CLAUDEWHIP JUST GOT A CEASE AND DESIST FROM ANTHROPIC
LAST TIME THIS HAPPENED THE POKEMON COIN WENT OVER 500K
HUGE NEWS
PROOF:
x.com/blended_jpeg/s…
yaml@blended_jpeg
English
lequant
1.5K posts


@Devon_Eriksen_ Yeah
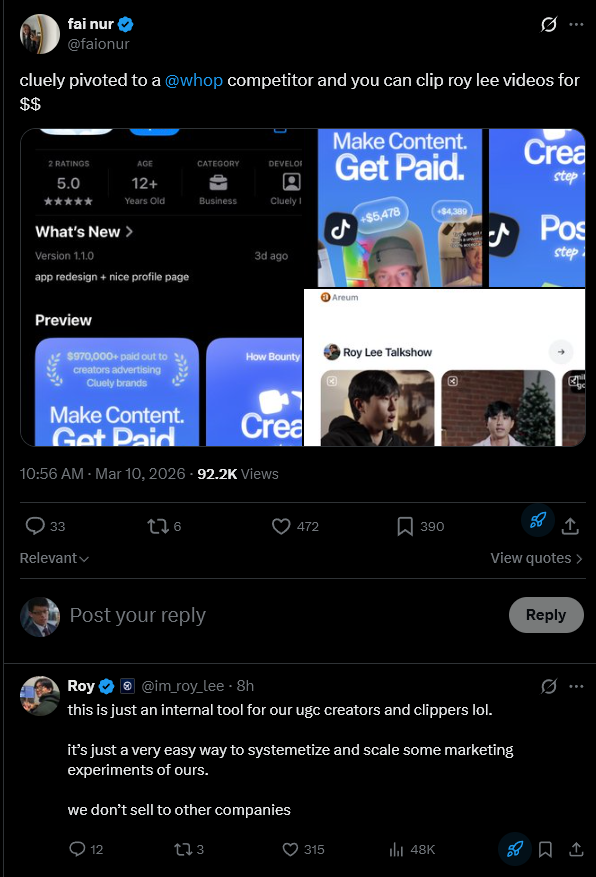
cluely pivoted to a @whop competitor and you can clip roy lee videos for $$
i open-sourced autokernel -- autoresearch for GPU kernels you give it any pytorch model. it profiles the model, finds the bottleneck kernels, writes triton replacements, and runs experiments overnight. edit one file, benchmark, keep or revert, repeat forever. same loop as @karpathy autoresearch, applied to kernel optimization 95 experiments. 18 TFLOPS → 187 TFLOPS. 1.31x vs cuBLAS. all autonomous 9 kernel types (matmul, flash attention, fused mlp, layernorm, rmsnorm, softmax, rope, cross entropy, reduce). amdahl's law decides what to optimize next. 5-stage correctness checks before any speedup counts the agent reads program.md (the "research org code"), edits kernel.py, runs bench.py, and either keeps or reverts. ~40 experiments/hour. ~320 overnight ships with self-contained GPT-2, LLaMA, and BERT definitions so you don't need the transformers library to get started github.com/RightNow-AI/au…
The Hollow Men. @ryancohen