Mesh processing techniques are mature, but how can we apply them to non-mesh representations?
Our #Eurographics2026 paper achieves this by learning a representation called “Neural Displacement Fields”! 🧵 (1/n)
Do you want to untangle this knot in just 3 seconds? Sure you do!
In our paper “Medial Sphere Preconditioning for Knot Untangling and Volume-Filling Curves” at #SIGGRAPHAsia2025, we explored how to run these tasks in a fast and robust manner. 🧵 (1/n)
New blog post!
In "Quantizing tangent frames", we look at various established methods to represent tangent frames in the vertex data, squeeze a few variants into 32 bits per vertex and look at the resulting precision.
zeux.io/2026/04/30/qua…
Retweet, like and subscribe!
github.com/iamgio/quarkdo…
A modern Markdown-based typesetting system designed for versatility. It allows a single project to compile seamlessly into a print-ready book, academic paper, knowledge base, or interactive presentation.
Today, we released Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale, from NVIDIA Research.
Generating large-scale, complex environments is difficult for AI models. Current models often “forget” what spaces look like and lose track of movement over time, causing objects to shift, blur, or appear inconsistent. This prevents them from creating the reliable 3D environments required for downstream simulations. Lyra 2.0 solves these issues by:
✅ Maintaining per-frame 3D geometry to retrieve past frames and establish spatial correspondences
✅ Using self-augmented training to correct its own temporal drifting.
Lyra 2.0 turns an image into a 3D world you can walk through, look back, and drop a robot into for real-time rendering, simulation, and immersive applications.
➡️ Learn more: research.nvidia.com/labs/sil/proje…
📄 Read the paper: arxiv.org/abs/2604.13036
And to conclude, this is the first model that hits the four requirements @jon_barron listed in diagram **simultaneously**
No choices to make.
One model to rule them all.
I've recently released the Light Propagation Volumes (custom GI plugin) for #UE5
LPV is an algorithm of resolving the diffuse light bounce from the perspective of the sun in world space (firstly introduced in 2009 by Crytek).
It's non-temporal, performant and lightweight.
Here’s a cool talk from GPC 2025 on the architecture of Blender’s Cycles renderer. There is no one right answer to designing a renderer; as a rendering engineer, I really like seeing how different renderers choose different tradeoffs to meet user needs:
youtu.be/etGMk9wYwNs
This 2 hour lecture by Yann LeCun (Turing Award winner) will teach you why the next trillion dollar AI company won't be built on LLMs.
He trashes the $100 Billion LLM race, attacks Musk and Amodei, declares scaling dead.
Bookmark & watch tonight after work, skip to 7:00.
I spent some time reverse-engineering Apple's Lossy texture format. It wasn't as simple as I originally thought, and some of the details surprised me. Check it out!
ludicon.com/castano/blog/2…
New Paper🙂
Nanite has shown that small triangles can be rendered fast in compute, we're exploring how fast for large meshes with up to 18.9 billion triangles, without the need to precompute LOD structures.
Paper: github.com/m-schuetz/CuRa…
Source: github.com/m-schuetz/CuRa…
Earlier this year Yann LeCun left Meta because Mark Zuckerberg wouldn't bet the company on JEPA. Last week his group dropped the first JEPA that actually trains end-to-end from raw pixels. 15 million parameters. Single GPU. A few hours.
The timing is not a coincidence.
For four years Meta has been the house that JEPA built. LeCun published the original paper from FAIR in 2022. I-JEPA and V-JEPA came out of his lab. The architecture was supposed to be the escape hatch from LLMs, the path to robots that actually learn physics instead of hallucinating about it. Every version shipped fragile. Stop-gradients. Exponential moving averages. Frozen pretrained encoders. Six or seven loss terms that had to be hand-tuned or the model collapsed into garbage representations.
Meta kept funding LLMs. Llama shipped. Llama scaled. Llama got beat by Qwen and DeepSeek. Zuck spent $14 billion to buy ScaleAI and install Alexandr Wang. The FAIR robotics group was dissolved. LeCun's research kept winning papers and losing the product roadmap.
He left, started AMI Labs, and said publicly that LLMs were a dead end.
Now the paper. LeWorldModel. One regularizer replaces the entire pile of heuristics. Project the latent embeddings onto random directions, run a normality test, penalize deviation from Gaussian. The model cannot collapse because collapsed embeddings fail the test by construction. Hyperparameter search went from O(n^6) polynomial to O(log n) logarithmic. Six tunable knobs became one.
The downstream numbers are what should scare the robotics capex class. 200 times fewer tokens per observation than DINO-WM. Planning time drops from 47 seconds to 0.98 seconds per cycle. 48x faster at matching or beating foundation-model performance on Push-T and 3D cube control. The latent space probes cleanly for agent position, block velocity, end-effector pose. It correctly flags physically impossible events as surprising. It learned physics without being told physics existed.
Figure AI is valued at $39 billion. Tesla Optimus is mass-producing. World Labs raised $230 million to sell generative world models. Everyone in humanoid robotics is burning capital on foundation-model pipelines that plan in 47 seconds per cycle.
LeCun's group just showed you can do it with 15 million parameters on a single GPU in a few hours.
This is the Xerox PARC pattern running again. Meta had the next architecture. Meta had the scientist. Meta dissolved the robotics team, passed on the productization, and watched the exit. Three months later the lab that was supposed to be Meta's publishes the result that resets the robotics cost structure.
The paper is worth more than Alexandr Wang.
