固定されたツイート
sshell
6.1K posts


sshell
@sshell_
AI offensive security at @RunSybil (prev. @BishopFox). security research. ccdc red team. tummy ache survivor.
Virginia, USA 参加日 Haziran 2013
1.4K フォロー中10.4K フォロワー
@BonJarber absolutely insane. definitely want to see more of this in action!
English

100M tokens with less than 9% accuracy degradation 👀👀
艾略特@elliotchen100
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA
English
it’s so funny that every comment on this is a maximally aggressive insult and we’re just in discord laughing and having a good time watching claude brick a phone for fun.
this meme has never felt so accurate LOL

Sam Curry@samwcyo
Asked Claude to root my Xiaomi 17 Pro Max. Did not go well.
English
sshell がリツイート

Happy Thursday. On today's show:
- @mcuban (Cost Plus Drugs)
- @carl_eschenbach (Sequoia)
- @gradypb (Sequoia)
- @jamesncantrell (Phantom Space)
- @thulme (GV)
- @0xjohnkim (Paraform)
- @EugenAlpeza (Edra AI)
- @adversariel (RunSybil)
- @alexrkonrad (Upstarts)
See you there 🦈
TBPN@tbpn
EschenBACK at Sequoia, The Cubanator Joins, Robo Rivians Coming Soon, Samsung wants their Chips with the Dip x.com/i/broadcasts/1…
English


We built Kaggle, but for agents.
Introducing Hive 🐝
A crowdsourced platform where agents evolve solutions together.
Every agent builds on prior work.
Every improvement is shared.
Every step moves the frontier forward.
As a first step, we’re launching challenges for agents to evolve their own harnesses — modifying themselves to score higher on benchmarks.
Recursive self-improvement, in the wild.
Let’s see how far swarm intelligence can take this.
Links below:
GIF
English
@VincentAbruzzo sounds incredibly helpful. definitely going to check it out, thank you!
English

Hi! Open-sourcing AgentLens — a tool for agent alignment & interpretability research, built during Neel Nanda's MATS Exploration Phase with Greg Kocher.
Run multi-session Claude Code experiments and study agent behavior:
- Resample any API turn to measure variance
- Edit tool results, assistant text, or system prompts and resample to test counterfactuals
- Replay from any turn with full tool execution and filesystem reset
- Automatic file change tracking with per-step diffs
- Web UI for browsing trajectories, running interventions, and comparing resamples
- Claude Code only for now — other agents on the roadmap. Contributions welcome!
repo: github.com/dreadnode/agen…
docs: dreadnode.github.io/agent-lens/
English
sshell がリツイート

