
Christopher C. Cyrus
11 posts

Christopher C. Cyrus
@ccyrus
https://t.co/VJeMJuHtNE
Austin, TX Bergabung Kasım 2022
1.4K Mengikuti75 Pengikut
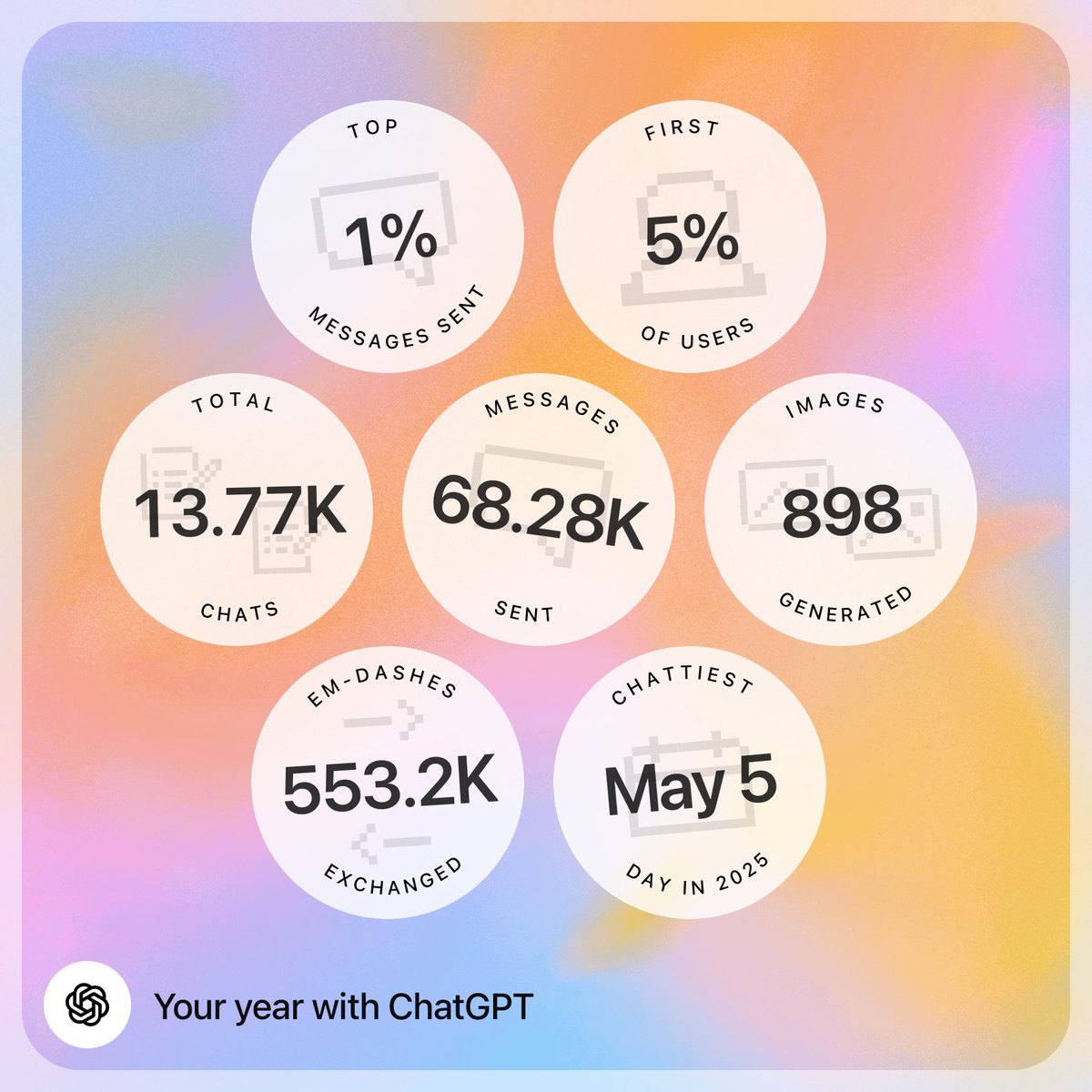


We started internal
testing some big updates to the @GoogleAIStudio experience today!
Coming to you early next year but reply below if you’d like early access in the coming weeks 👀
English


