Vishakha Gupta-Cledat@vishakha041
Recently, the team at iSonic.ai (Praneel Panchigar, Nisshutosh Sharma, Torlach Rush, and Ankesh Kumar) decided to 𝗺𝗼𝘃𝗲 𝗳𝗿𝗼𝗺 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 𝘁𝗼 𝗔𝗽𝗲𝗿𝘁𝘂𝗿𝗲𝗗𝗕 for their text‑ and metadata‑heavy workloads and replaced a vector‑only setup that struggled under real retrieval patterns.
@isonic_ai 𝘣𝘶𝘪𝘭𝘥𝘴 𝘈𝘐 𝘢𝘴𝘴𝘪𝘴𝘵𝘢𝘯𝘵𝘴 𝘵𝘩𝘢𝘵 𝘵𝘶𝘳𝘯 𝘢 𝘤𝘳𝘦𝘢𝘵𝘰𝘳’𝘴 𝘦𝘯𝘵𝘪𝘳𝘦 𝘤𝘰𝘯𝘵𝘦𝘯𝘵 𝘭𝘪𝘣𝘳𝘢𝘳𝘺 𝘪𝘯𝘵𝘰 𝘢𝘯 𝘪𝘯𝘵𝘦𝘳𝘢𝘤𝘵𝘪𝘷𝘦 𝘦𝘹𝘱𝘦𝘳𝘪𝘦𝘯𝘤𝘦 𝘵𝘩𝘢𝘵 𝘢𝘯𝘴𝘸𝘦𝘳𝘴 𝘲𝘶𝘦𝘴𝘵𝘪𝘰𝘯𝘴, 𝘴𝘶𝘳𝘧𝘢𝘤𝘦𝘴 𝘵𝘩𝘦 𝘳𝘪𝘨𝘩𝘵 𝘮𝘢𝘵𝘦𝘳𝘪𝘢𝘭, 𝘢𝘯𝘥 𝘩𝘦𝘭𝘱𝘴 𝘤𝘳𝘦𝘢𝘵𝘰𝘳𝘴 𝘮𝘰𝘯𝘦𝘵𝘪𝘻𝘦 𝘮𝘰𝘳𝘦 𝘦𝘧𝘧𝘦𝘤𝘵𝘪𝘷𝘦𝘭𝘺.
What stood out wasn’t just that they switched to ApertureDB, 𝗶𝘁 𝘄𝗮𝘀 𝙬𝙝𝙮.
In their benchmarks, ApertureDB 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝘁𝗹𝘆 𝗼𝘂𝘁𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗲𝗱 𝗖𝗵𝗿𝗼𝗺𝗮 on retrieval, but performance was only part of the story. They needed reliability under load, richer metadata models without arbitrary limits, and a clean path toward graph‑based retrieval as their product evolves. And they valued choosing infrastructure that won’t constrain them if they needed to introduce other modalities.
