Post


@cursor_ai please share the repo where the code for the tests resides, I want to reproduce it
English

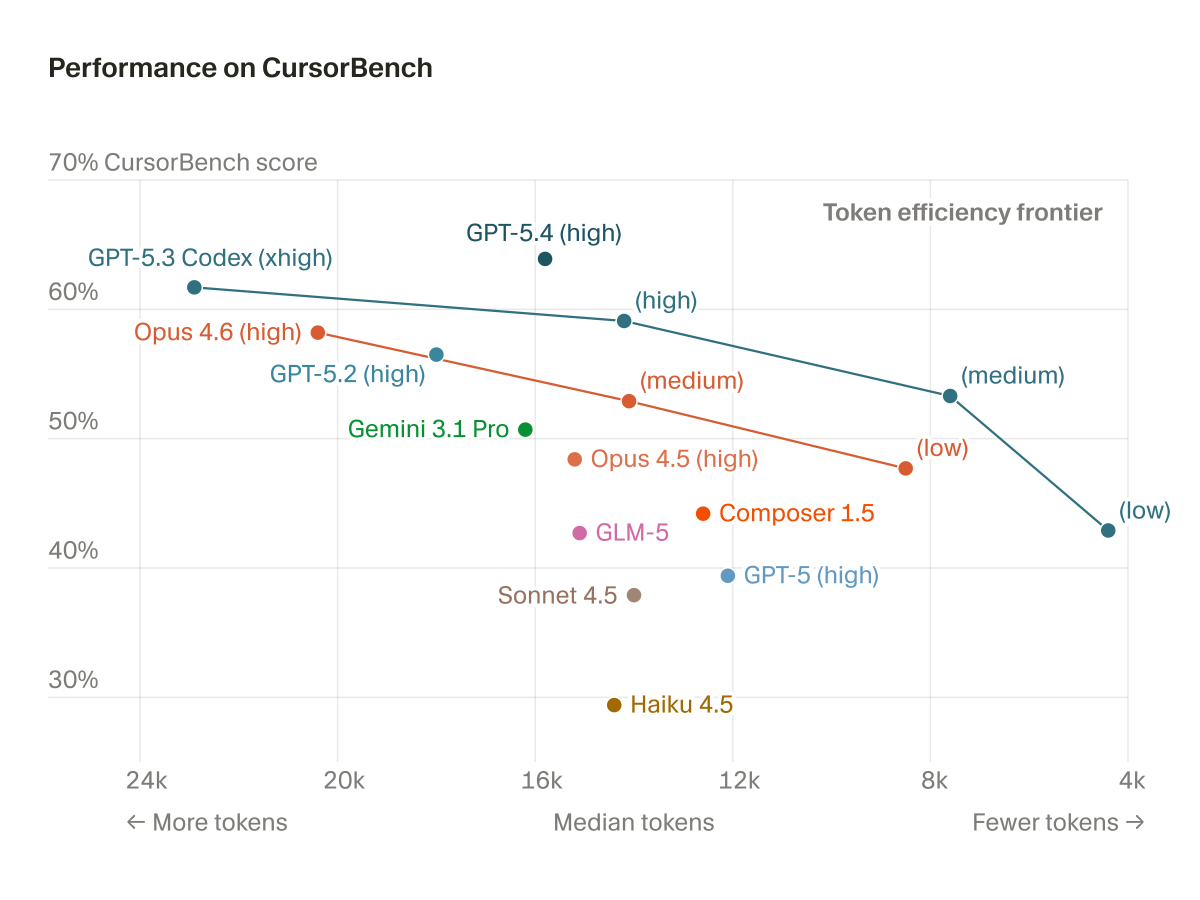
@cursor_ai i’m confused, why does it say lower score is better in the final figure for online evals?
English

@cursor_ai Hope you get bankrupt at some point with all your practice screwing your userbase with lies. Sad that it has to come that far! At least be honest in your communication lol. OH VEY
English