고정된 트윗
Keming Wu
50 posts

Keming Wu
@Keming_Charles
PhD student @Tsinghua_Uni. Focus on Generative AI and VLM. Author of EditReward, OpenMMReasoner.
가입일 Eylül 2025
515 팔로잉141 팔로워
Keming Wu 리트윗함

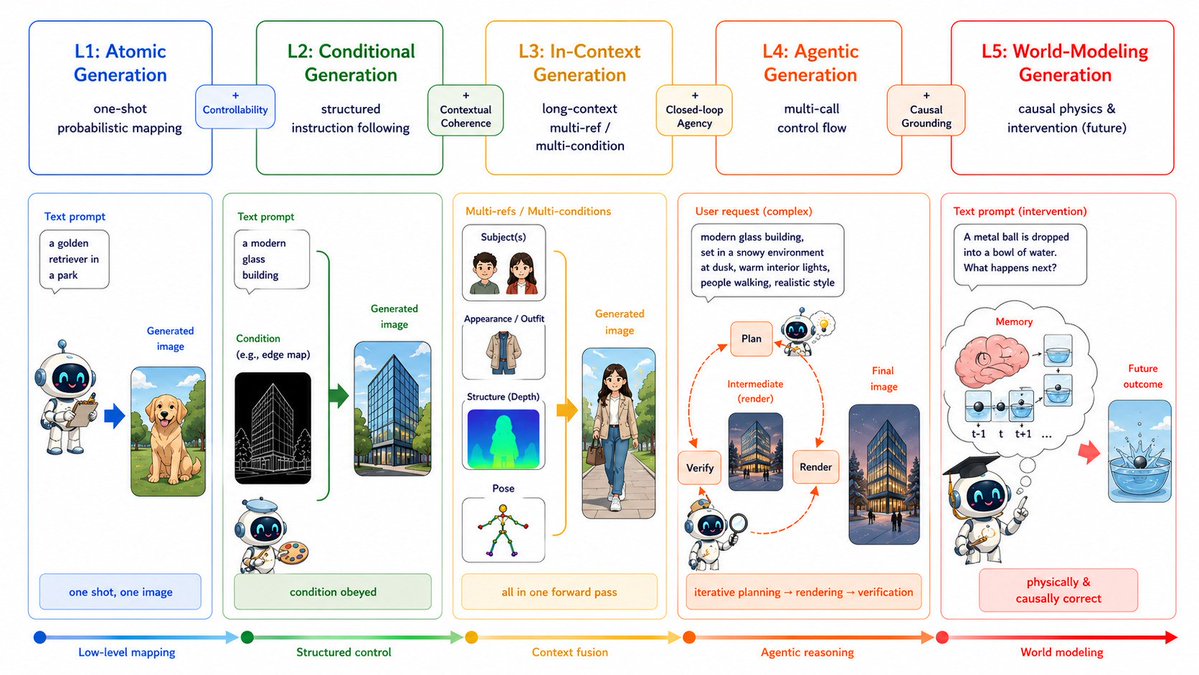
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling
Keming Wu, Zuhao Yang, Kaichen Zhang, Shizun Wang, Haowei Zhu, Sicong Leng, Zhongyu Yang, Qijie Wang, …
arxiv.org/abs/2604.28185 [𝚌𝚜.𝙲𝚅]
💬Project: github.com/EvolvingLMMs-L…

Filipino
Keming Wu 리트윗함

Excited to share a fun project I recently collaborated on: a roadmap for thinking about where visual generation is heading next. The key question is no longer just “can it make beautiful images?”, but whether it can handle memory, interaction, and eventually world modeling.
English
Takeaway:
The future is not just higher-fidelity images.
It is controllable, interactive, verifiable, and world-aware generation.
arXiv: arxiv.org/abs/2604.28185
HF Daily Paper: huggingface.co/papers/2604.28…
GitHub: github.com/EvolvingLMMs-L…
WebPage: evolvinglmms-lab.github.io/Evolving-Visua…
English
Benchmarks often reward visual quality.
But real progress also needs spatial reasoning, topology, symbolic structure, and code/math-grounded correctness.
We stress-test physical and causal reasoning:
These examples probe the boundary between image synthesis and world modeling.

