
Hayato Futami
798 posts
Hayato Futami
@emonosuke
Research engineer at Sony, Speech and language AI. Views are my own.
Tokyo / Kyoto शामिल हुए Ocak 2022
610 फ़ॉलोइंग405 फ़ॉलोवर्स


Hayato Futami रीट्वीट किया

Hayato Futami रीट्वीट किया

I’m excited to share that sarashina2.2-tts, a high-performance Japanese TTS model, has been released!
SB Intuitions@sbintuitions
🚀 sarashina2.2-ttsを公開しました! 日本語に特化したLLMベースの音声合成システムです✨️ 驚くほど自然な表現力と、高い再現性を実現しています。 🇯🇵 高精度 🔊 多彩な表現 🌐 日英対応 ✨ 声質再現 👇 詳細はこちら huggingface.co/sbintuitions/s… #SBIntuitions
English
Hayato Futami रीट्वीट किया
Hayato Futami रीट्वीट किया

Hayato Futami रीट्वीट किया

1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵

English
Hayato Futami रीट्वीट किया


Hayato Futami रीट्वीट किया

最近イベントなどや打ち合わせの場で「ElevenLabsってSTSないの?」と言われる機会も多くなりました。
本noteブログはの質問に対するElevenLabsとしての回答となります。
気になる方はご笑覧ください。
note.com/taka_410/n/nfc…
日本語
Hayato Futami रीट्वीट किया

NLP2026のワークショップで表彰して頂いたLLM-JP-4をベースにした日本語SpeechLLMを公開しました!chatモデルと音声認識モデルを商用利用可能なライセンスで公開しています!!
あゆ@aya172957
NLP2026の第2回「大規模言語モデルのファインチューニング技術と評価」ワークショップにて我々の『合成データを使用した日本語音声LLMの開発』が自由形タスク1位で表彰をいただきました!大規模な計算資源の提供など運営の方々ありがとうございました!
日本語
Hayato Futami रीट्वीट किया

Hayato Futami रीट्वीट किया

The most accurate model across 25 languages, faster transcription speeds, and stronger performance in real‑world noise. MAI‑Transcribe‑1 sets a new bar for speech recognition. Learn more + try it today: msft.it/6019QLa8B

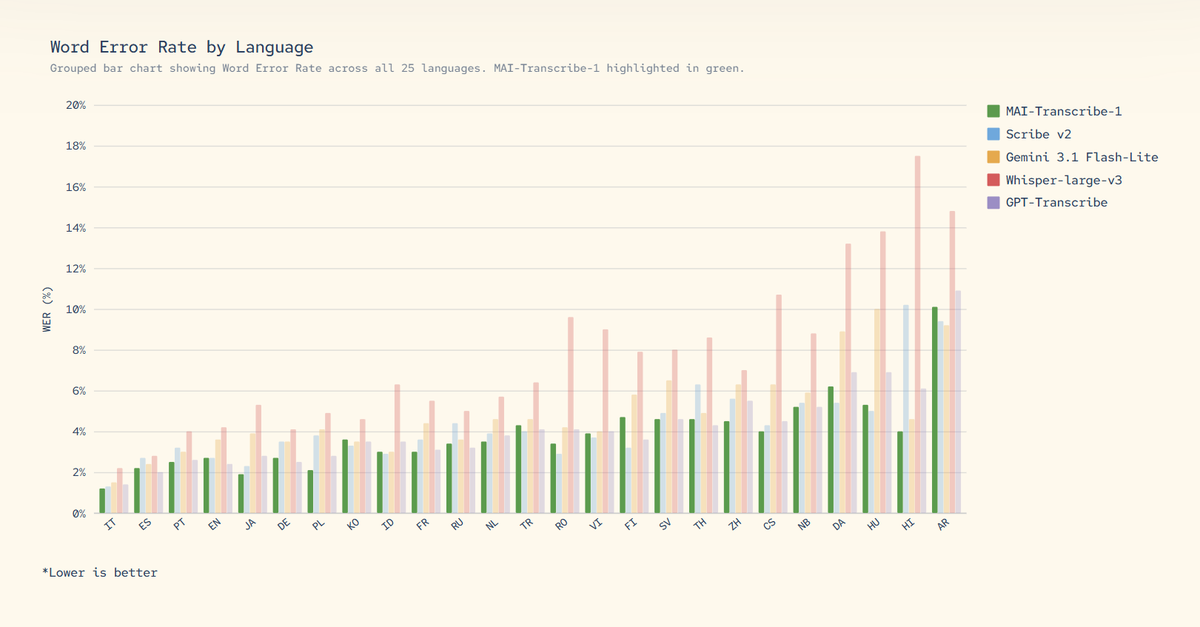
English
Hayato Futami रीट्वीट किया

Gemma 4
Google DeepMind のマルチモーダルモデル。Apache 2.0。パラメータ数あたりの知能がかつてないほどに高い。Effective 2B、4B、26B MoE、31B の 4 種類。画像、動画、音声入力に対応。Context Window は 128k~256k。140 言語以上に対応。Hugging Face などで。
blog.google/innovation-and…
日本語
Hayato Futami रीट्वीट किया

HF audio team member here 👋🤗
Don’t want to be the party pooper here, but those look a little… questionable 🙊 Would love to be proven wrong though, @WillowVoiceAI what about adding the model to the leaderboard?
BTW We’re working on private test sets for the Open ASR Leaderboard to address this tipe of questions, but here, the model is the closest you can get (understandable ofc since your product is built on it)
Willow@WillowVoiceAI
Most models score 5-7% word error rate on clean audio. In real-world conditions they fall to 10-15%. Atlas 1 holds at 1.2% on clean audio and 2.1% in production. The gap widens in noisy environments.
English
Hayato Futami रीट्वीट किया
