Alex V. 리트윗함
Alex V.
7.1K posts




Alex V. 리트윗함

Acabo de enterarme de la teoría de "nunca me rompí un hueso"
Básicamente, dice que si nunca te has roto un hueso, no estabas destinado a sufrir físicamente en la vida, sino que estabas destinado a sufrir más emocional, mental y espiritualmente.
Adivinen quién nunca se ha roto un hueso.
Español
Alex V. 리트윗함

the original TurboQuant paper tested on A100 with models up to 8B.
6 days later, a bunch of strangers on the internet had it built and running on:
- Apple Silicon M1 through M5
- NVIDIA 3080 Ti through DGX Spark Blackwell
- AMD RX 6800 XT and 9070
- a 10-year-old Tesla P40
- an 8GB MacBook Air
- models from 3.8B to 70B across 6 architecture families
- 30+ independent testers
along the way we found new optimizations the paper didn't cover and failure modes it didn't test.
the fact that a loose group of people across the world can read a paper, build implementations from scratch, stress-test across hardware none of us could individually afford, and push the research further in under a week is genuinely one of the best things about this era. the tools and the community make it possible.
open source is something else.

English
Alex V. 리트윗함

Microsoft is moving to 100% native apps for Windows 11. They are stepping away from web-based wrappers.
A new team at Microsoft will rebuild apps using native tools like WinUI. Engineer Rudy Huyn is involved in this shift.
Apps like File Explorer should launch quicker. The Start menu and context menus will feel more responsive.


English
Alex V. 리트윗함



Alex V. 리트윗함

Be Anthropic
> build amazing models
> invent claude code
> win the hearts and minds of devs
> everyone loves you
> start threatening open source projects with litigation
> stop communicating to the community
> ignore basic questions about ToS
> for weeks
> push even your staunchest supporters to codex
> they launched 2x usage for 2 months
> you launch 2x usage for 2 weekends
> reduce usage during peak hours
> dont tell anyone its enabled for several days
> now 2x weekends is just the same as it was before
great models. honestly great people who work there. but their pr strategy should be studied.
English

Alex V. 리트윗함

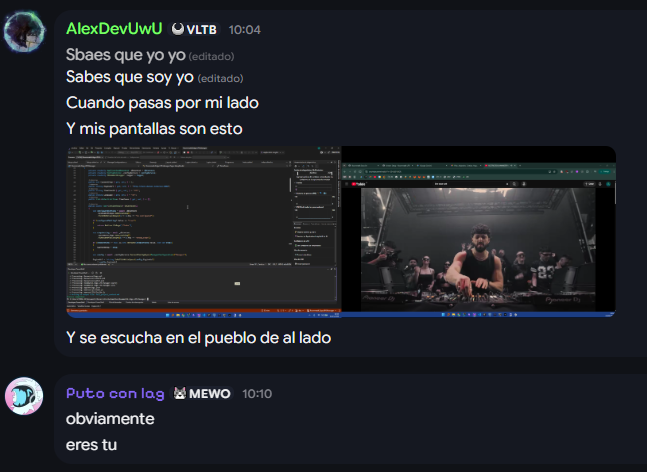
Last week the ScoreSaber March 2026 ranked batch released.
In the case that you've missed it, here's quick overview of all of the 38 new ranked maps!



English

Hmmm hi! I know, I know ...
I'm not around anymore.
Do you remember that they made me a concept art intern? Well, they renewed my contract.
Human art will always live :)
English
Alex V. 리트윗함