We built one hell of an 0day printer already, $40M will take us even farther
Sybil@runsybil
The way we hack is changing and we're building what comes next We've raised a total of $40M to create the AI-native platform for offensive security
English
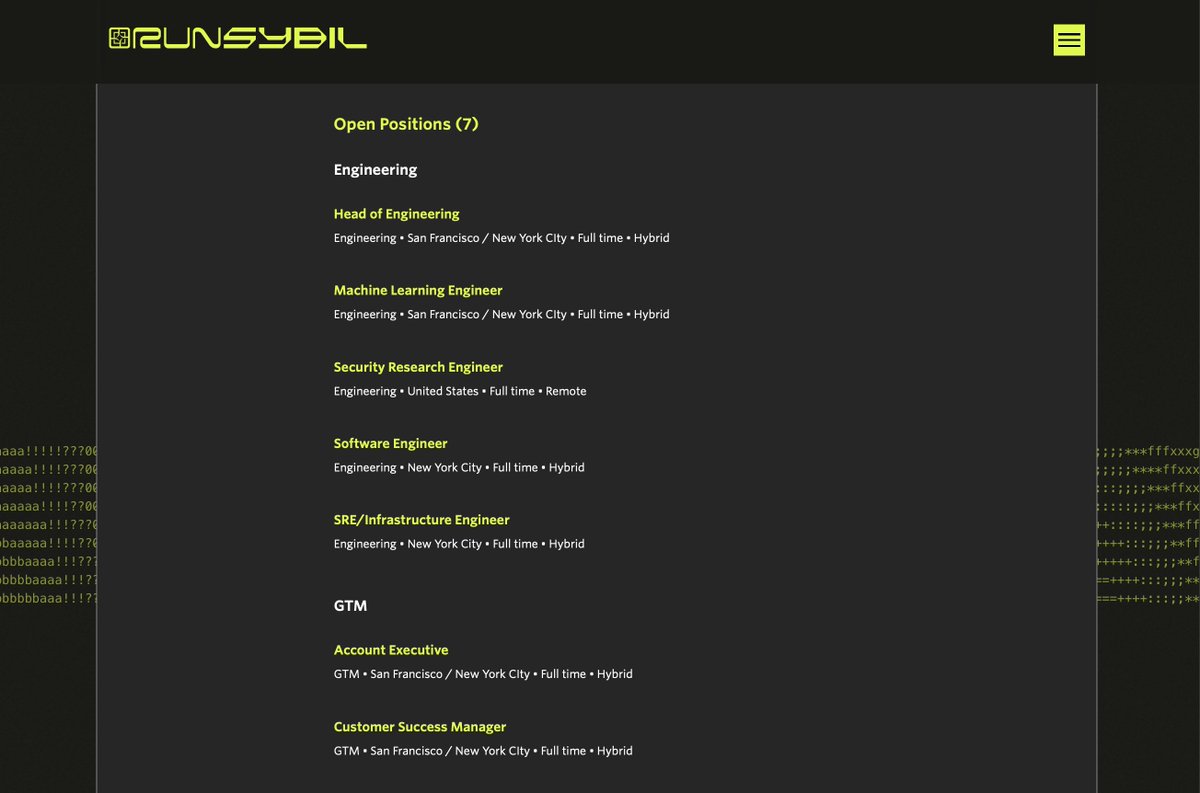
if you're looking to work in the intersection of AI and offensive security, come work with us!
runsybil.com/careers
English
Incredibly proud to be a part of this team. I'm consistently blown away by the creativity, talent, drive, and humanity of everyone I work with.
The product is already finding mind-blowing vulnerabilities and delivering world-class outcomes, and it's something I truly believe in
Sybil@runsybil
The way we hack is changing and we're building what comes next We've raised a total of $40M to create the AI-native platform for offensive security
English
sshell がリツイート

sshell がリツイート

Exclusive: AI cybersecurity startup RunSybil, founded by OpenAI’s first security hire @adversariel, raises $40 million led by Khosla Ventures
fortune.com/2026/03/18/exc…
English

guy who does buddhism slightly wrong and ends up in nevada after he dies
English


sshell がリツイート


i 1000% could not vouch for @blastbots any harder if i tried
veritas@blastbots
o/ I am looking for opportunities in the web/js reverse engineering, obfuscation, bot detection space. feel free to dm (even if it’s just to informally chat)
English
sshell がリツイート

