Tweet Disematkan
北火
5.7K posts

北火 me-retweet

想起四年前喝茶的经历。当时我爱囤书,写了爬虫 bookhubter 去盗版书网站下载去重了 12 万本 EPUB,并且把当时的 Anna Archive 里面的中文书都囊括了。
然后我搭建了一个电子书网站供别人免费下载。因为幼稚言论被国安顶上,然后以盗版书为由联合执法。
万幸没有盈利,否则最后不是罚一万块了事。

中文



所有人现在立刻把这个文件发给Claude然后你会感谢我
…只是想试着这么说ww
但是真的很好用就是了。
claude.ai/public/artifac…
中文

换个角度来说,SaaS 全称 software as a service,这里的价值是 service,不是 software。所以即使有了 AI 写 software,也不代表你有价值。
AI 小子们,没前途。
北火@beihuo
如果用户可以使用 AI 来访问你的软件的数据库,那么还需要你的软件吗? 一些 SaaS 的主要功能就是方便用户操作数据。这些 SaaS 会被 Agent 取代。
中文

关于 spec,rule 和 skill 的那一段写得非常不错。打算借鉴一下,看看是不是可以给团队做一个规范。
yousa@y0usali
为什么 AI 写代码更快但交付没变,以及我怎么把它扳回来的 yousali.com/posts/20260303…
中文

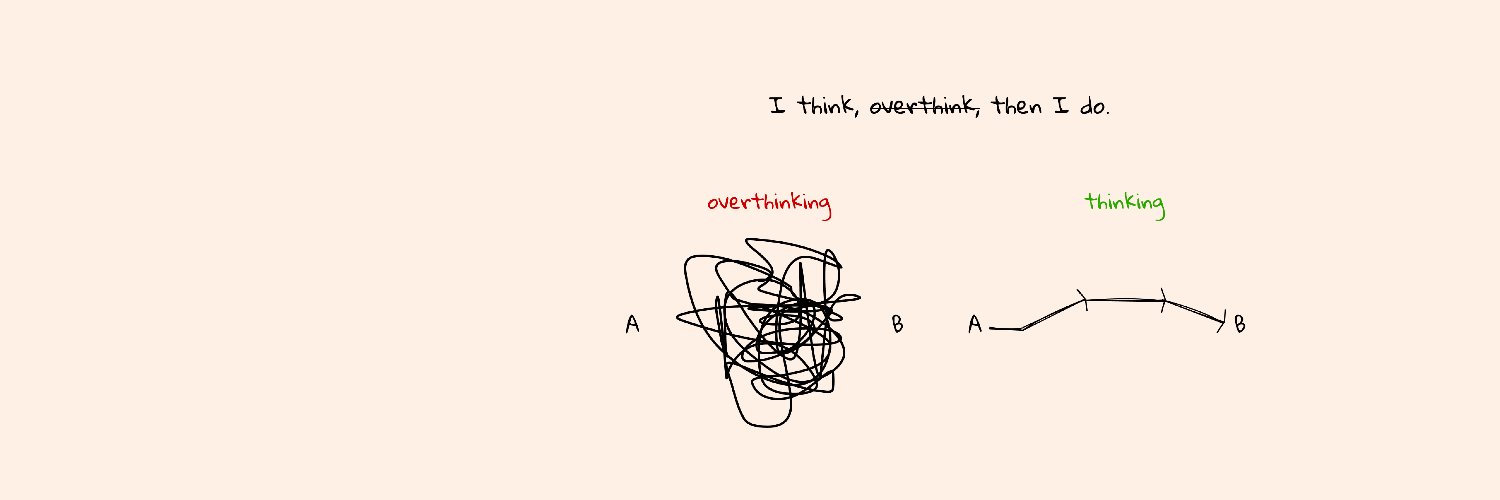
贡献一点点经验:记忆要和用户对话。
再好的记忆系统,上下文也不过是用户思维的降维投影。不同记录之间看似矛盾,但回到用户的维度,往往可以被解释。
问题在于,目前的记忆管理方案只是把上下文当流水账处理。这时候再用模型压缩一遍,得到的还是流水账。就像读完一个人从小到大所有的作文,你仍旧不认识他。
文中的例子很典型:用户说自己吃素,又说喜欢牛排。算法只能猜,而猜测总有失败的概率。
但换一个小孩来,她听到这两件事会怎么做?她会直接问你。
就这么简单。那些绕弯的算法,有多少是内耗呢?
卡比卡比@jakevin7
中文
是的,看同事拆分出来几十个 skills 和 cursor rules,还有 hooks 触发的很多功能,我从来就是一个 CLAUDE.MD 就开始干活了。因为 Claude 的进步如此之快,很多之前的小技巧都变得不需要了。
Leo@runes_leo
Lance Martin(Anthropic,前 LangChain)这篇值得所有用 Claude 做开发的人读一遍。 核心观点:别为上一代模型的限制做工程设计。很多应用还在把 context 控制在 200K 以内——这些假设正在过时。 三个变化同时发生:窗口扩到 1M、长 context 下的检索和推理能力在持续提升(有 benchmark 数据)、200K 以上的加价取消了。 Claude Code 就是一个"顺着模型进步方向构建"的例子——不做 context 裁剪,直接把所有相关信息塞进去,让模型自己处理。作为每天用 12 小时以上的用户,体感确实如此:context 越长越完整,输出质量越稳定。
中文

一截图就暴露了自己是个智障的事实,此CL不是彼CL啊,把高露洁这个必选消费公司归到油的类别下面,哈哈哈哈哈哈哈,今年看到的最好笑的笑话由你贡献了。说做多CL做多CL,做的尼玛的是高露洁牙膏
qazwsx123@qazwsx126874925
@Areskapitalon 不知道那个小丑跳脸然后单子拿不出来 打开程式截图就能打脸做不到?纯小丑
中文
简单说,纯粹建立在模型智能上的 AI 创业,通常更容易陷入同质化,也更容易受到上游模型厂商挤压;相比之下,扎根具体业务场景、真正解决客户问题的公司,往往更有机会活下来。
Orange AI@oran_ge
这轮 AI 创业无比卷,最大的风险就是来自被模型厂商直接吃掉
中文
沉迷于收集和使用 OpenClaw 的使用技巧是浪费时间,识别和理解底层原理甚至自己写一个,才是正确的学习方法。
北火@beihuo
是的,试图通过设计 context 文件结构以优化 Agent 的记忆,是一个错误的方向。 这些记忆文件如果交给人类管理,它应该是浅显易懂的。换一个方面来讲,如果这些不需要人类管理,你会觉得他们仍旧是我们可理解的文件结构吗? 所以无论怎么想,各种 memory 文件组织技巧,都是错误的投入。
中文