ɹoʇɔǝΛʞɔɐʇʇ∀ がリツイート

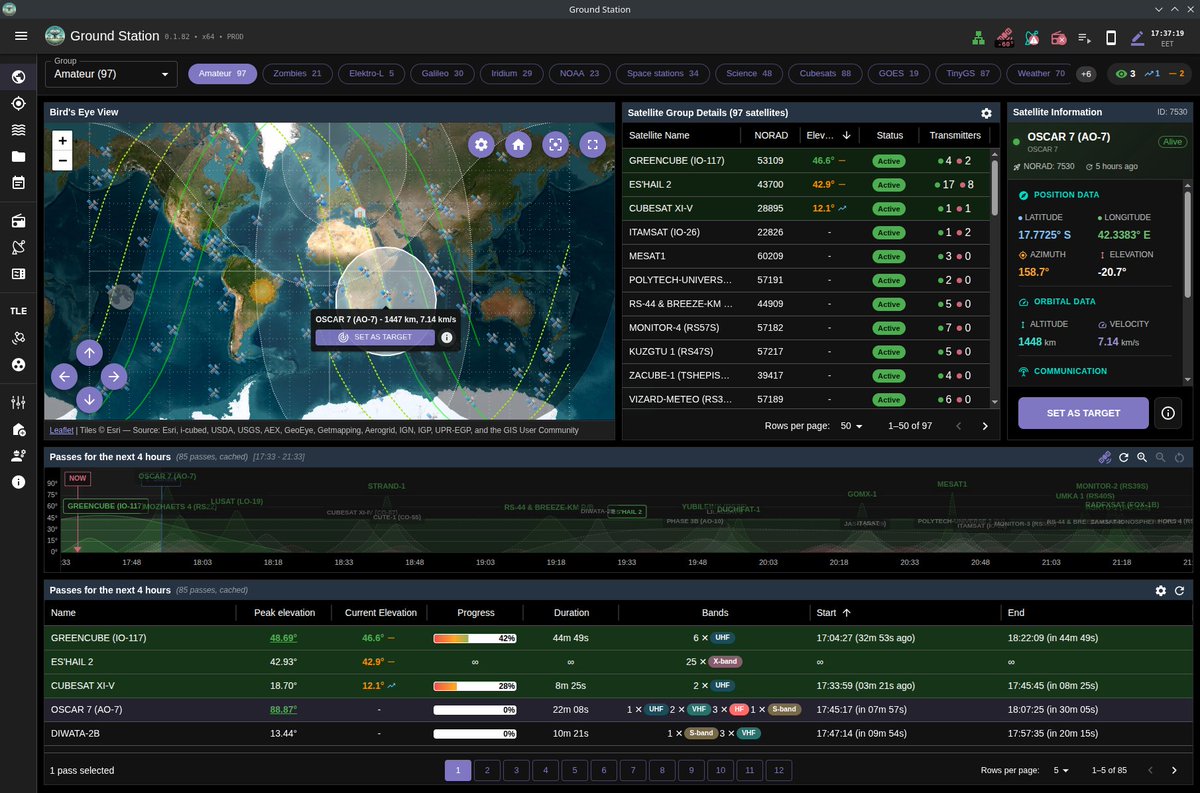
🚨 BREAKING: Someone just open-sourced a full suite for tracking satellites and decoding their radio signals locally.
You don't even need the internet. It uses an SDR to pull weather images and raw data straight from space to your hard drive.
100% Open Source.
English