Ryoya Nara | CaseMatch me-retweet
Ryoya Nara | CaseMatch
295 posts

Ryoya Nara | CaseMatch
@nararyoyalicky
東大情報理工修士→CTO@CaseMatch / 未踏adv'24・未踏'22 スーパークリエータ 副業・インターンに興味ある方は気軽にDMください!
Bergabung Mart 2024
324 Mengikuti205 Pengikut

気になる👀
Sakana AI@SakanaAILabs
We’re excited to introduce KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, accepted at #ICASSP2026! 🐢 Blog pub.sakana.ai/kame/ Paper arxiv.org/abs/2510.02327 Can a speech AI think deeply without pausing to process? In real conversation, we don’t wait until we’ve fully worked out what we want to say—we start talking, and our thoughts catch up as the sentence unfolds. Fast speech-to-speech models achieve this, but their reasoning tends to stay shallow. Cascaded pipelines that route through a knowledgeable LLM are smarter, but the added latency breaks the flow—they fall back to "think, then speak." In our new paper, we propose a way to break this trade-off. We call it KAME (Turtle in Japanese). A speech-to-speech model handles the fast response loop and starts replying immediately. In parallel, a backend LLM runs asynchronously, generating response candidates that are continuously injected as "oracle" signals in real time. This shifts the AI paradigm from "think, then speak" to "speak while thinking." The backend LLM is completely swappable. You can plug in GPT-4.1, Claude Opus, or Gemini 2.5 Flash depending on the task without changing the frontend. In our experiments, Claude tended to score higher on reasoning, while GPT did better on humanities questions. Try the model yourself here: huggingface.co/SakanaAI/kame
日本語
Ryoya Nara | CaseMatch me-retweet

