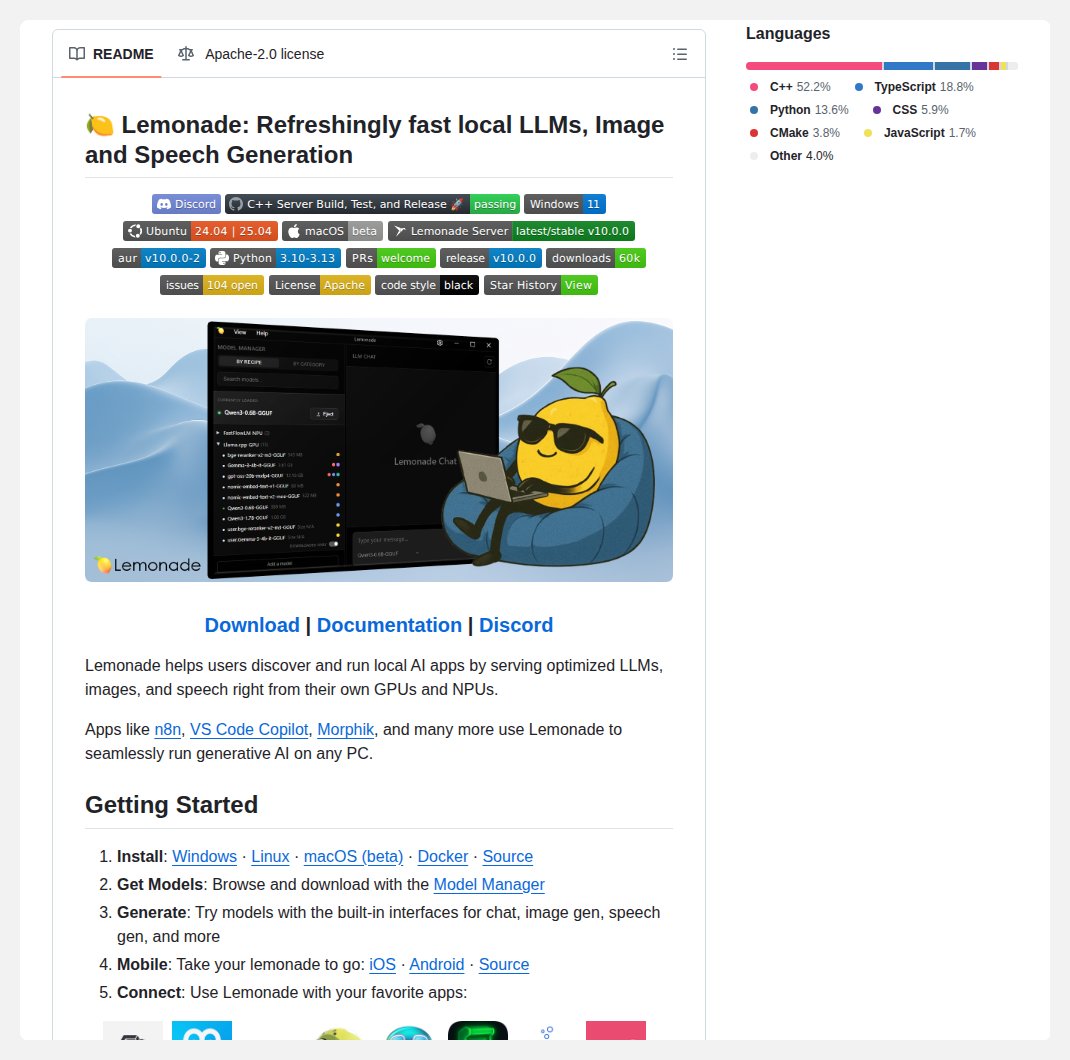
Ant Ling@AntLingAGI
Last week, we introduced Ling-2.6-1T. Today, Ling-2.6-1T is officially an open model~ 🤗
1T total parameters · 63B active parameters
We bring values to developers by making it easier to test, deploy, customize, and build.
It is optimized to be "token efficiency" for real production needs:
• Lower token overhead: strong intelligence without long reasoning traces
• Reliable multi-step execution: better instruction, tool, context, and workflow control
• Production-ready deployment: from code generation to bug fixing, with broad agent framework compatibility
A sneak pick into the agentic capability in @opencode