Datou
27.7K posts



首周 20 万收入的话,总收入可能在 50 万到 80 万,四年平均下来年薪 13 万到 20 万,在德国算是高薪了,但是很不稳定。
塔防里加肉鸽这件事,从好评率来看是成了,我也买个玩玩支持一下。
泥伏雷闯关记@Nicole_yang88
一周净赚超 600 万,独立开发者当场落泪 由独立开发者 Cakez 历时 4 年打造的像素塔防游戏《Tangy TD》,在 Steam 上拿下 89% 好评。 上线仅一周:售出 28,078 份,净收入达 197,847 美元(约合新台币 600 多万元)。 当他打开后台看到数据的那一刻,情绪瞬间崩溃,当场落泪;一旁的妻子也激动欢呼,两人紧紧相拥。 这是一次典型的独立开发者逆袭——没有团队,没有资本,只有时间、坚持,以及一点点运气。
中文



工作做不完是因为自我剥削,完全可以按照以前的工作量工作,而不是按以前和工具的交互频率工作,等待工具干活的时候可以做做拉伸看看书,维护保养一下自己。
即刻精选@jike_collection
很多人没有意识到,工作是做不完的,当你通过各种工具提高了效率,并不会真正获得更多自由时间,只会被分配更多工作。 因为本质上市场所购买的是你的时间,至于你在工作时间内能产出多少、市场又能消化多少,并不在考虑范畴内。
中文



我说啥来着,兆瓦闪充对消费者心智的影响远不如外观件,也远不如把原本就含在价格里的配件说成“免费送”。

Datou@Datou
根据我的出片理论,外观占宣传的 64%,内饰占 16%,藏在壳子里面的技术不能出片,再怎么宣传也是只占 20%🤪
中文

能用语言描述的知识只是人类全部知识的一个子集,语言模型不会开车,甚至专门开车的模型都没办法像人类一样到处开。
Pure Nomad@realPureNomad
一个比较全面的大模型,完全下载到本地,小的能小到十几个G。你随便问它问题,他全部知道。他会所有人类语言。这就是人类全部知识骨架,或者说是知识 DNA,也就十几个G。
中文
Datou रीट्वीट किया

论文来了。名字叫 MSA,Memory Sparse Attention。
一句话说清楚它是什么:
让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。
过去的方案为什么不行?
RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。
线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。
MSA 的思路完全不同:
→ 不压缩,不外挂,而是让模型学会「挑重点看」
核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。
→ 模型知道「这段记忆来自哪、什么时候的」
用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。
→ 碎片化的信息也能串起来推理
Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。
结果呢?
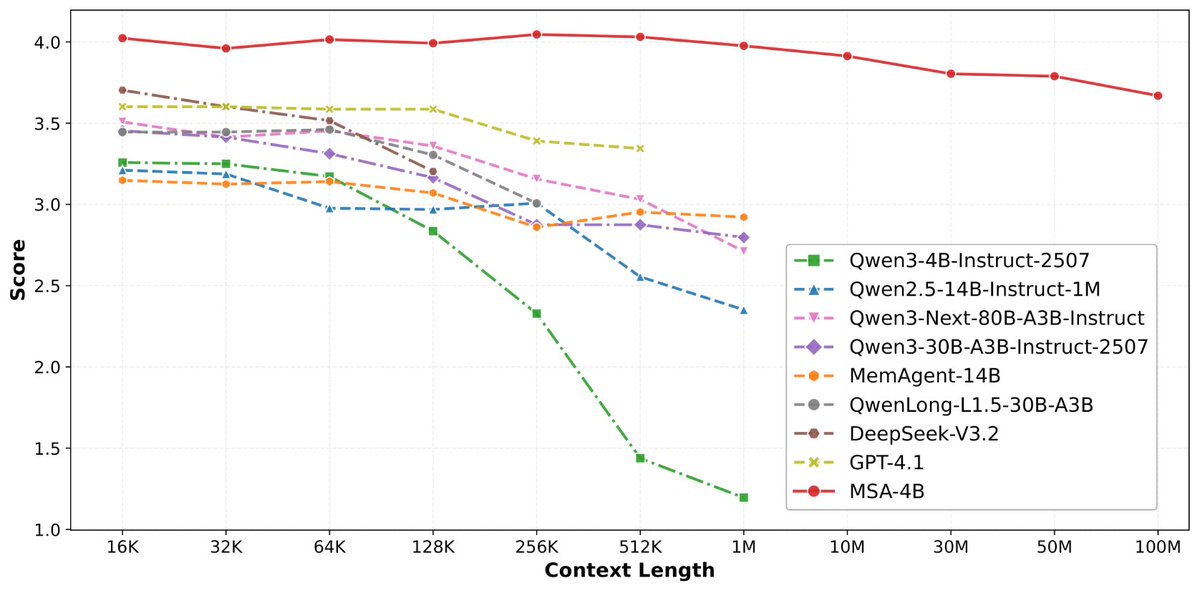
· 从 16K 扩到 1 亿 token,精度衰减不到 9%
· 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统
· 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。
说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。
我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏
github.com/EverMind-AI/MSA
艾略特@elliotchen100
稍微剧透一下,@EverMind 这周还会发一篇高质量论文
中文


不是所有事情都要确定性,也有不少需要能中奖的抽卡
响马@xicilion
在说一个暴论。skills 就是 ai 时代的低代码,看起来很美,但最终还是阶段性产物。确定性流程是自动化的基础,每个环节稳定性 90%,十个环节稳定性就是 34.9%。
中文

你们就说我上年年底买iPhone 17Pro max 2T 是不是明智吧?😎
嘉叔🚀biantai***🈲@hsouncle
你们可能觉得买2T是夸张了,但是一年后这台机就是我的了,2T拿来装Apple Music里的最高码率无损那是很爽的好吧?懂了么?
中文