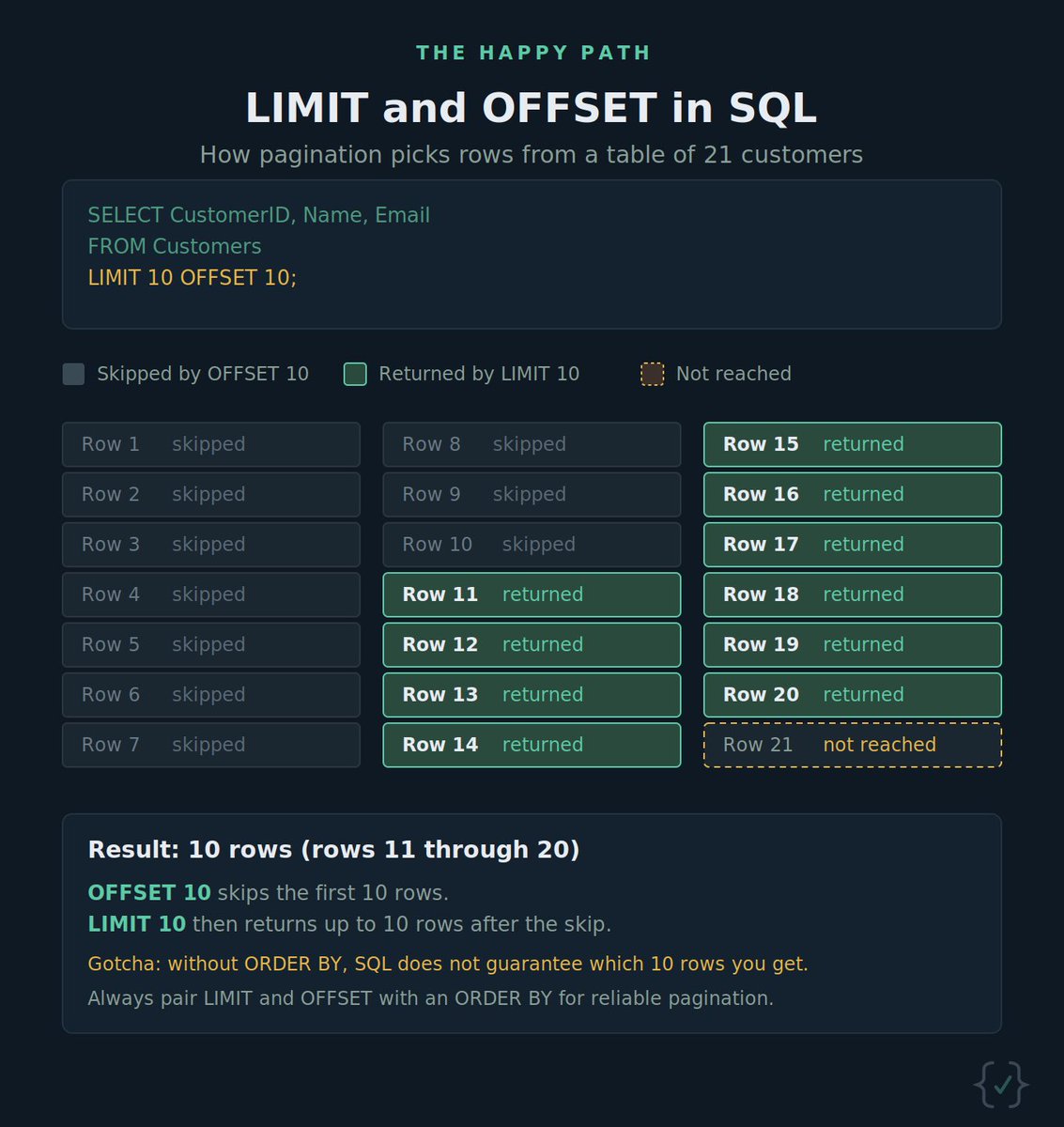
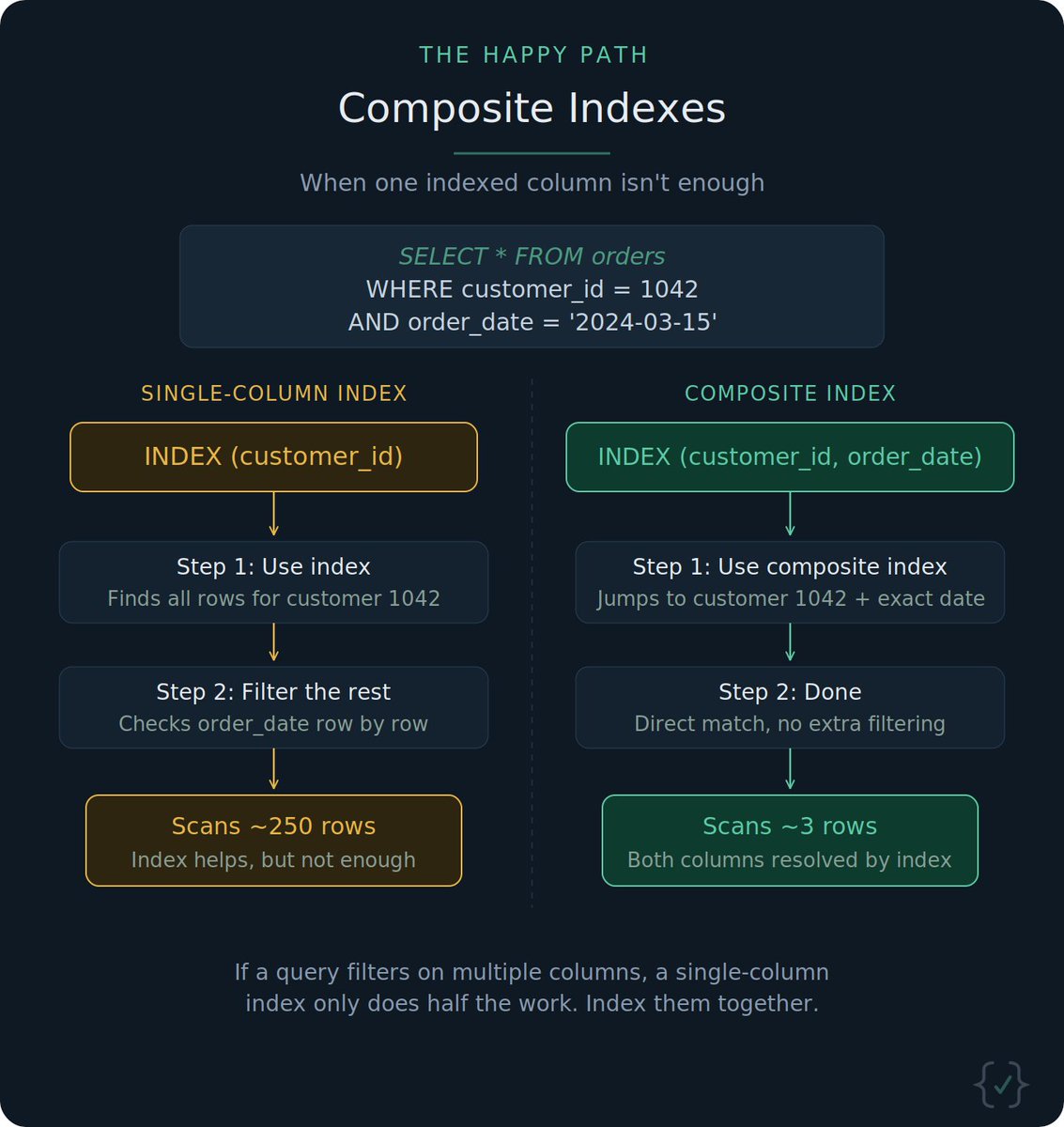
Tweet Disematkan