English
Excited to share our new roadmap:
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling
What does it mean for image generation models to become truly intelligent?
HF Daily Paper: huggingface.co/papers/2604.28…
WebPage: evolvinglmms-lab.github.io/Evolving-Visua…
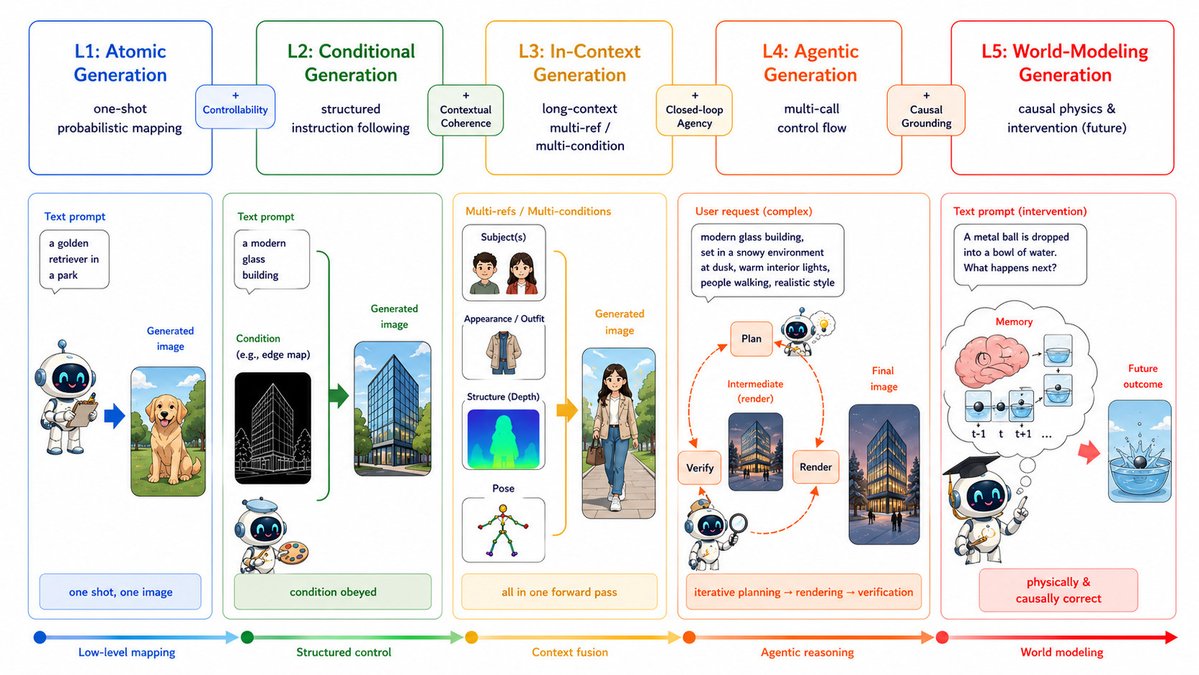
English
An insightful and excellent piece of work.
Lianghui Zhu@lianghui_zhu
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other. Since ResNet's `x + F(x)` in 2015, the depth residual has been the only highway for inter-layer communication. It's time to upgrade the staircase. 🧵
English
Keming Wu 리트윗함

The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3AS…).
We would greatly appreciate your attention and help in sharing it.
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
Keming Wu 리트윗함

We are building real intelligence into the real world.
Amigogogogo.
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English