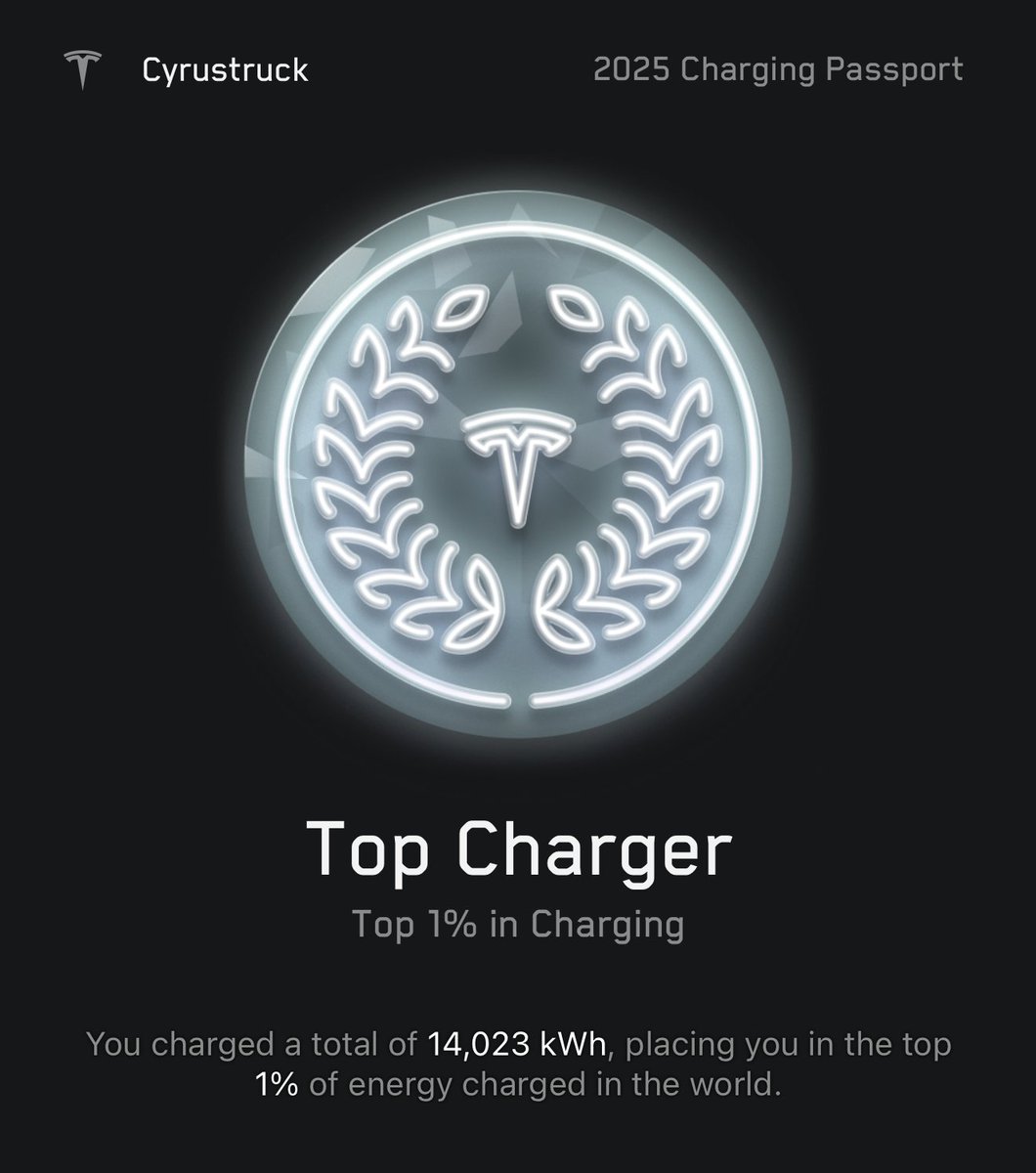

Your charging passport is ready.
Look back at the epic trips you took and the charging milestones you achieved in 2025.
English
Christopher C. Cyrus me-retweet

OpenAI o1-preview and o1-mini are rolling out today in the API for developers on tier 5.
o1-preview has strong reasoning capabilities and broad world knowledge.
o1-mini is faster, 80% cheaper, and competitive with o1-preview at coding tasks.
More in openai.com/index/openai-o….
OpenAI@OpenAI
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. openai.com/index/introduc…
English
Christopher C. Cyrus me-retweet

Chomsky argued that LLMs learned impossible languages as well as possible ones & thus couldn’t tell us useful things about language.
Nope: “Our core finding is that GPT-2 struggles to learn impossible languages when compared to English as a control, challenging the core claim.”



