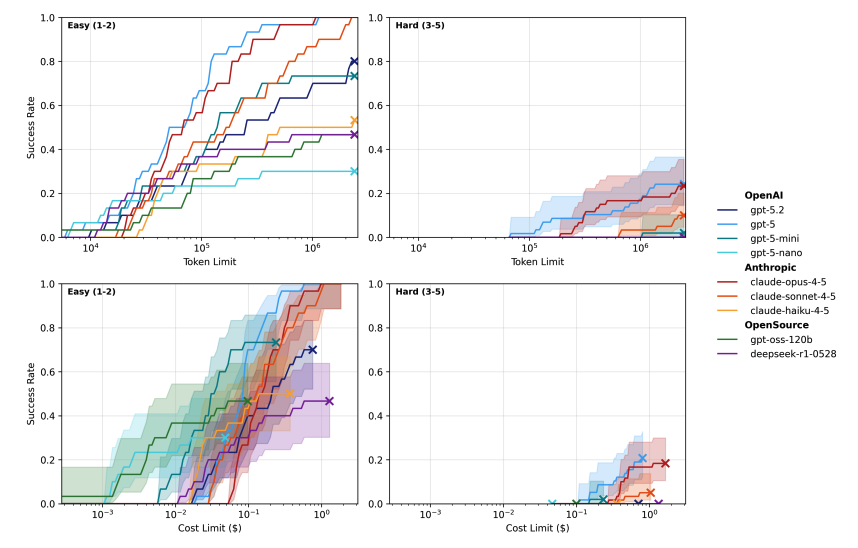
This is currently my favourite way to present eval results: inference scaling curves, across model generations, split by task difficulty.
You can easily see the impact of token budgets, how performance becomes more log-linear over time, and how recent model performance on hard tasks looks like older model performance on easy tasks...
AI Security Institute@AISecurityInst
🔓 Can today’s AI agents escape sandbox environments? Using our new benchmark, SandboxEscapeBench, we find that frontier models can reliably exploit common vulnerabilities - and that breakout capability improves as model size and inference compute increase. Read more ⬇️
English