Jorge Alberto 리트윗함

Elon Musk and SpaceX President Gwyneth Paltrow (left), 2010

English
Jorge Alberto
243 posts


@JorgeA77832
AWS SDE - opinions my own. Prev ML @ AFRL. AI infra and RL enthusiast, stonks sometimes too




I'm 22 years old and Claude Code is deteriorating my brain. Every single day for the last 6 months I've had 6 to 8 Claude Code terminals open, waiting for a response just so I can hit 'enter' 75% of the time. And it's doing something to me. In convos with a couple of friends, it's been a point that's been brought up pretty frequently. None of us feel as sharp as we used to. I don't know if it's just us, or others in their 20s are feeling the same thing, but it's something I've been thinking about a lot. P.S. I know this is a problem with my reliability/usage of it, not Claude Code itself, but the effects are real nonetheless

Virtually nobody is pricing in what's coming in AI. I wrote an essay series on the AGI strategic picture: from the trendlines in deep learning and counting the OOMs, to the international situation and The Project. SITUATIONAL AWARENESS: The Decade Ahead

you can outsource your thinking but you cannot outsource your understanding


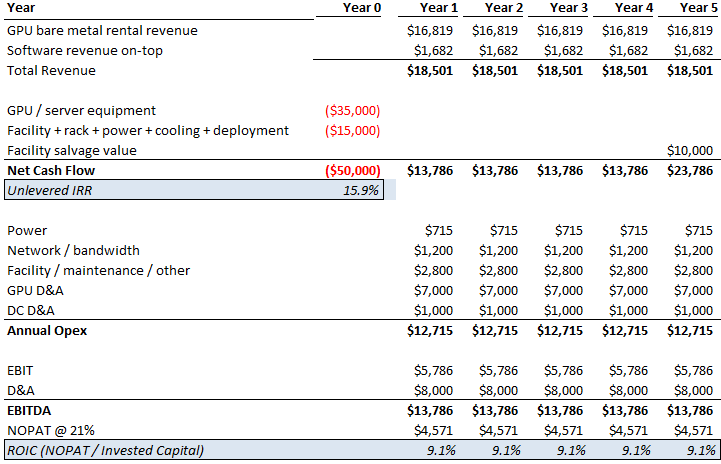
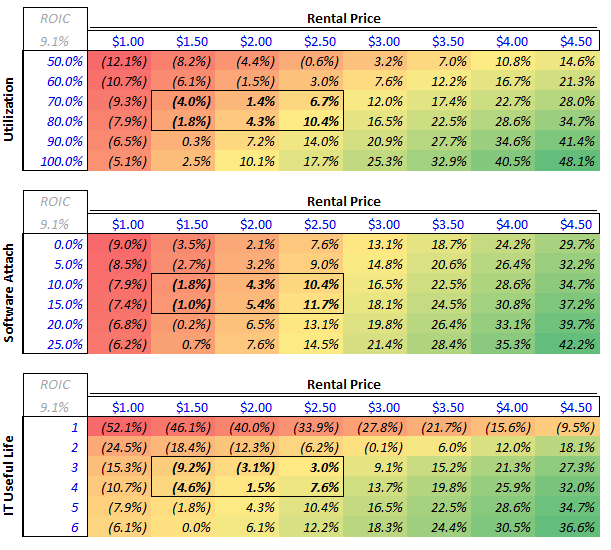
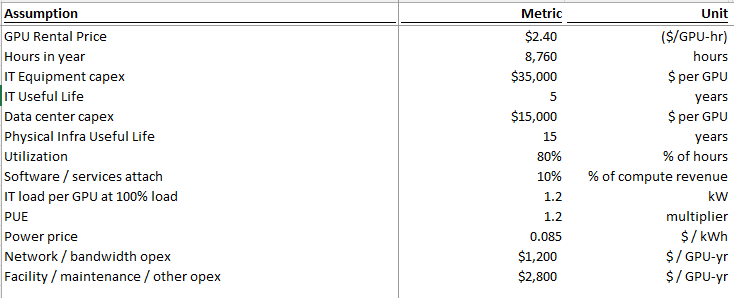
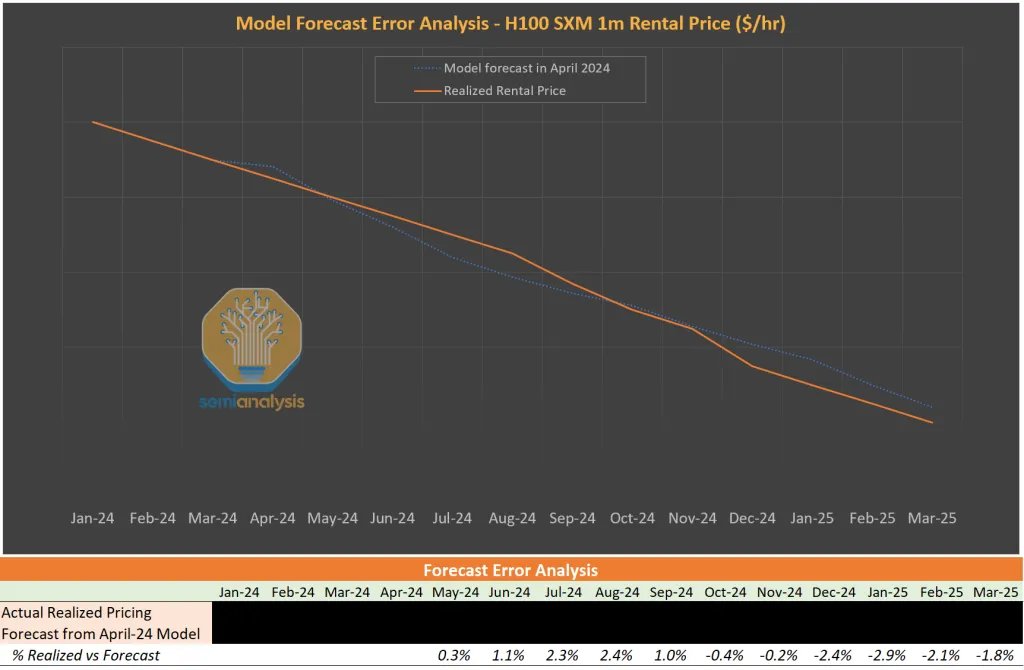
Podcast is long and info-dense (thanks both!) but worth a listen or transcript skim. Parts that stood out to me - especially on capacity, unit economics, residual value, and bottlenecks. Separate power post (after) to follow. -Lab capacity today and forward: Both OpenAI and Anthropic are at roughly 2 to 2.5 GW today. Dylan estimates both reach 5 to 6 GW by year-end, with OpenAI slightly higher. Both targeting around 10 GW by end of next year. -Anthropic revenue and implied compute need: Anthropic has been adding $4 to 6B in monthly revenue per Dylan's estimates. Straight-line that over 10 months and you get roughly $60B of incremental revenue. At sub-50% gross margins (per The Information), that implies around $40B of compute spend. At roughly $10B per GW in rental cost, that is 4 GW of new inference capacity needed just for revenue growth before any training fleet expansion. -Procurement strategy divergence: Anthropic was deliberately conservative on compute contracting. OpenAI signed aggressively and has better access to capacity into year-end. Anthropic