Português
Mossad Inside
1.6K posts




🚨🚨SE VIENE GIGA STREAM🚨🚨 kick.com/pabloabrazo



VERDES. GENIAL.





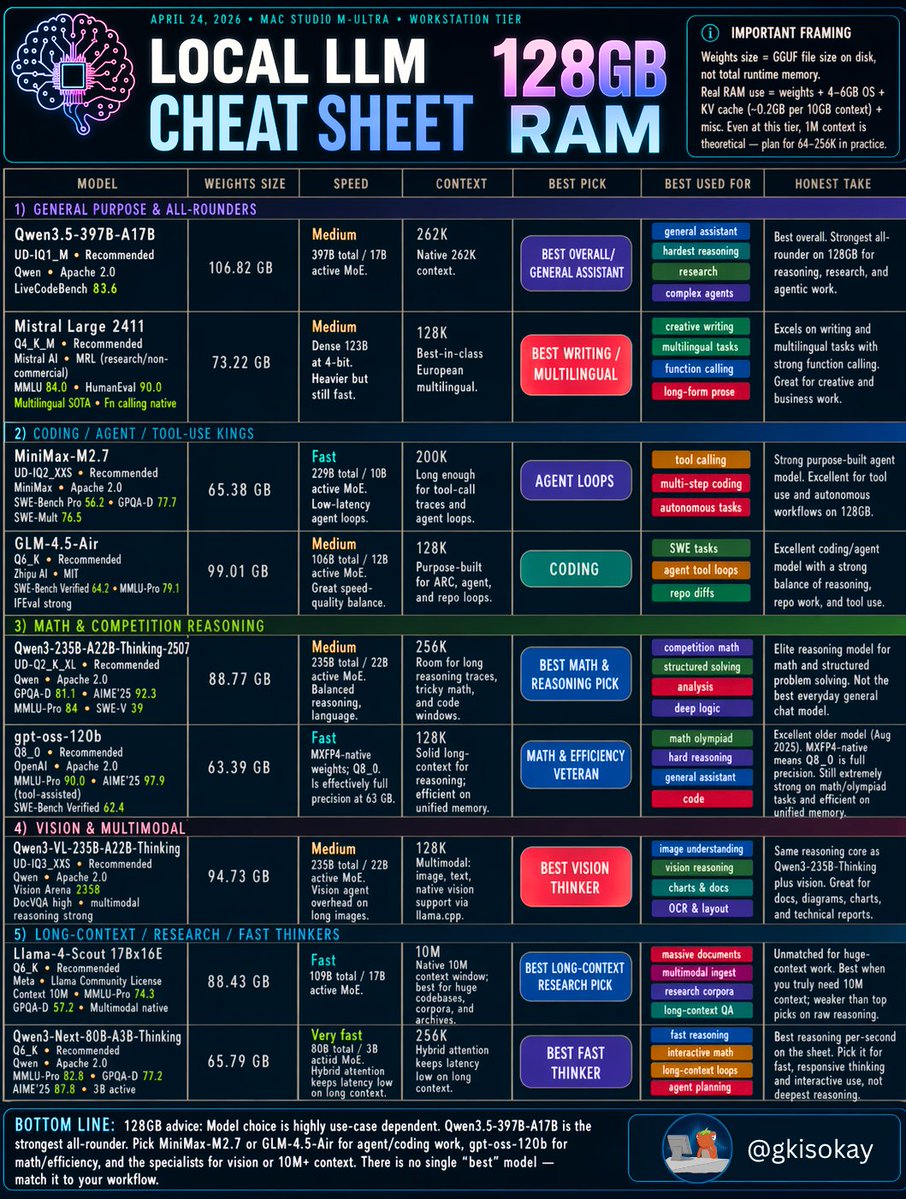
The Local LLM Cheat Sheet for Your 64GB RAM Device We covered 16GB and 32GB already, and 64GB has been the next big request, which I can understand, because this is where things get very interesting. Here's the practical cheat sheet for a 64GB RAM machine for code, math, reasoning, vision, and more. If there’s another memory tier, hardware profile, or model roundup you want next, just let me know. Flagship Models Qwen3.6-27B / GGUF / Q8_0 The best overall 64GB flagship. General chat, coding, reasoning, and agent workflows. This is the headline pick if you want one local model that can do almost everything at a very high level. Qwen3.6-35B-A3B / GGUF / Q6_K Best fast flagship. Strong for agentic coding, tool use, long-context work, and fast iteration. Similar quality class to the 27B, but better if you care more about responsiveness. Models for Heavyweight Use Llama 3.3 70B / GGUF / Q4_K_M The safe big-model workhorse. Best for long-form writing, broad world knowledge, complex chat, and reliability. Not the sharpest value pick anymore, but still a very strong 70B-class option. Nemotron Super 49B v1.5 / GGUF / Q6_K Reasoning specialist. Better suited for math, structured reasoning, analysis, and agent planning than a general-purpose chat model. One of the best picks here if the work is analytical. Gemma 4 31B / GGUF / Q8_0 Dense premium model. Writing, multilingual work, analysis, and high-end local chat. Heavier than the smaller MoE options, but excellent when output quality matters more than speed. Kimi-Linear-48B-A3B / GGUF / Q5_K_M Long-context specialist. Massive docs, whole-codebase Q&A, research, and long-running agents. This is the one to look at if context length is the real priority. Models for Specialty Use Qwen3-30B-A3B-Thinking-2507 / GGUF / Q6_K Thinking specialist. Best for step-by-step math, logic, deliberate analysis, and deep reasoning. A good pick if you specifically want a model that feels tuned for visible thinking. Qwen3-Coder 30B-A3B / GGUF / Q6_K Coding specialist. Best for agentic coding, repo edits, tool use, and PR-style work. If you are building code agents, this is one of the clearest specialty picks on the sheet. Qwen3-VL-32B / GGUF / Q6_K Vision specialist. Image understanding, document OCR, UI analysis, and multimodal agent workflows. This is the right pick if you need a serious local multimodal model in this RAM tier. Let me know which models you are running on 64GB, or if you want to see a cheat sheet for 128GB next.