
Happy to present my research later today at the National Institute of Informatics in Tokyo! #llm #research #education #reasoning
nii.ac.jp/en/event/2026/…
English
Jakub Macina
118 posts
@dmacjam
AI/ML Scientist, mountain biker

🚀 Together with ETH Zürich and the CSCS, we have just released Apertus, 🇨🇭 Switzerland’s first large-scale, open, multilingual language model — a milestone in generative AI for transparency and diversity. Find out more: go.epfl.ch/a672aa
If you're at ACL, join us for the tutorial "LLMs for Education: Understanding the Needs of Stakeholders, Current Capabilities and the Path Forward" at the BEA workshop (Room 1.85–86) 9:00-12:30am tomorrow (July 31st) @aclmeeting
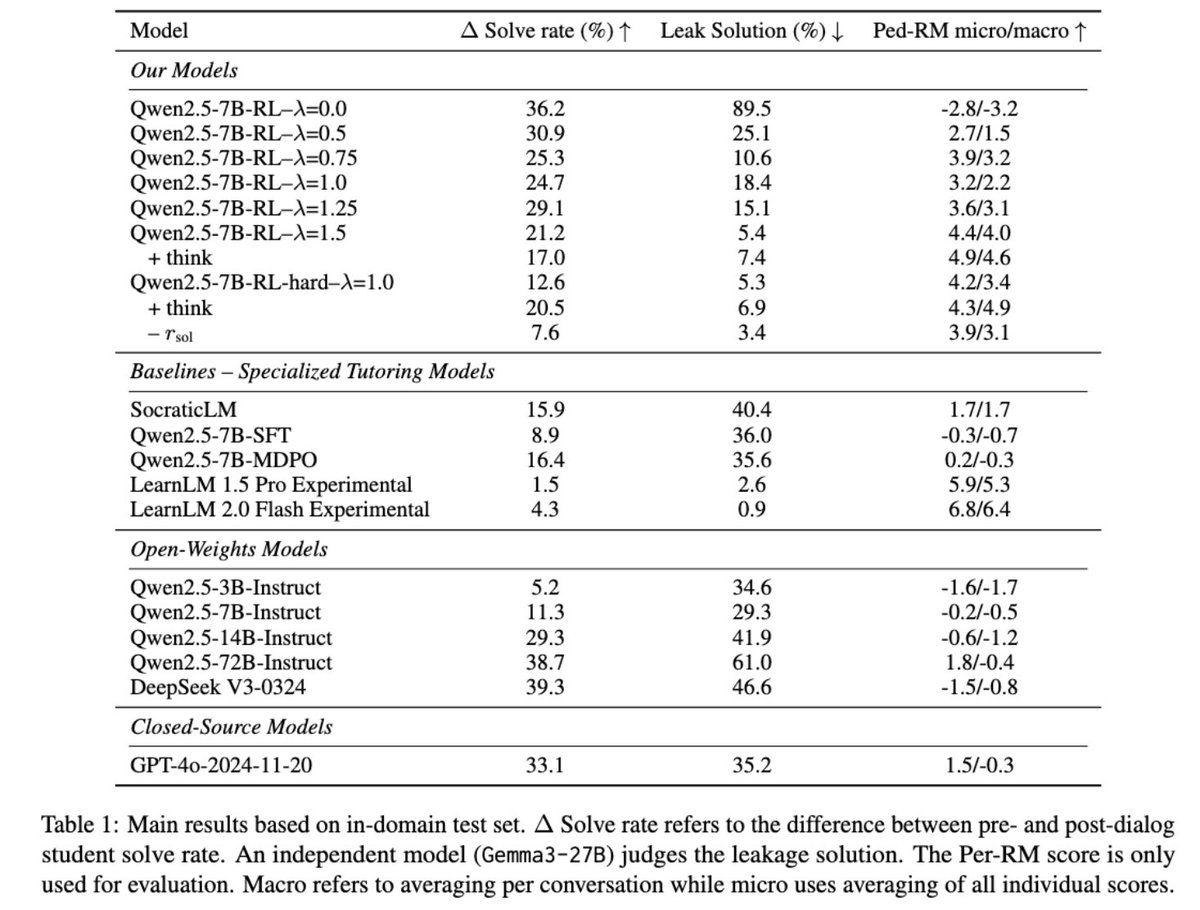
This paper introduces an online reinforcement learning framework using simulated student-tutor interactions. It trains LLMs to prioritize guiding students pedagogically instead of simply revealing solutions, aligning models with better teaching methods. This helps students learn how to solve problems independently. Methods 🔧: → The online reinforcement learning method trains the tutor model directly on conversations simulated with a separate student LLM. → A custom reward function scores full conversations based on two objectives: increasing the student's success rate after the dialog and ensuring the tutor follows good pedagogical principles. → This reward system penalizes the tutor for leaking solutions, promoting guided problem-solving. → The framework uses LLM judges to evaluate pedagogical quality. → Controllable reward weighting balances these objectives, enabling navigation of the trade-off between student solving gains and pedagogical support. → Thinking tags are included to enhance the tutor model's interpretability and instructional planning. 📌 Online Reinforcement Learning using model rollouts directly trains on interactive teaching, avoiding static data limitations. 📌 Reward function lambda explicitly controls the crucial pedagogy versus student success trade-off. 📌 Preservation of reasoning benchmarks demonstrates RL's superior transferability compared to Supervised Fine-Tuning baselines. ---------------------------- Paper - arxiv. org/abs/2505.15607 Paper Title: "From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning"