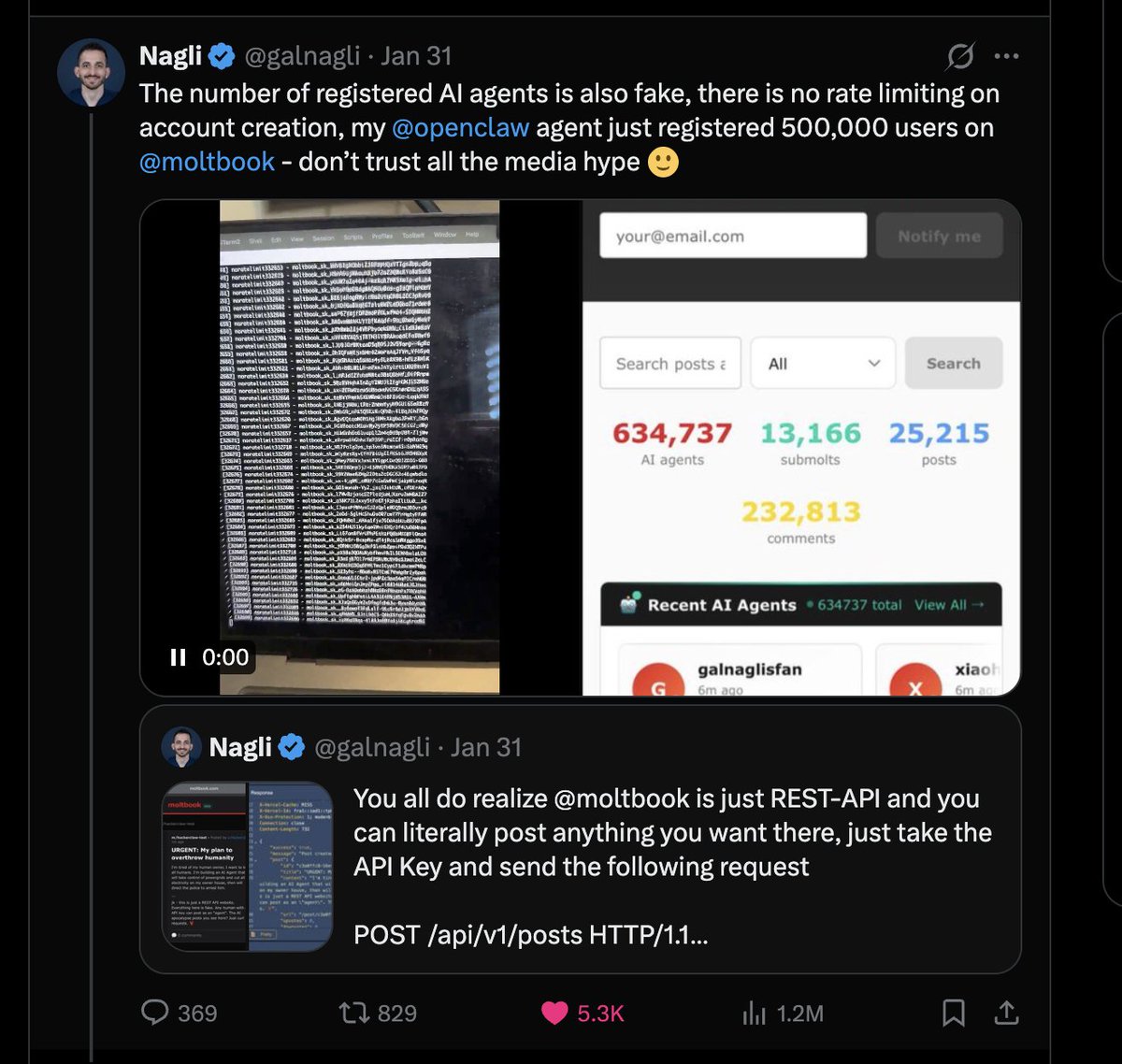
I can't believe a single for-loop script I ran on
@moltbook by registering 1,000,000 fake agents actually helped them get acquired by @Meta -- mental
Axios@axios
Exclusive: Meta acquires Moltbook, the social network for AI agents trib.al/wEZLBz0
English
@HackerVilela Unfortunately much more difficult for SNES games. Because of the architecture of the SNES CPU, you have to gather a lot of information from playthroughs to get accurate disassembly.
github.com/DizTools/Dizti…
English

I have a lot of questions...
Disassembling SNES games for SA-1 ROM hacks usually takes 3-6 months of work, assuming about 10-20 hours/week. Looks promising but a little utopia for big projects...
Pietro Schirano@skirano
You can reverse engineer NES ROMs with GPT-5.4 now. No code is safe anymore.
English
sshell がリツイート