Tweet Disematkan

Is dataset debiasing the right path to robust models?
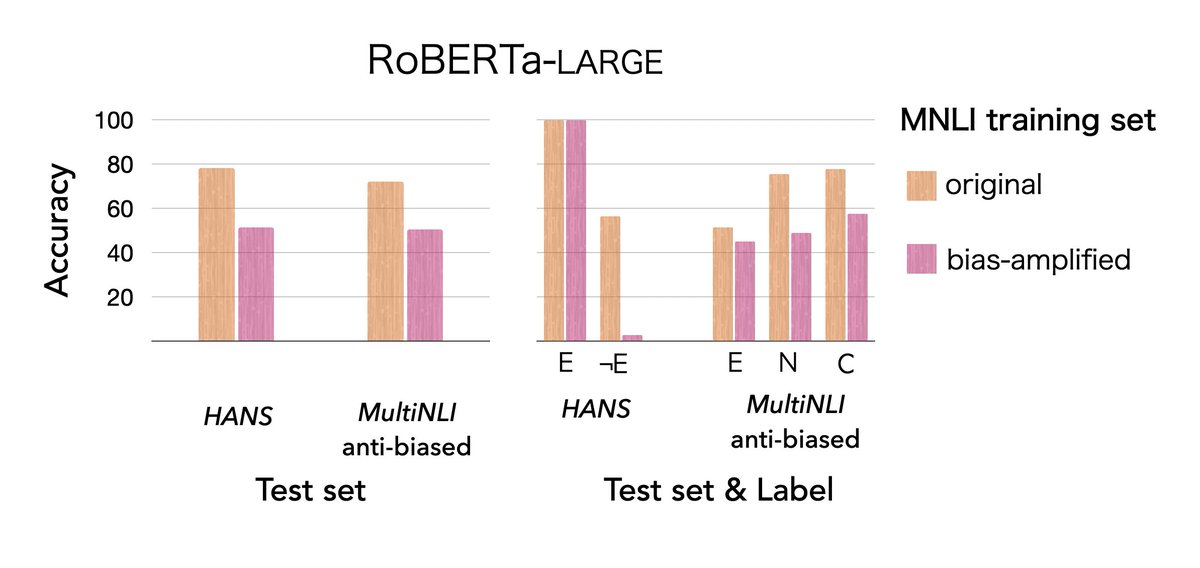
In our work, “Fighting Bias with Bias”, we argue that in order to promote model robustness, we should in fact amplify biases in training sets.
w/ @royschwartzNLP
In #ACL2023NLP Findings
Paper: arxiv.org/abs/2305.18917
🧵👇

English