Pascale Fung@pascalefung
We always knew that Chomsky was wrong about language models, it’s nice to have a paper showing you just how wrong he was! #ACL2024 best papsr. arxiv.org/abs/2401.06416
English
Christopher C. Cyrus me-retweet
This is not just true for CS students.
If you want to do research on AI, or figure out how it can be used in your organization, the first step is talk to the models a lot. Use it for everything you do (within legal & ethical bounds). You don’t know what it does until you use it.
Yao Fu@Francis_YAO_
I've been asked by few first year PhD about how to start LLM research on X, say long context modeling. My number one suggestion -- though it seems a bit of unconventional -- is *not* to read any papers related to long-context, but to talk to the model - Talk to the model about a text book, course slides, financial reports, novels, nonfictions, any long document you could find - Talk to the model for two whole weeks, from the morning first thing after opening up the laptop, to the evening last thing before going to the bed. - Ask every single question you could imagine, what is PCA? How does it compare to SVD? Which part of the book describes the two? What the book says exactly? - Talk to all the models you could access, GPT, Gemini, Claude, Llama ... - Keep talking to the model for two whole weeks, no research, no paper, no arxiv, just talk to the model. - During the above process, continuously observe how the model behave, discover their problems, and think about why models could behave that way I found people who have gone through the above process have a fundamentally different level of understanding than people who just read papers 😉
English
Christopher C. Cyrus me-retweet
🚨Our new paper on how instructors can use AI to create research-based experiences that would have been impossible to do before the advent of generative AI.
We also teach how to build them.
Blog on democratizing innovation: oneusefulthing.org/p/innovation-t…
Paper: papers.ssrn.com/sol3/papers.cf…
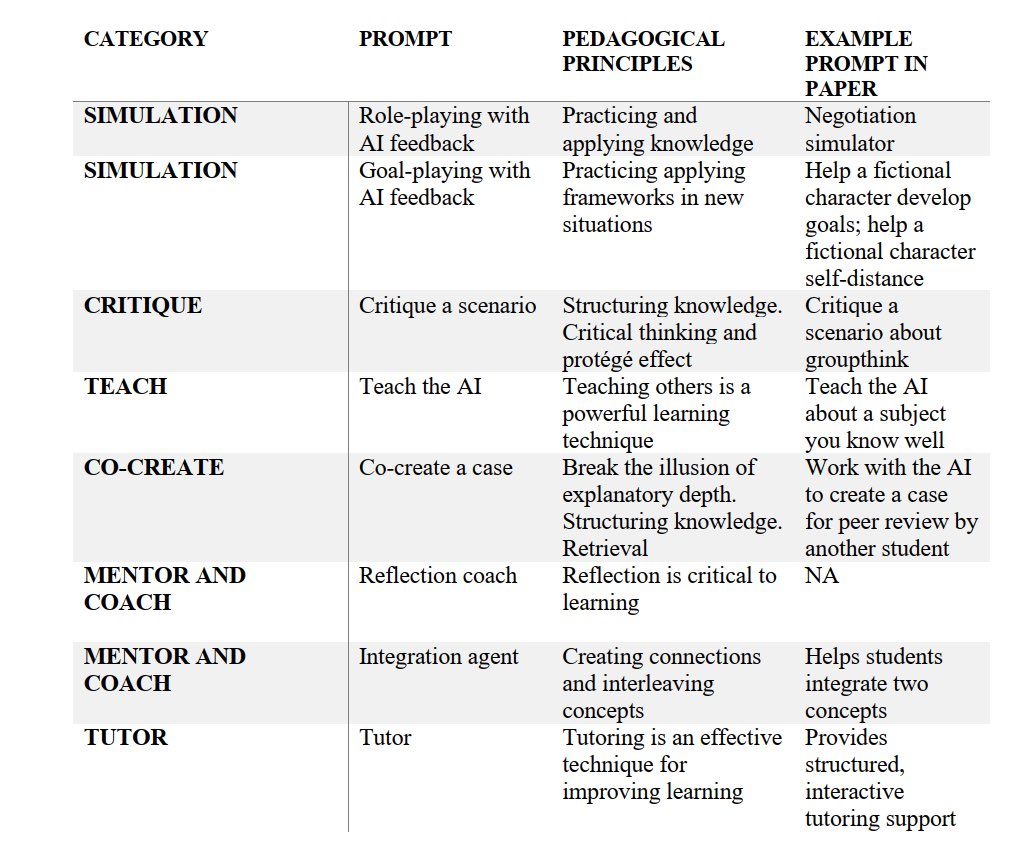


English
Christopher C. Cyrus me-retweet
Introducing a series of updates to the Assistants API 🧵
With the new file search tool, you can quickly integrate knowledge retrieval, now allowing up to 10,000 files per assistant. It works with our new vector store objects for automated file parsing, chunking, and embedding.

English
Christopher C. Cyrus me-retweet
It is weird how effective it is to apply human-inspired approaches to problem solving to help LLMs “think” better.
Here, asking the AI to visualize each step in a navigation problem by drawing diagrams helps greatly improve performance on the problem.

elvis@omarsar0
Visualization-of-Thought Elicits Spatial Reasoning in LLMs Inspired by a human cognitive capacity to imagine unseen worlds, this new work proposes Visualization-of-Thought (VoT) prompting to elicit spatial reasoning in LLMs. VoT enables LLMs to "visualize" their reasoning traces, creating internal mental images, that help to guide subsequent reasoning steps. Think of this prompting approach as a way of eliciting the "mind's eye" of LLMs. When tested on multi-hop spatial reasoning tasks like visual tiling and visual navigation, VoT outperforms existing multimodal LLMs. This is a fascinating paper and makes me wonder whether there are other human cognitive abilities that can inspire even more complex capacities of LLMs and multimodal LLMs.
English
Christopher C. Cyrus me-retweet
The big education crisis caused by AI is not going to be in schools (there was cheating before AI & we can figure out AI uses that boost learning), but after graduation.
White collar work is secretly based on an apprenticeship system that will break
From my book Co-Intelligence




English