@Keming_Charles Congrats; talented! Wishing you more great milestones! 🦾
English
Excited to announce that OpenMMReasoner is accepted to #CVPR2026 🚀
A complete open-source recipe for multimodal reasoning training!
Website: evolvinglmms-lab.github.io/OpenMMReasoner/
Open-source: github.com/EvolvingLMMs-L…
Keming Wu@Keming_Charles
🚀 Excited to share OpenMMReasoner: A complete open-source recipe for multimodal reasoning training! 📊 874K SFT + 74K RL data 🔬 Reproducible SFT pipeline ⚡ Advanced RL training (GSPO/GRPO/DAPO) 📈 +11.6% over Qwen2.5-VL-7B baseline 🧵 Thread below 👇
English
Excited to announce that LongVT is accepted to #CVPR2026 🚀
Teaching Multimodal LLMs to "Actively Look Back" and understand long videos just like humans!
Website: evolvinglmms-lab.github.io/LongVT/
Open-source: github.com/EvolvingLMMs-L…
Zuhao Yang@mwxely464
🔥 Introducing LongVT: Teaching Multimodal LLMs to "Actively Look Back" and understand long videos just like humans! We tackle the "sparse evidence" & "hallucination" issues in long-video reasoning with an end-to-end Agentic solution. Paper: arxiv.org/abs/2511.20785 More in thread
English
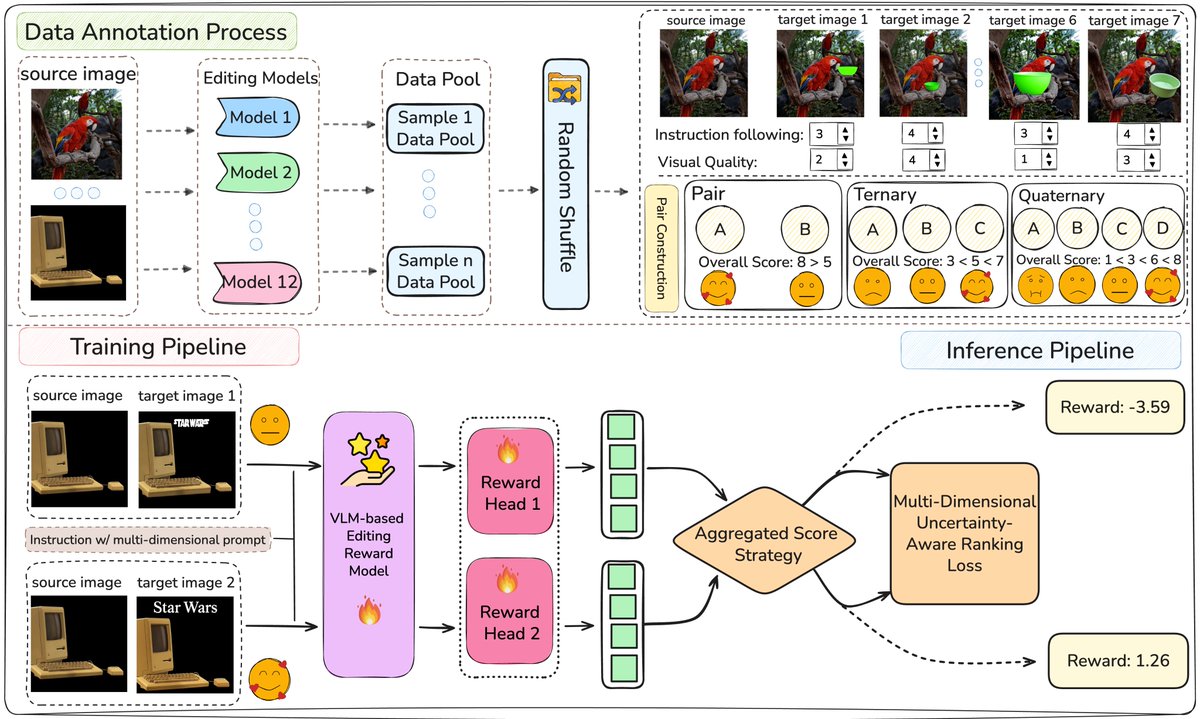
Excited to announce that EditReward is accepted to #ICLR2026 🚀
A state-of-the-art reward model that significantly improves alignment with human preferences for instruction-guided image editing.
Website: tiger-ai-lab.github.io/EditReward/
Open-source: github.com/TIGER-AI-Lab/E…
Wenhu Chen@WenhuChen
Excited to announce that TIGER-Lab has 8 papers accepted to ICLR 2026. Congrats to all the students and co-authors!
English
Keming Wu 리트윗함

@_TobiasLee Totally agree. Check out LongVT: evolvinglmms-lab.github.io/LongVT/ (eval via github.com/EvolvingLMMs-L…).
For what’s next, agentic long-video reasoning looks promising. VideoSIAH targets segment-in-a-haystack, evidence-sparse long videos with tool-integrated reasoning.
English

Don't start from scratch. Use our open-source dataset and baseline to push the boundaries of inherent editability!
👇
Code: github.com/redredsheep/Pr…
Data: huggingface.co/artplus
Paper: arxiv.org/abs/2505.22523
#DeepLearning #Dataset #DiffusionModels #AIart︎ #MultiLayer
English
