Long time no see!
We've just released a bugfix and maintenance release of `tabula-java`, our table segmentation and recognition library.
Changelog here: github.com/tabulapdf/tabu…
Happy holidays, Tabula users!
@manuelaristaran, one of our maintainers, will work on Tabula over the (southern) summer.
Which feature would you like see implemented?
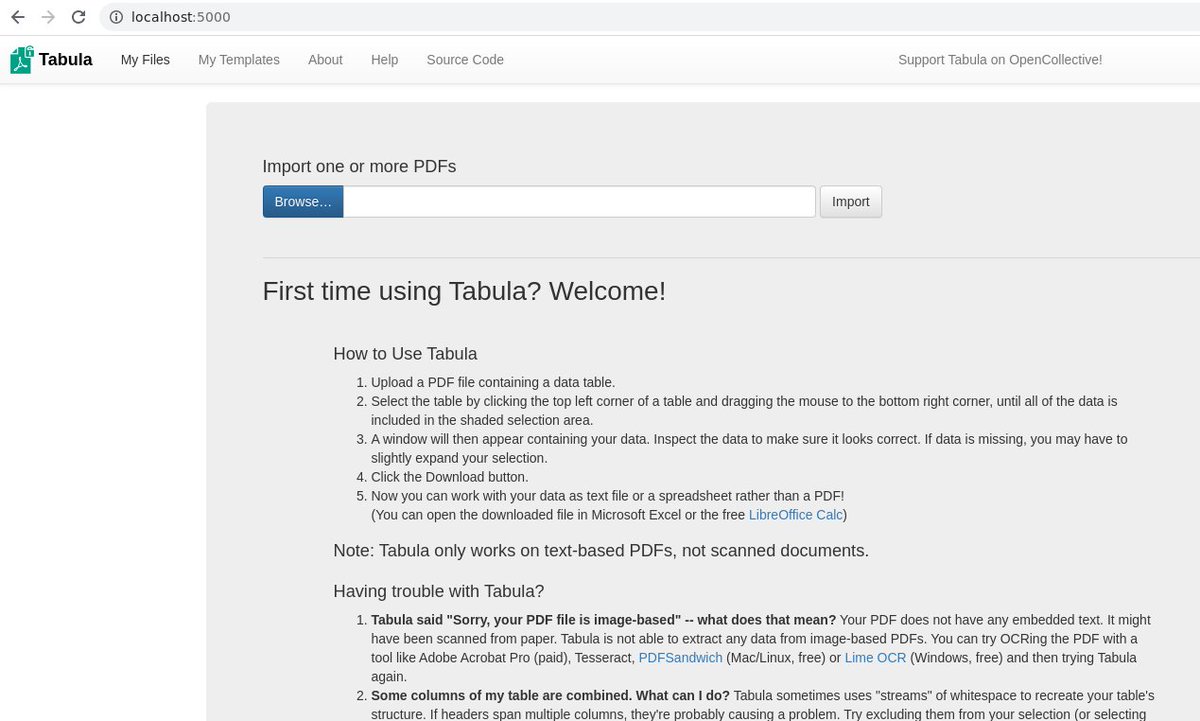
NRGI's PDF Table Extractor application builds on the open-source software Tabula, which does the heavy lifting of identifying tables in the PDF and extracting them to tabular format. resourcegovernance.org/analysis-tools…
@TabulaPDF After many hours spent fumbling with data buried inside PDF, was happy to come across Tabula. Thank you for such a great tool. #Comment_15106" target="_blank" rel="nofollow noopener">community.waveapps.com/discussion/com…
In a few minutes @doyenwilliams has showed us how to export and visualize data previously ‘hidden’ in a PDF + automatically generate HTML to build webpages. Want to try this for yourself? Check out @TabulaPDF and @amcharts.
Do you know how amazing @TabulaPDF is at extracting data from PDFs?
Would you like to find out?
New York has a lot of parse-able PDF results:
github.com/openelections/…
@vortex_ape@serahrono@Social_Cops Hi, and welcome to the exciting world of PDF table extraction and segmentation!
Just wanted point out a small thing in your blog post. @TabulaPDF does not use the Hough transform for detecting lines. We use a combination of scraping the vector elements and raster lines…
Thanks @timodonnell for showing me @TabulaPDF -- I was starting to lose hope while trying to liberate data from horrible supplemental PDFs.
Shame on major bio journals for allowing (or even forcing) 1000+ page PDFs instead of some machine readable format.