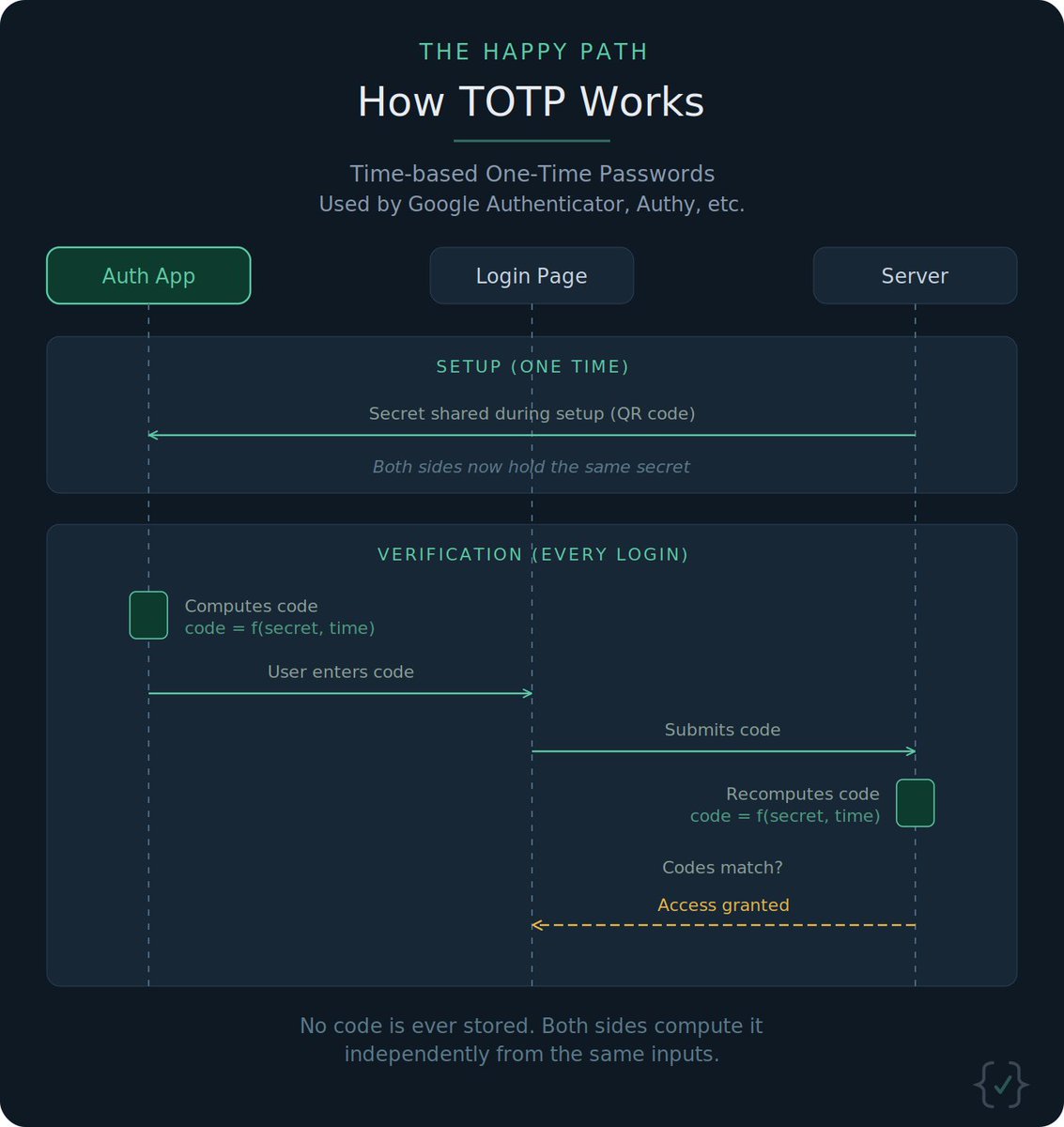
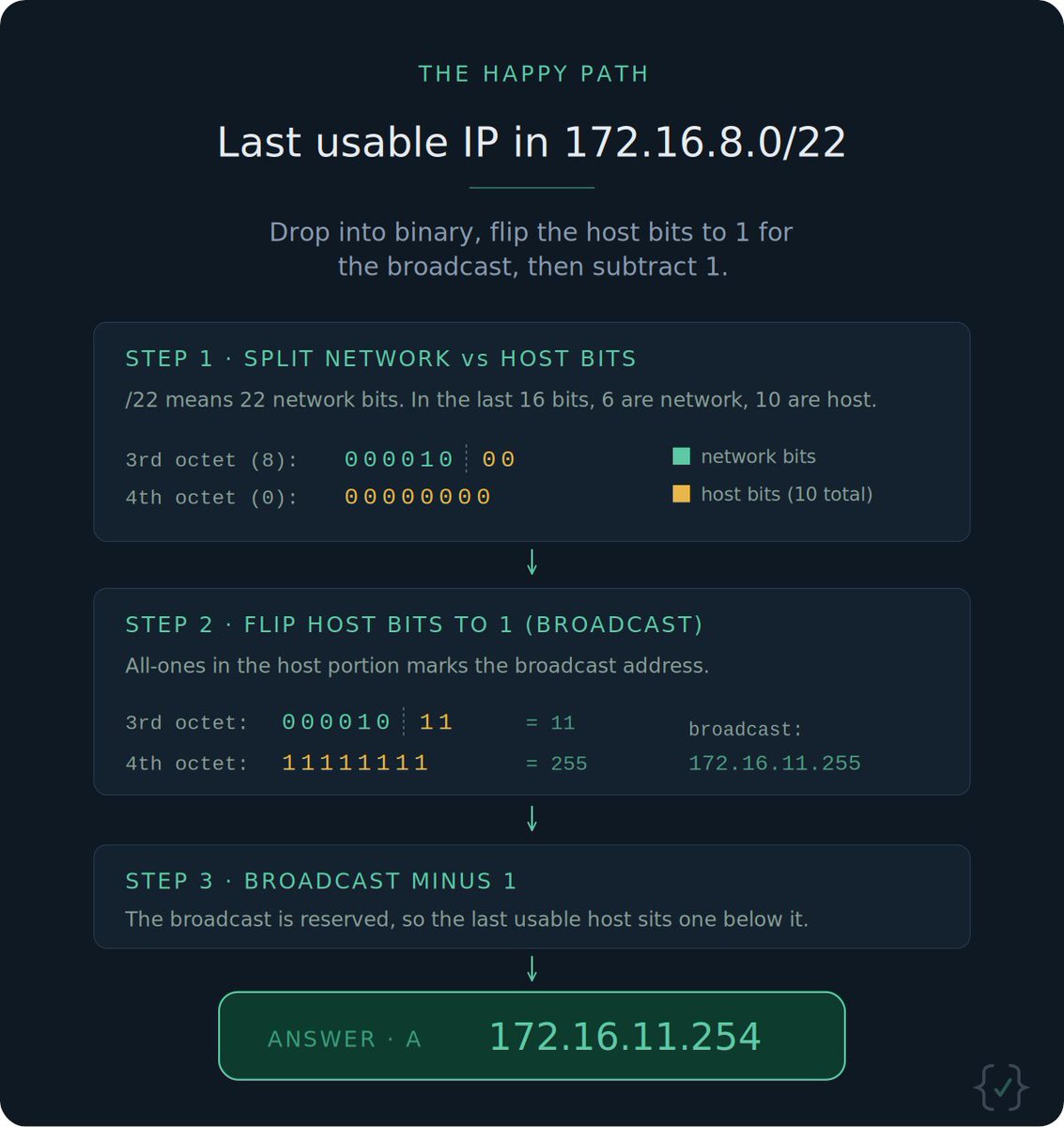
Every web request passes through invisible infrastructure before it reaches a server. Reverse proxies, load balancers, API gateways, session management: all sitting in between.
Here's the full series breaking down that middle layer, one concept at a time. 🧵
English