image72
815 posts

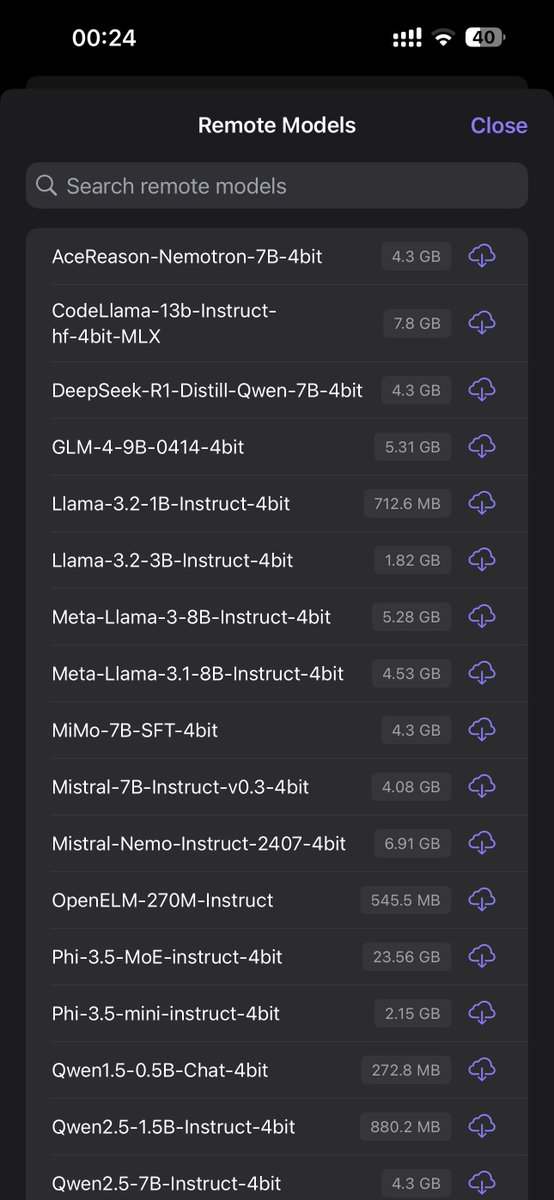
给各位老师汇报一下,m5 48g mbp 跑 31b 还是有点吃力,冷启动要等3分钟,然后回答平均在 1 分钟左右,我现在换回 26b 了,响应速度快很多,风扇也不像 31b 那样狂转,使用下来效果还可以。和在线模型还是不能比,但本地搞搞简单任务还是够够的。
后悔笔记本内存买小了😅
openclaw不知道是什么问题,连接ollama的gemma模型连不上,有没有搞通的,来给我指导下呀🫡
0x卡卡撸特@0xkakarot888
中文


法国表示“震惊”获悉法籍毒贩陈森被囚禁20年后在广州被处决,中国驻法使馆称“打击毒品犯罪是各国共同责任”。 bbc.in/4cco0Kv
中文

@pmamtraveller 오른쪽 아래에 한글 안보이나.. 동아시아에서 니들 못지않게 오래된 나라야. 서로 오랜시간 영향을 받았으니 비슷한 문화를 가지기도 하고 그러는거겠지. 그럼 케이팝이나 드라마에 영향 받은 너희들한테 도둑이라 하리? 아..저작권 생각없이 카피해가는건 도둑이지. 저 작품은 한국작가분의 그림임.
한국어
@lmstudio hi dude, mlx-vlm just released v0.4.4, LM Studio MLX v1.50 only support mlx-lm 0.4.3; x.com/Prince_Canuma/… Gemma 4 26B-A4B is now ~2x faster at 375K context with TurboQuant on MLX-VLM v0.4.4
Prince Canuma@Prince_Canuma
Gemma 4 26B-A4B is now ~2x faster at 375K context with TurboQuant on MLX-VLM v0.4.4 🚀 The model's official max context is 262K but I pushed it to 375K anyway. That's roughly 5–6 full novels (the entire LOTR trilogy + The Hobbit). Up to ~20K tokens they're neck and neck, but after that TBQ dominates with ~1GB memory savings. KV savings are modest (4–17%) because only 5/30 layers get compressed. But those 5 layers dominate decode time at long contexts, so the speed gains are massive. Device: M3 Max 96GB
English

