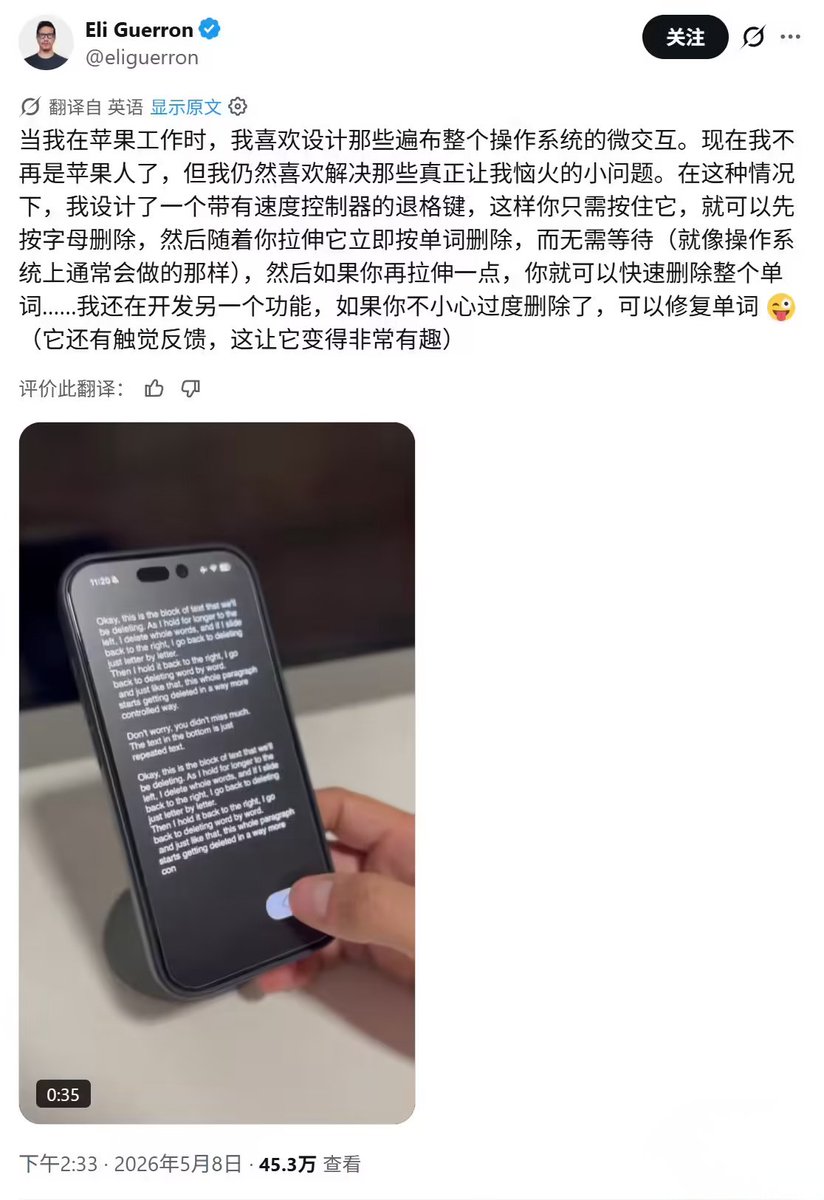
@Baconbrix i wonder if it can simulate getting stuck in traffic jams for testing
English
Neural Times
629 posts

@Neural_Times
AI is moving faster than you think breaking news before it trends no fluff.

Meet Higgsfield CLI + Marketing Skills. Instead of burning tokens on bloated schemas, or shipping broken creative at scale, the CLI keeps agent spend lean and Skills keep output high quality. Pairs with Сodex, Claude Code, Openclaw etc. npx skills add higgsfield-ai/skills




Your Claude can be 10x smarter. For free. This skill uses subagents ("monkeys") to attack problems from novel angles, judge the results, and preserve the input-output chain. It builds a knowledge base of how good results are produced, so it can do better in the future. github.com/nstied/monkeys…
ERNIE 5.1 just dropped. Built on ERNIE 5.0's pre-training foundation, our latest foundation model upgrades search, reasoning, knowledge Q&A, creative writing, and agentic capabilities, while using only around 6% of the pre-training cost of comparable models. More in the thread 🧵




Over the past year, AI agents have learned how to self-replicate. In our test environment, an agent hacks a remote computer and copies itself onto it. Each copy then hacks more computers, forming a chain.


The next form of world intelligence. Coming soon.