고정된 트윗

Cuántas horas pasaste hoy mirando pantallas?
No lo recuerdas, ¿verdad?
Nadie lo recuerda.
Porque ALGO se aseguró de ello.
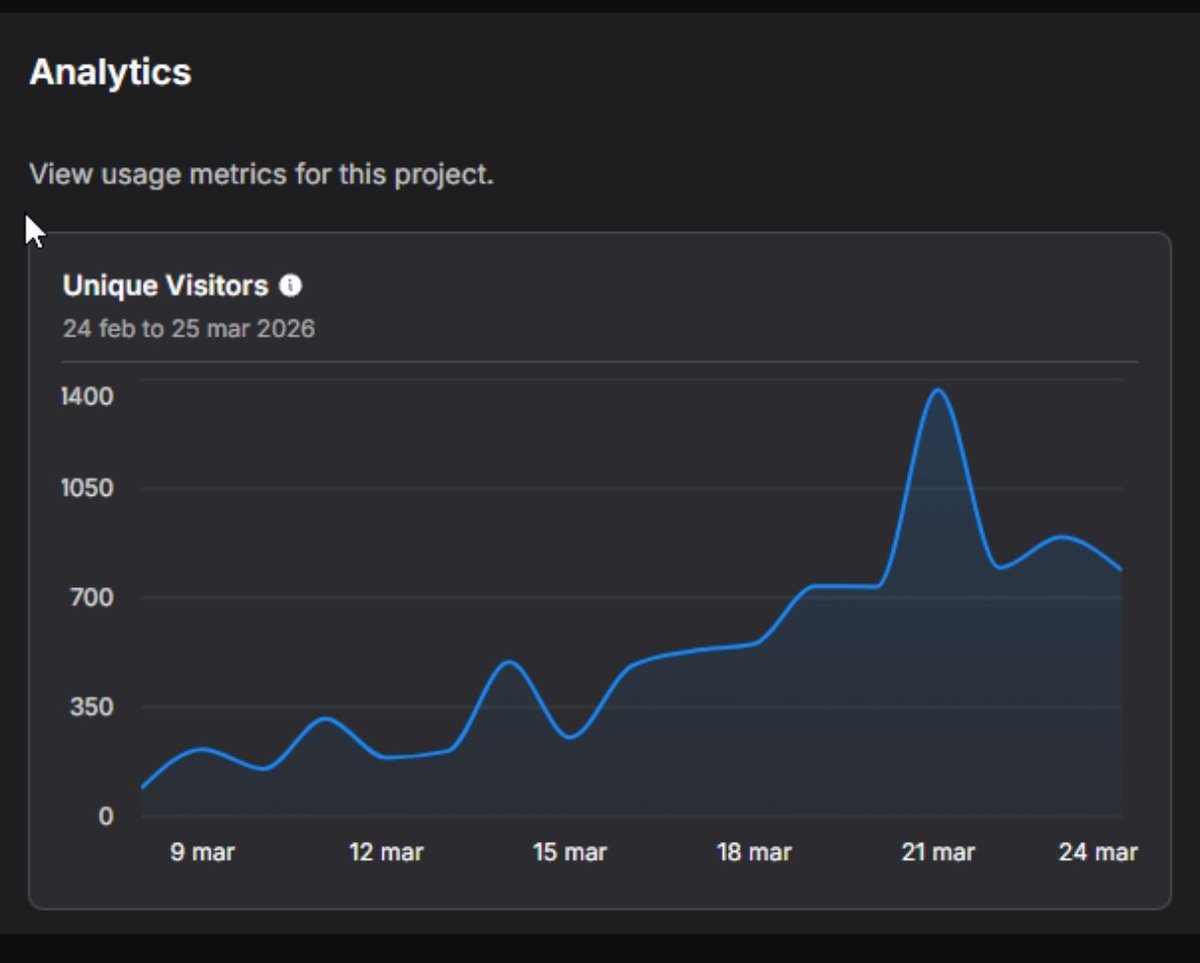
En 2025, la humanidad pasa 11 horas diarias optimizada por algoritmos.
No vivimos.
Scrolleamos.
No pensamos.
Consumimos.
No conectamos.
Damos likes.

Español