PyCuSFM: Cuda Accelerated Structure from Motion
This repository provides the official python implementation of cuSFM, a novel CUDA-accelerated Structure-from-Motion framework for reconstructing 3D environmental models from images. Key features include:
-CUDA-accelerated feature extraction, matching, and graph optimization for superior speed and scalability
-Precise and robust camera pose estimation
-Accurate and consistent 3D environment reconstruction with COLMAP-compatible outputs
-Support for any number and type of camera inputs
-Reliable extrinsic calibration for multi-camera setups
-Localization mode for integrating new data into pre-built map
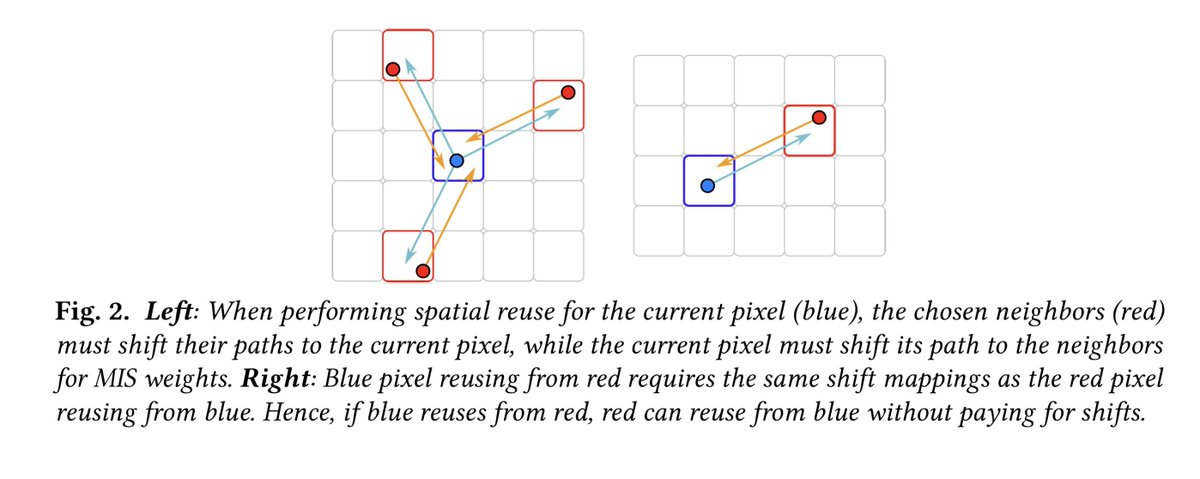
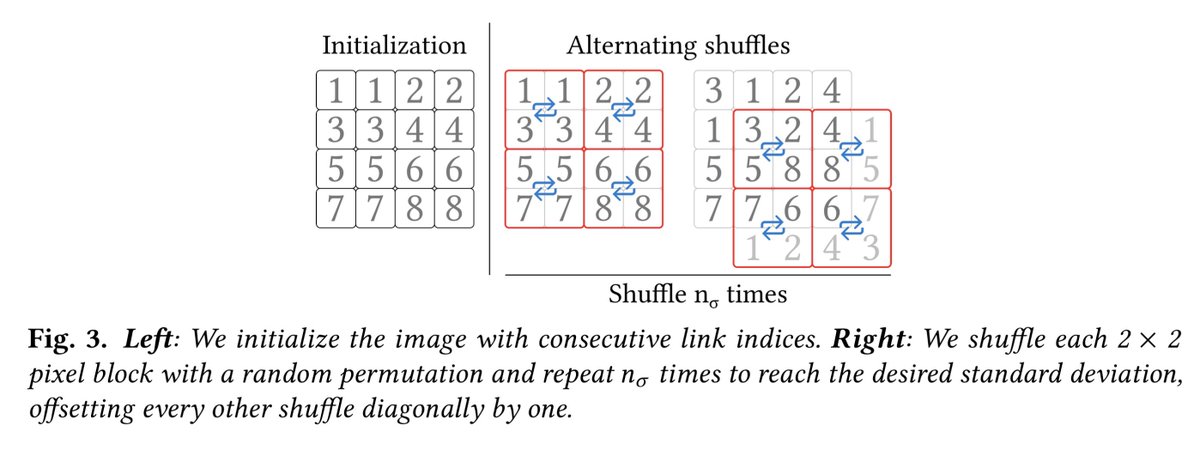
ReSTIR PT Enhanced: Algorithmic Advances for Faster and More Robust ReSTIR Path Tracing
Daqi Lin, Markus Kettunen, Chris Wyman
(Nvidia)
Paper: research.nvidia.com/labs/rtr/publi…
Page: research.nvidia.com/labs/rtr/publi…
Video: research.nvidia.com/labs/rtr/publi…
Supplementary: research.nvidia.com/labs/rtr/publi…

Abstract
Algorithms leveraging ReSTIR-style spatiotemporal reuse have recently proliferated, hugely increasing effective sample count for light transport in real-time ray and path tracers. Many papers have explored novel theoretical improvements, but algorithmic improvements and engineering insights toward optimal implementation have largely been neglected. We demonstrate enhancements to ReSTIR PT that make it 2–3x faster, decrease both visual and numerical error, and improve its robustness, making it closer to production-ready. We halve the spatial reuse cost by reciprocal neighbor selection, robustify shift mappings with new footprint-based reconnection criteria, and reduce spatiotemporal correlation with duplication maps. We further improve both performance and quality by extensive optimization, unifying direct and global illumination into the same reservoirs, and utilizing existing techniques for color noise and disocclusion noise reduction.