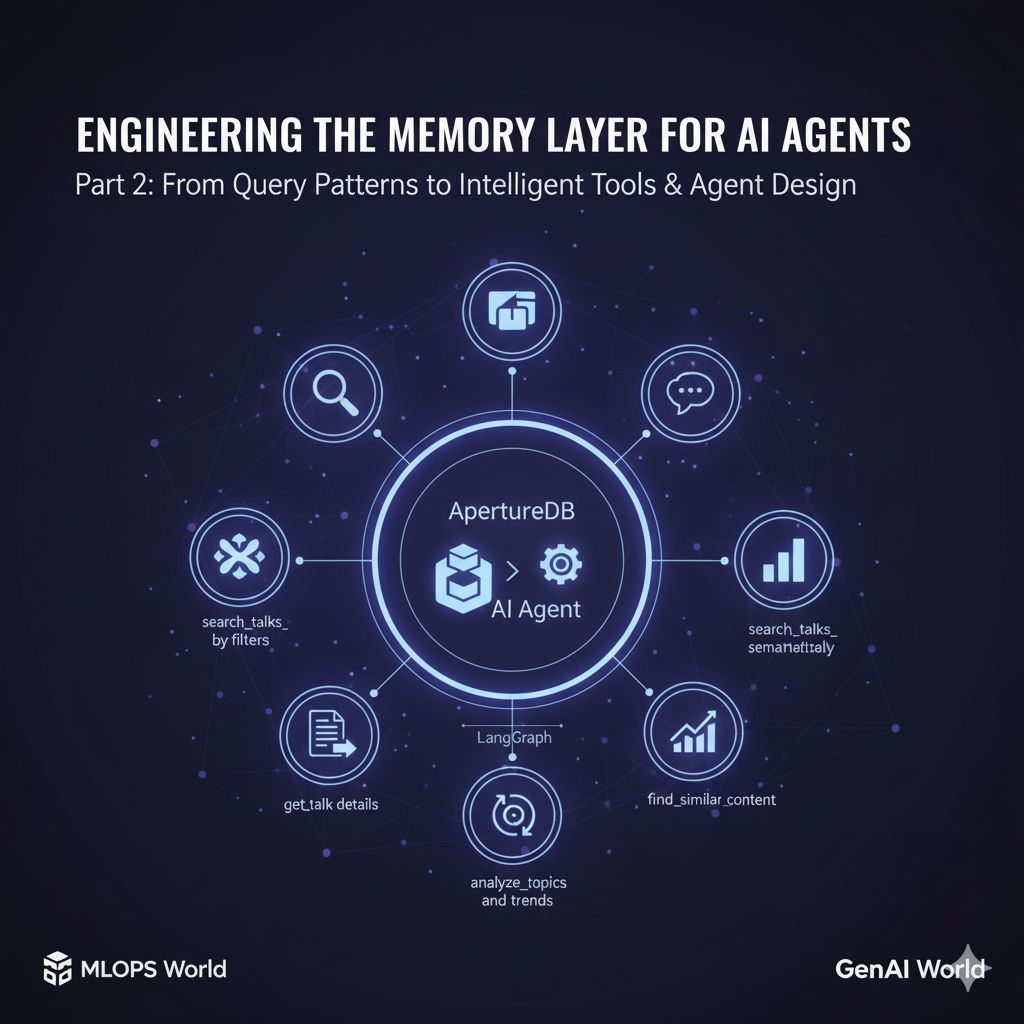
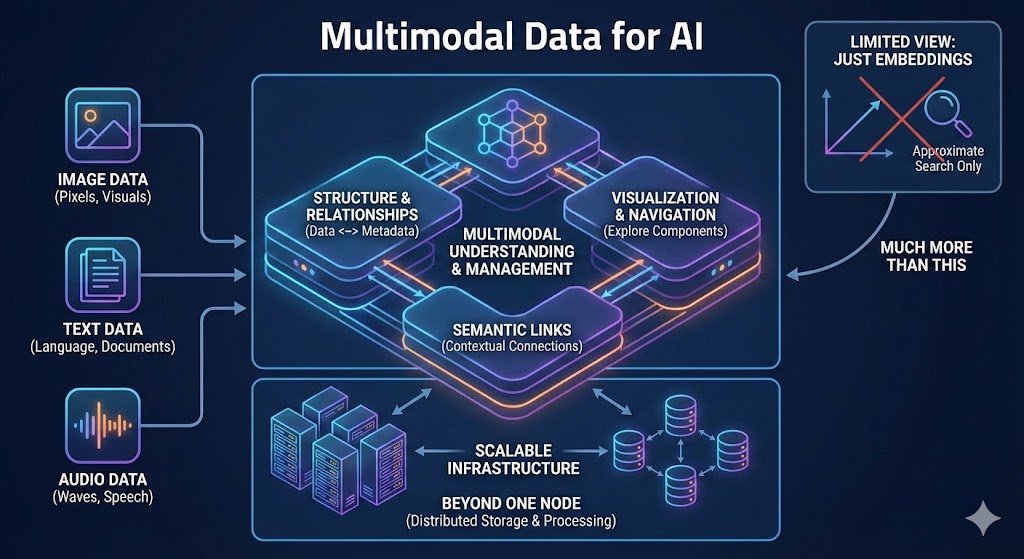
This journey mirrors what we see across teams building real production systems. 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 𝗶𝘀 𝗮 𝗽𝗼𝘄𝗲𝗿𝗳𝘂𝗹 𝗯𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗯𝗹𝗼𝗰𝗸, 𝗯𝘂𝘁 𝘃𝗲𝗿𝘆 𝗳𝗲𝘄 𝘄𝗼𝗿𝗸𝗹𝗼𝗮𝗱𝘀 𝘀𝘁𝗮𝘆 𝘃𝗲𝗰𝘁𝗼𝗿‐𝗼𝗻𝗹𝘆 𝗳𝗼𝗿 𝗹𝗼𝗻𝗴. As products mature, teams start needing:
• metadata that can grow without ceilings
• relationship‑aware retrieval
• graph‑structured context
• and the option to go multimodal when the time is right
It’s encouraging to see teams make that transition intentionally, not because a tool is trendy, but because their workloads demand more flexibility, reliability, and room to grow.
Curious how others are thinking about this shift as their retrieval and data layers mature.
@ApertureData