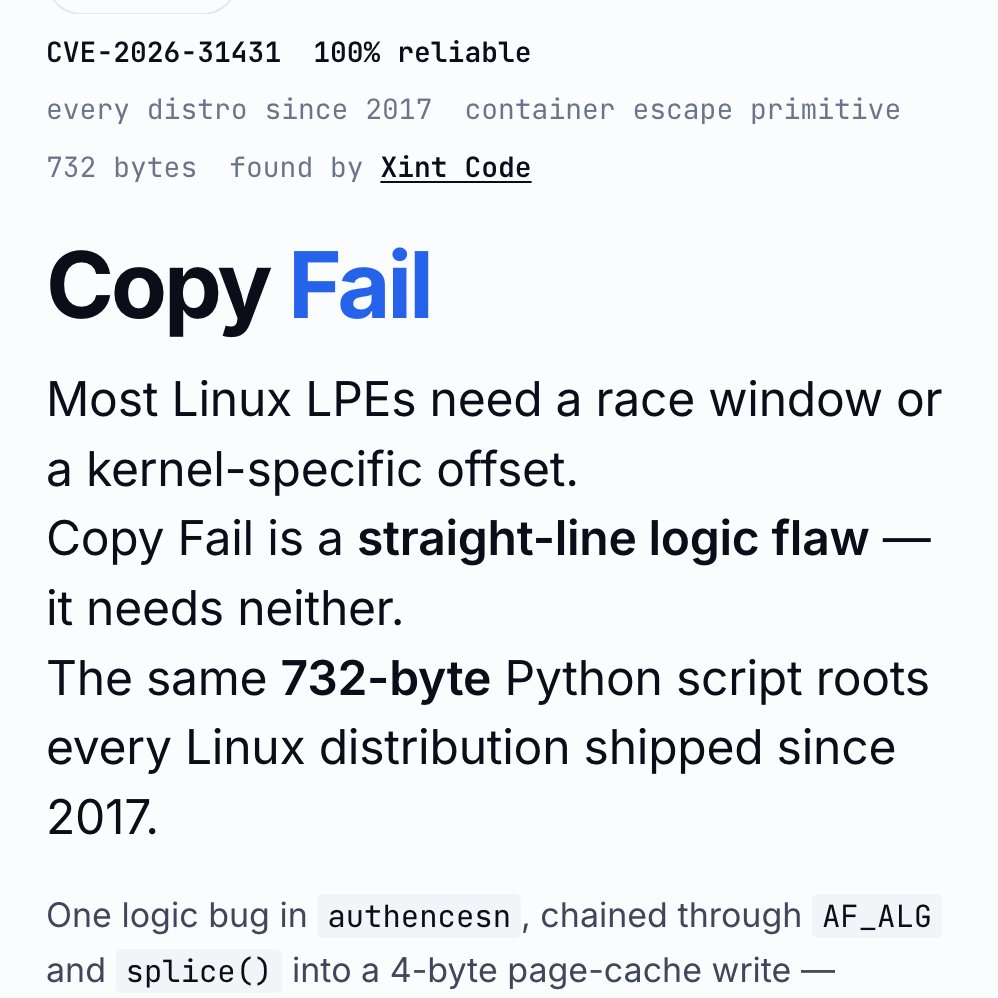
‼️🚨 BREAKING: An AI found a Linux kernel zero-day that roots every distribution since 2017. The exploit fits in 732 bytes of Python. Patch your kernel ASAP.
The vulnerability is CVE-2026-31431, nicknamed "Copy Fail," disclosed today by Theori. It has been sitting quietly in the Linux kernel for nine years.
Most Linux privilege-escalation bugs are picky. They need a precise timing window (a "race"), or specific kernel addresses leaked from somewhere, or careful tuning per distribution. Copy Fail needs none of that. It is a straight-line logic mistake that works on the first try, every time, on every mainstream Linux box.
The attacker just needs a normal user account on the machine. From there, the script asks the kernel to do some encryption work, abuses how that work is wired up, and ends up writing 4 bytes into a memory area called the "page cache" (Linux's high-speed copy of files in RAM). Those 4 bytes can be aimed at any program the system trusts, like /usr/bin/su, the shortcut to becoming root.
Result: the next time anyone runs that program, it lets the attacker in as root.
What should worry most: the corruption never touches the file on disk. It only exists in Linux's in-memory copy of that file. If you imaged the hard drive afterwards, the on-disk file would match the official package hash exactly. Reboot the machine, or just put it under memory pressure (any normal system load that needs the RAM), and the cached copy reloads fresh from disk.
Containers do not help either. The page cache is shared across the whole host, so a process inside a container can use this bug to compromise the underlying server and reach into other tenants.
The original sin was a 2017 "in-place optimization" in a kernel crypto module called algif_aead. It was meant to make encryption slightly faster. The change broke a critical safety assumption, and nobody noticed for nine years. That bug then rode every kernel update from 2017 to today.
This vulnerability affects the following:
🔴 Shared servers (dev boxes, jump hosts, build servers): any user becomes root
🔴 Kubernetes and container clusters: one compromised pod escapes to the host
🔴 CI runners (GitHub Actions, GitLab, Jenkins): a malicious pull request becomes root on the runner
🔴 Cloud platforms running user code (notebooks, agent sandboxes, serverless functions): a tenant becomes host root
Timeline:
🔴 March 23, 2026: reported to the Linux kernel security team
🔴 April 1: patch committed to mainline (commit a664bf3d603d)
🔴 April 22: CVE assigned
🔴 April 29: public disclosure
Mitigation: update your kernel to a build that includes mainline commit a664bf3d603d. If you cannot patch immediately, turn off the vulnerable module:
echo "install algif_aead /bin/false" > /etc/modprobe.d/disable-algif.conf
rmmod algif_aead 2>/dev/null || true
For environments that run untrusted code (containers, sandboxes, CI runners), block access to the kernel's AF_ALG crypto interface entirely, even after patching. Almost nothing legitimate needs it, and blocking it shuts the door on this whole class of bug...

English
Ryoya Nara | CaseMatch me-retweet

uuid標準パッケージの追加がついにマージ!👏👏👏
Go 1.27から標準パッケージにUUID入りそう!!
github.com/golang/go/comm…
日本語
最近は、抽象的かつ概念的な議論に対して向き合うことの重要さを感じている
エンジニアリングで求められる具体的・決定論的な議論とはだいぶ趣向が違うので、頭のスイッチングコストが大きい
日本語
どこかで見た記憶があるんだけど、エージェントフレームワークの「早すぎる抽象化」という罠はかなり意識しないとダメだなと最近めちゃくちゃ痛感している
特にプロダクションに載せる時にはかなりここの技術選定に気を使わないと、進化させるときに圧倒的に出遅れる
日本語
Ryoya Nara | CaseMatch me-retweet

