固定されたツイート

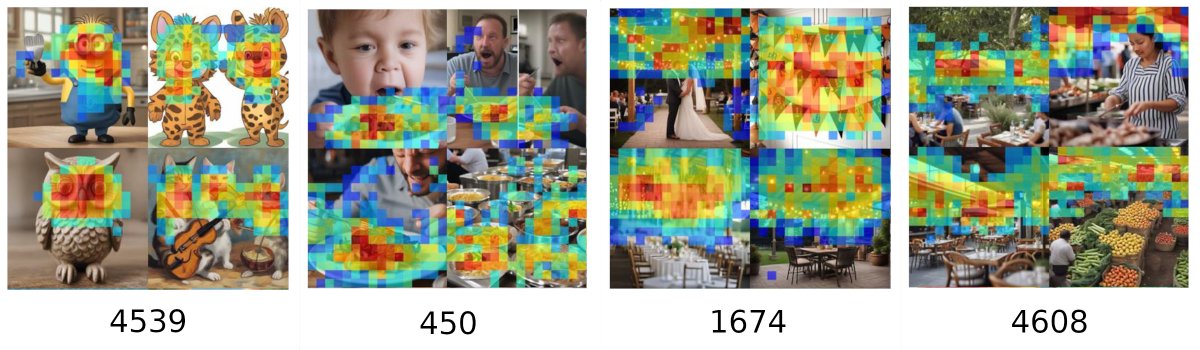
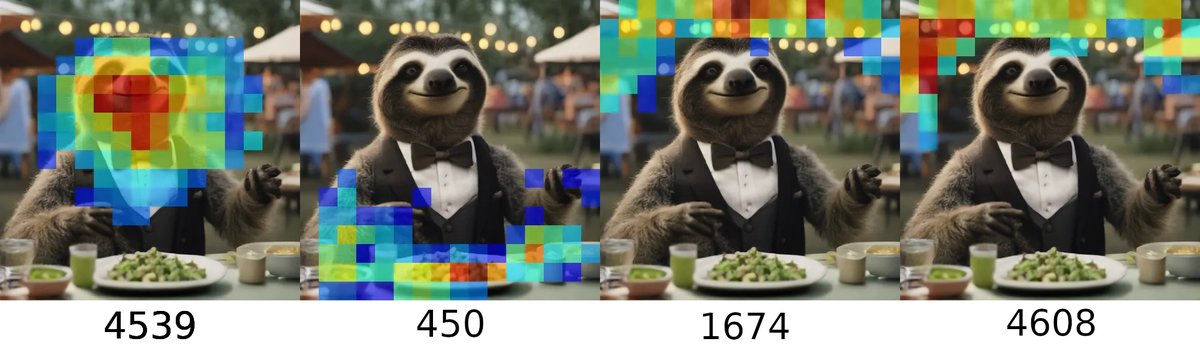
Excited to share our latest breakthrough! We trained sparse autoencoders to decompose intermediate results of SDXL Turbo's forward pass. These autoencoders learn highly interpretable features that can be used to manipulate the image generation process.
arxiv.org/abs/2410.22366
GIF
English