Learn more about this model release
x.com/Google/status/…
Google@Google
We just released Gemma 4 — our most intelligent open models to date. Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows. Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓
English
Say hello to Gemma 4 from @GoogleDeepMind 🚀🔥
💎 Comes in 4 sizes: E2B, E4B, 26B A4B, 31B
💎 Supports vision and reasoning
💎 Apache 2.0
💎 Available now in LM Studio
lmstudio.ai/models/gemma-4
English

@JoelDeTeves many thanks bro,
current `qwen3.5-35b-a3b-claude-4.6-opus-reasoning-distilled-i1` pretty good, I will try it later.

English

@image72 I'm using llama.cpp but you will want to look into MLX.
RAM will be tight @ Q4 with unified mem consider offloading some experts to CPU and / or quantizing KV cache.
English
My 2 cents on Qwen3.5 vs Gemma4:
Use Qwen3.5-27B if you have < 24 GB VRAM and need to fit a dense model, I like bartowski IQ4_NL - still my top choice for accuracy at this level, makes for a great agent too
Use 9B if you have 16 GB or less
For MOE / speed, Gemma4-26B-A4B is incredible. IMO it makes better decisions than Qwen3.5-35B-A3B and doesn’t loop. And it’s smaller! Great model for 24 GB cards, feels like the best balance of speed + performance for Hermes Agent
Of course, some people may disagree - always DYOR that’s where the fun is 😎
English

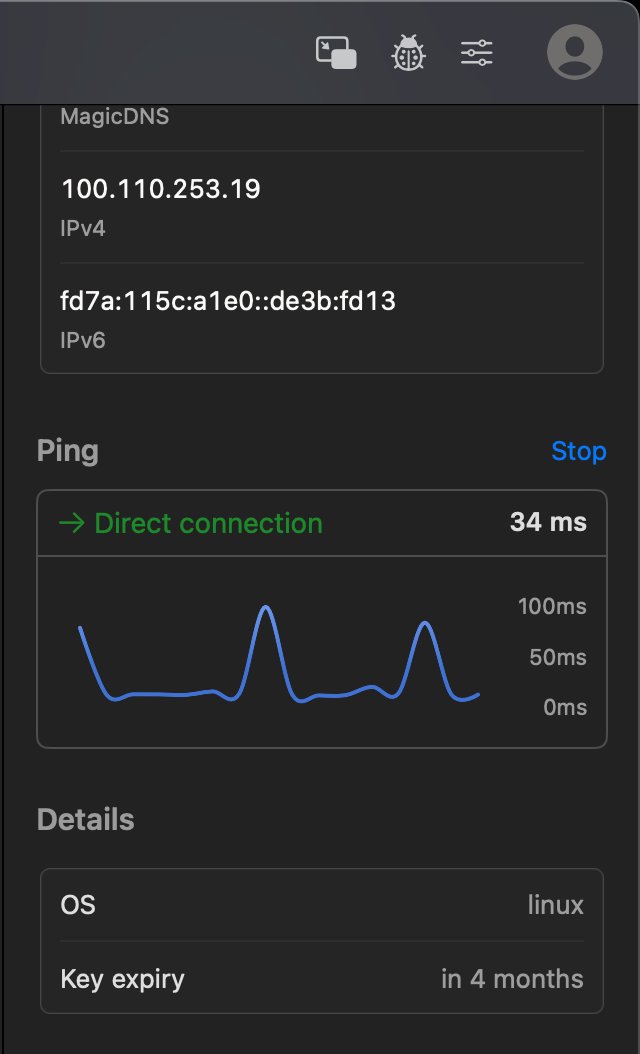
@DearHua2025 @miantiao 家里的联通宽带, 没有IP, ping的这个是aliyun服务器, 想要IP可以另外想办法从cloudflare split tunnel构造局域网, 也非常快
中文



中文