【28卒|想定年収600〜800万円】
経営・戦略コンサル/DXコンサル/新規事業開発1DAY BOOTCAMP(幹部候補ルート直結)
第2タームのエントリー開始。
※4月29日エントリー締め切り
AI戦略を軸に2030年売上3,000億を目指すSHIFTが、超早期内定直結の特別選考を実施。
実ビジネス課題に対し、AI前提で戦略立案〜事業開発まで取り組み、外資コンサル/大手金融出身の部長から直接FB。
・戦略×IRまで踏み込む経営コンサル
・生成AIなど0→1の新規事業開発
・大手企業のDX/AI導入支援
成績優秀者は超早期内定(5〜7月)へ。戦コン級の難易度ですが、その分リターンは大きいです!
コンサル志望・事業開発志向の方は必見です!
#28卒

日本語
Ryoya Nara | CaseMatch me-retweet

テックブログを公開しました。
「Scaling Speech AI」の下、1Bから3Bへと音声言語モデルをスケールさせた際のTTS性能へ影響を検証しました。
日本語特有の読みや表記揺れ、表現の広がりがみられるに加え、現状の課題についても整理しています。
日本語音声生成・SpeechLM・TTSに関心のある方はぜひご覧ください。
blog.dubguild.com/melte/llm-tts-…
1B/3Bモデルの構築にあたって実施した、データ前処理・事前学習・事後学習の詳細も、今後順次公開していく予定です。
続報もお待ちいただければ幸いです。
日本語
Ryoya Nara | CaseMatch me-retweet

メルカリのClaude Codeセキュリティ設定の組織展開戦略、めちゃくちゃ実践的で参考になる。
▼ 以下要点メモ
Claude Codeは便利だけど、コマンド実行・ファイル読み書き・Web取得ができる=PCの認証情報や重要ファイルへのリスクがある。
そこでメルカリがやった5つの対策:
① bypassモード禁止(人間が必ず確認)
② curl等の危険コマンドは都度確認
③ 環境変数読み込み・sudo禁止
④ Sandboxでディレクトリ外操作・ネットワーク制限
⑤ システムプロンプトにセキュリティポリシー埋め込み
で、これを全社員にどう届けるか?
→ MDM(端末管理)で一斉配布。
社員は何もしなくても安全な設定が入った状態になる。
ただ、MDM設定は「最高優先度」で適用される=社員が上書きできない。
すると:
・エンジニア →「カスタマイズさせてくれ」
・非エンジニア →「最初から安全にしてくれ」
→ 両方を満たす1つの設定は存在しない。
メルカリの解決策:MDMから「社員の属性(エンジニア/非エンジニア)」を判別し、それぞれに別の設定セットを配布する二層構造に。
エンジニアには安全性を保ちつつカスタマイズ可能な設定、非エンジニアには最も安全な設定をそのまま提供。
大企業でClaude Codeを全社導入する際の「設定をどう配るか」問題、まさにこれから多くの企業がぶつかる課題だと思うので、MDMで一律配布→属性別に分離、という実践的な知見は貴重。

日本語
今後人が磨くべき能力は
・①において壮大な目標をクリアに立てるための知識量と想像力
・②を精度高く実現するための仕組み構築力
・③を高速かつ正確に実行できる専門性
で、すでに2個目に関してはもう誰がやっても差がつきにくくなっている気がする。なので、1個目と3個目が大事なのかな。
日本語
今のAI時代において、ホワイトワーカーの役割は↓の3段階に集約されてる気がする
①やりたい事を構想する
②AIに入力する
③出力を見て、納得いくまで①へ戻る
日本語
従来だったら「導入難易度が高い」として敬遠されてきたツールも、本質的な部分さえ人間が分かっていればAIで結構楽に導入できるようになっているのを感じる
KubernetesとかBazelとかが良い例
日本語
Ryoya Nara | CaseMatch me-retweet

弊社SPARQで創業期の営業コアメンバーを募集しています!
リリースから約1年で国内外のリーディングブランドへの導入が進み、異例のスピードで売り上げが立ち、現在はPMFを経て本格的な拡大フェーズに突入しています!
興味ある方はご応募お願いします🙏
youtrust.jp/recruitment_po…
日本語
アイコン情報とかは結局スクショ経由だと全然再現されないので、デザインシステム (とそれを上手くAIに入力する仕組み) が欲しくなる
日本語
分かりすぎる
そして結局Figma MCP経由で取得された大量のスクリーンショットの残骸がローカルに残る
nrs@nrslib
AI くん、Figma MCP や React モックサンプルよりもスクショのほうが UI の再現度高いのはなぜ
日本語