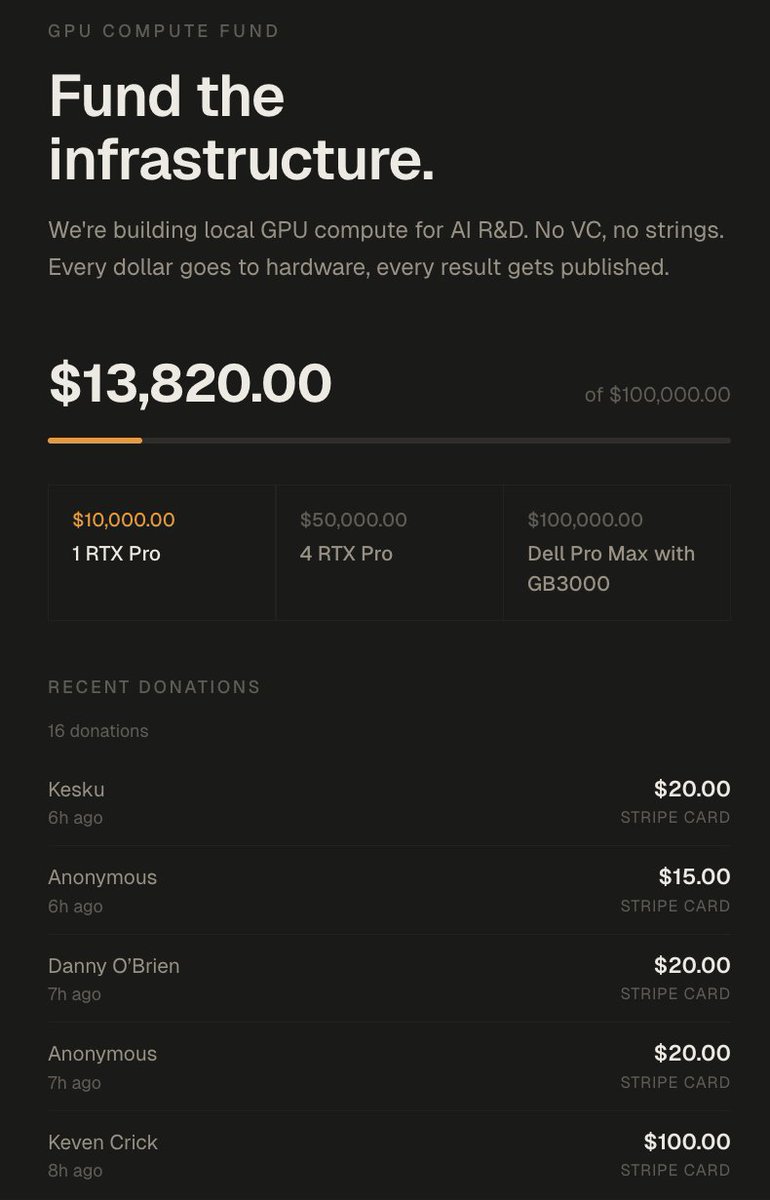
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: github.com/0xSero/moe-com… you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
donate.sybilsolutions.ai
English
Alex V. 리트윗함


Alex V. 리트윗함

Alex V. 리트윗함

📢 Important update on sideloading on Android
It’s of course here to stay. The team’s been listening carefully to feedback from power users who want a way (apart from ADB) to install apps that don’t go through developer verification.
Today, we have more details on the advanced flow that gives you this option.
Read the post👇 for more info
goo.gle/advance-flow

English
Alex V. 리트윗함

Now you can connect your Meta Horizon profile to Discord and let everyone know you're playing Beat Saber. 💥
How to do it? Here👇
bit.ly/4cGPpGg

English
Alex V. 리트윗함

Your phone doesn’t use your mic to spy on you.
Reality is much scarier: your phone infects your subconscious and influences what you talk about
saraaaaaaa 💽@saraaa7447
By the way I have proof the stock ROM spies on you because I was in the kitchen with it being the only "smart" device in the room and discussing lucid dreams. Then I went back to my computer and saw a bunch of "how to lucid dream" videos on YouTube. I haven't seen videos relating to the topic in over 4 years so yeah y'all might wanna install Graphene or smth 💀
English



A little sketch preview of Nyarwie sketchpage AND my new commission service! Once I'm done with my work I'll put this as my new service on my vgen <3
#sketch

English