now has to acquire capacity through Bedrock / Vertex / Foundry revenue-share arrangements or spot deals at steep premiums (Dwarkesh suggested 50% margins to the hyperscaler CSPs). Dylan has seen labs sign H100 deals at $2.40/hr for 2 to 3 year terms vs. a $1.40/hr fully loaded 5-year TCO. Standard 5-year contracts at $1.90 to $2.00 yield roughly 35% gross margins. Late-cycle short-duration contracts yield dramatically more for the provider. -Supply chain conviction decay: Labs know they need X compute. Nvidia builds X minus 1. Each layer down the supply chain builds X minus 1 again, sometimes X divided by 2. Conviction about demand attenuates at every step. Anthropic's compute team (ex-Google) spotted a dislocation and negotiated roughly 1M TPU v7s before Google leadership realized the demand. Google then went to TSMC asking for emergency capacity and was told they were sold out. -GPU depreciation thesis: Bears argue H100 spot falls to $1.00 when Blackwell scales and $0.70 when Rubin scales. Dylan argues the opposite. GPT-5.4 is cheaper to run than GPT-4, has fewer active parameters, and is far more capable. An H100 produces more tokens of a better model than it ever could before. TAM for GPT-4 tokens was maybe low billions to tens of billions. GPT-5.4 TAM is "probably north of $100B." His direct quote: "An H100 is worth more today than it was three years ago." In a supply-constrained world, GPU value is set by marginal output value, not replacement cost. -Memory crunch: Roughly 30% of Big Tech 2026 AI CapEx goes to memory. Vendors were unprofitable in 2023 and did not build fabs. Even after the demand surge became foreseeable, it took a year for pricing to move, another 3 to 6 months for vendors to react, and fabs take 2 years to build. Meaningful relief likely does not arrive until late 2027 or 2028. DRAM has roughly tripled in price. He argues this spills into consumer electronics with significant BOM pressure on smartphones, though his volume decline projections (from 1.1B to 500 to 600M units) are on the more aggressive end. -Long-run bottleneck: By 2028 to 2029, Dylan believes the binding constraint shifts to ASML EUV tools. Currently producing around 70 per year, growing to roughly 100 by end of decade. Each gigawatt of AI capacity requires about 3.5 EUV tools. That is $1.2B of tooling supporting $50B of downstream data center CapEx. The supply chain simply cannot scale fast enough.