固定されたツイート

Tim Dingman
5.2K posts

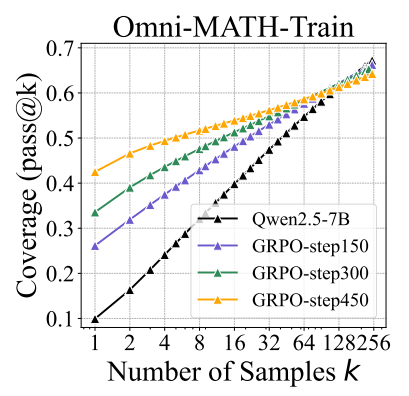


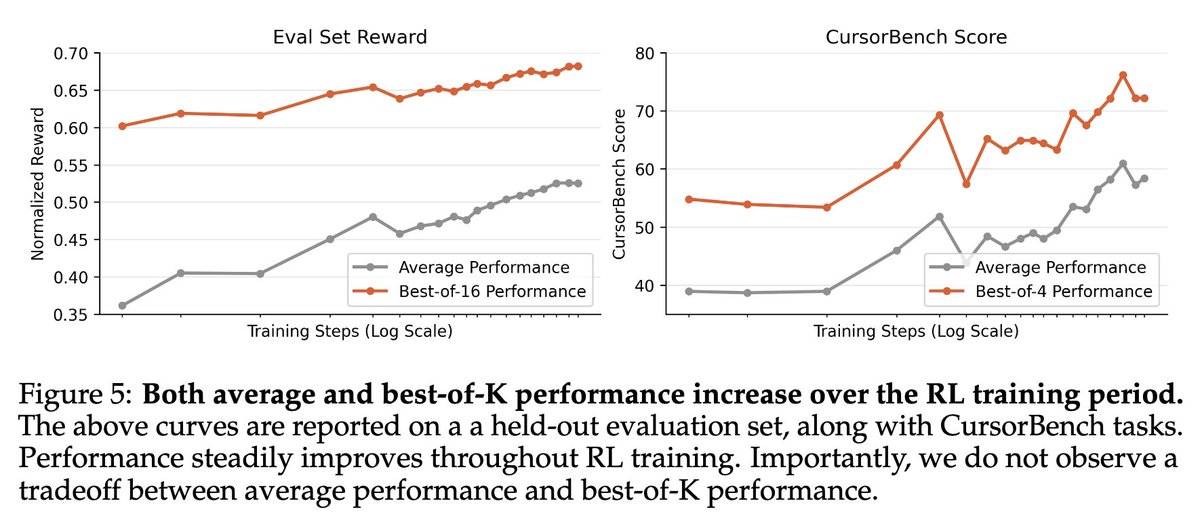
We're releasing a technical report describing how Composer 2 was trained.

Both xAI and Meta seem to be falling behind, based on the Grok 4.2 benchmarks and this reporting. Frontier AI models are really a three way race at this point.



Nicholas Carlini at [un]prompted. If you know Carlini, you know this is a startling claim.
It is clear to me that @kalshi is going down the same path as Juul, and if they don’t pull back it is going to have the same conclusion. For those that don’t remember, Juul was one of a number of the main vaping brands in the 2010s. It took a product that had a social good (helping smokers quit) but then aggressively pushed it into a new market, non smokers and particularly kids. (See the similarity?) The backlash took time to build but when it did it was devastating for the company. I’ve worked in the online gaming industry for over 25 years, all over the world. This type of marketing is actually extremely rare in real money gaming. Firstly and most importantly it is rare because operators view it as highly unethical. It might surprise you that a lot of people in the gaming industry do actually care about things like underage and problem gambling. Secondly it is also rare because it doesn’t work. Do you think the teenagers in these ads are going to keep playing when they lose all their rent money? The only other company I can think of that pushed this type of advertising was Skillz who aggressively pushed the “second income” line. Check out their share price if want to see how that worked out for them.

saying deepseek built moe on top of mixtral is nonsense, the deepseek moe paper came out just 3 days after mixtral paper was posted on arxiv also the mixtral paper has literally no detail about the training so "we released like everything that was needed to rebuild this kind of architecture" is also false, the paper just says "we use google gshard arch with simpler routing and moe every layer" and no detail on data, hyperparameters, training tokens, ablations ect.. the architecture that deepseek moe uses is actually different from gshard and more sparse (deepseek moe doesn't even cite mixtral in the paper, but gshard) not saying mixtral didn't have an impact on moe, but what is said in this interview is a bit rewriting the narrative to say "but look china/deepseek is also copying mistral!"
If you are wondering what is happening: last summer, the Ministry of Science of Korea created a program with 5 companies to train sovereign AI models and release them under a permissive license, so other South Korean companies can use them and hence expand their domestic AI ecosystem to recap we got: - SK Telecom: A(.)X-K1 519B total, 33B active - LG: K-EXAONE 236B total, 23B active - NC-AI: VAETKI 112B total, 10B active - Upstage: Solar-Open 102B total, 12B active - Naver: HyperCLOVAX-SEED-Think 32B Dense this is REALLY a big deal