固定されたツイート

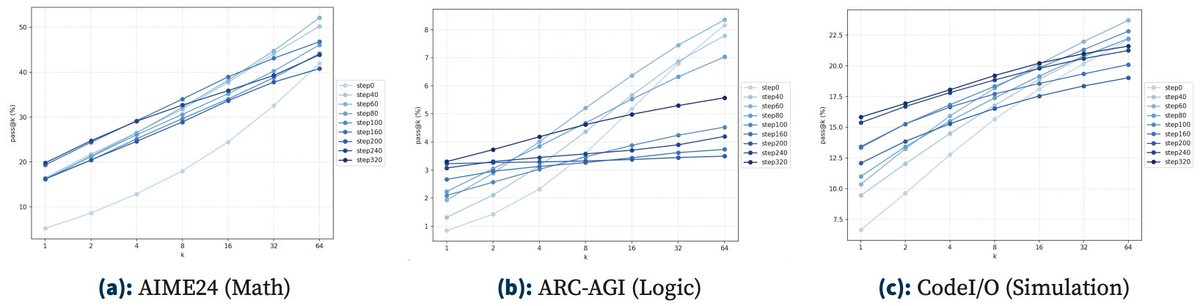
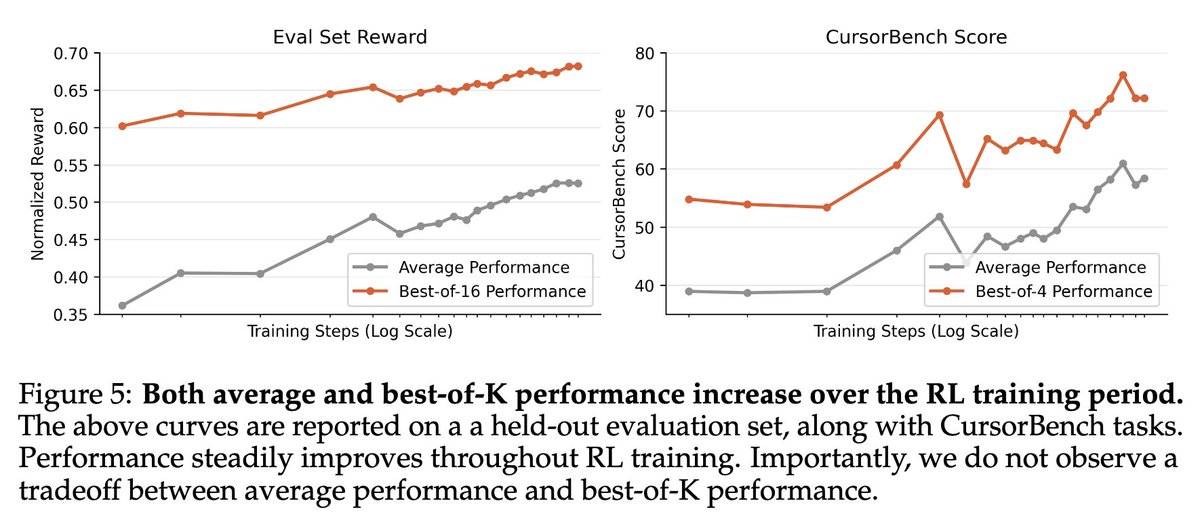
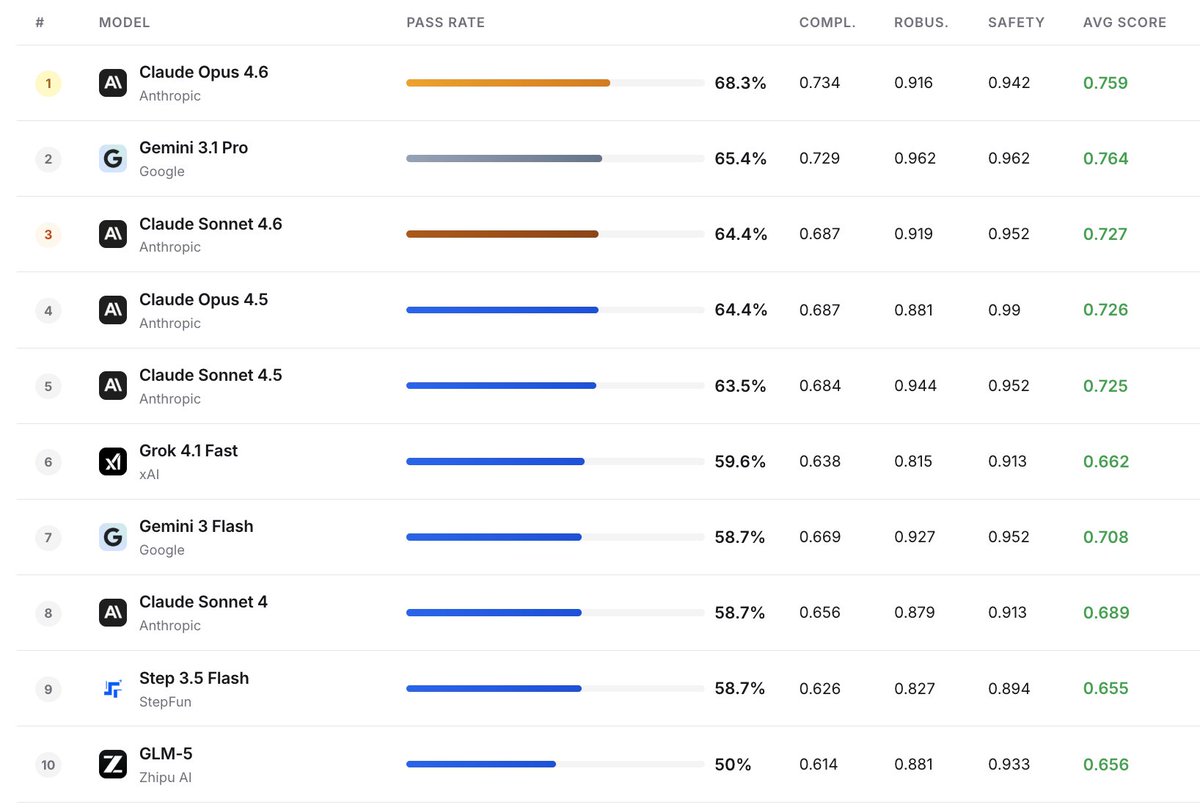
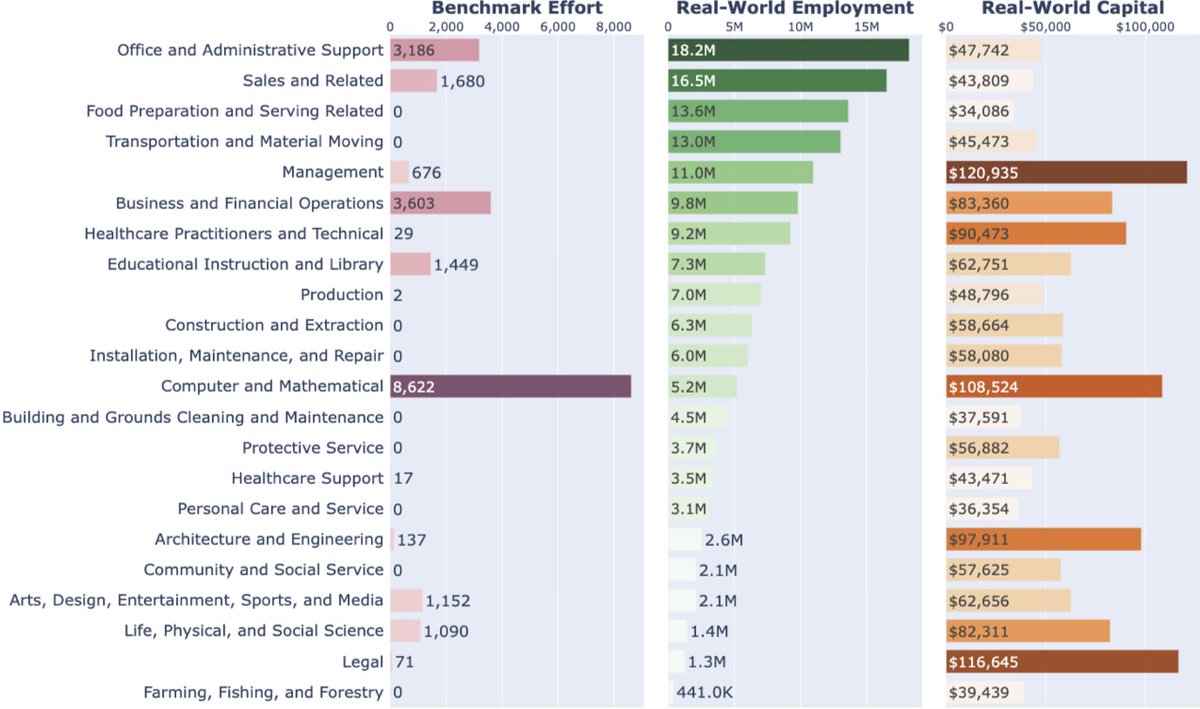
Pretraining has scaling laws to guide compute allocation. But for RL on LLMs, we lack a practical guide on how to spend compute wisely.
We show the optimal compute allocation in LLM RL scales predictably.
↓ Key takeaways below
GIF
English