milestone!
English