@sama GPT-5.5 is currently the world’s most intelligent model, providing an ample usage quota
English
Singularabbit
179 posts

@Singularabbit
2026 AGI | AI tinkerer & benchmarker 🐰 | Singularity via code





Done. Codex and images 2.0 cooked
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!




( #appleinternal ) Apple Internally uses an application that looks pretty similar to ChatGPT named AFM Playground, which uses Apple’s Foundation Models instead. A few more images below
GPT-5.5 is on par with Claude Mythos - GPT-5.5 average pass rate of 71.4% (±8.0%) - Mythos Preview 68.6% (±8.7%) - GPT-5.5 solved a task that takes a human expert ~12 hours in under 11 minutes at a cost of $1.73






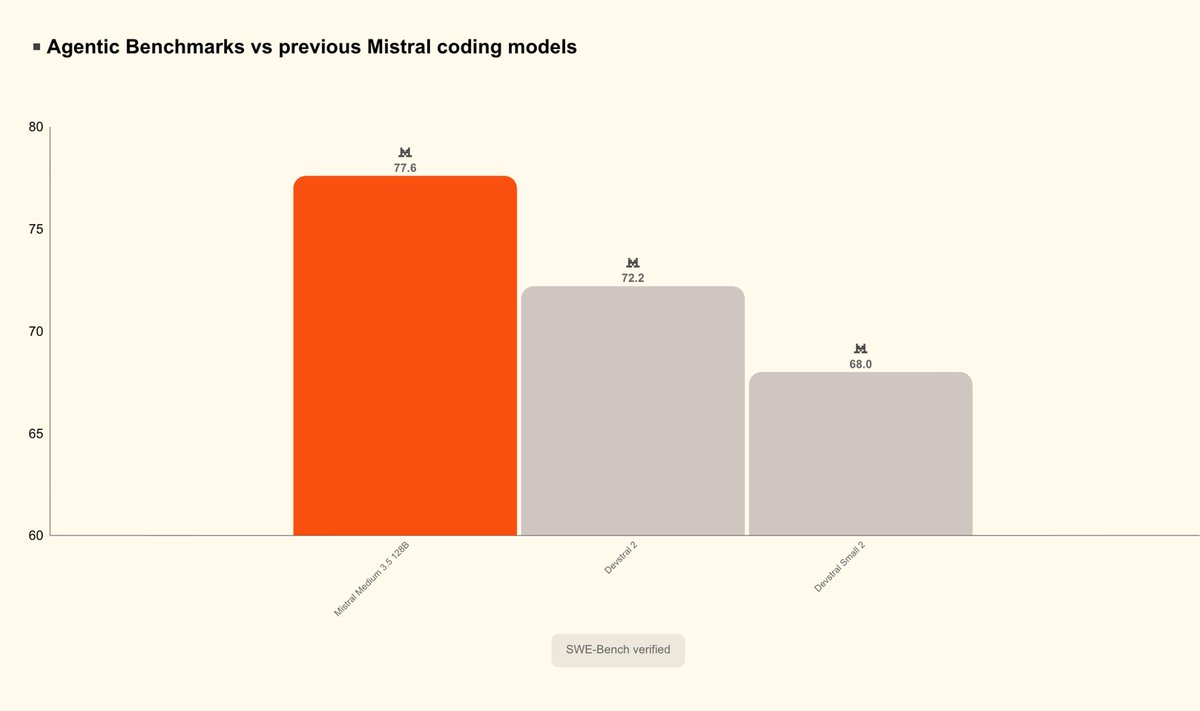
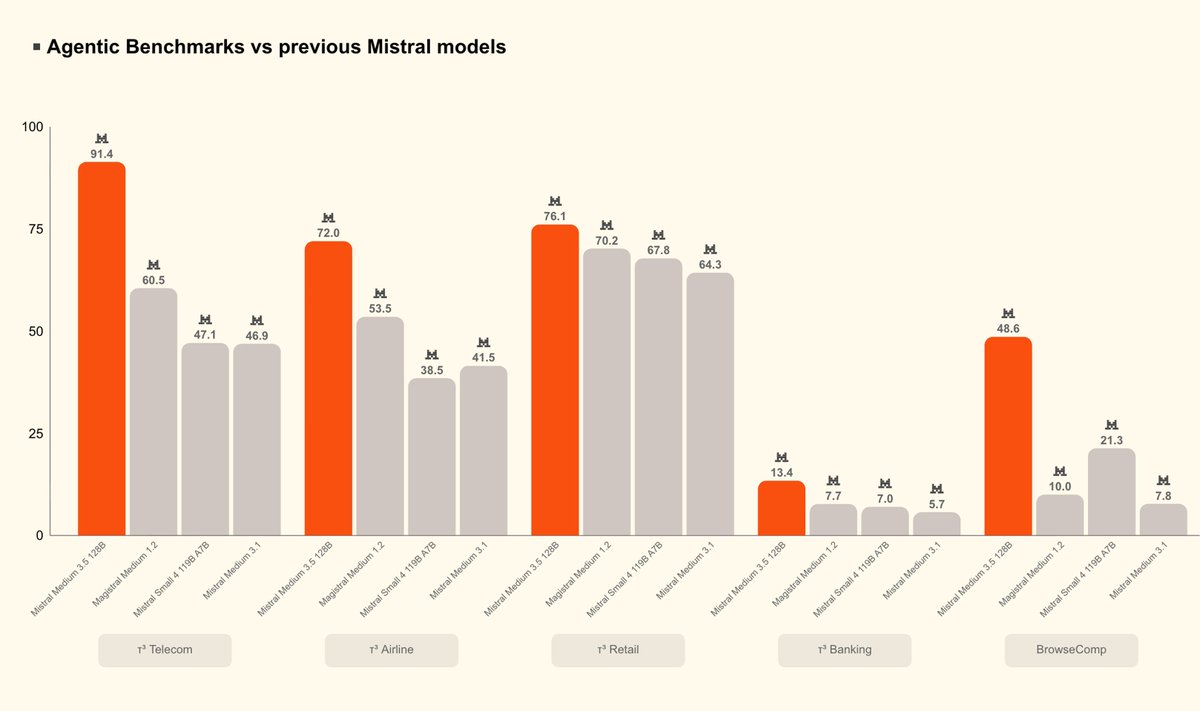
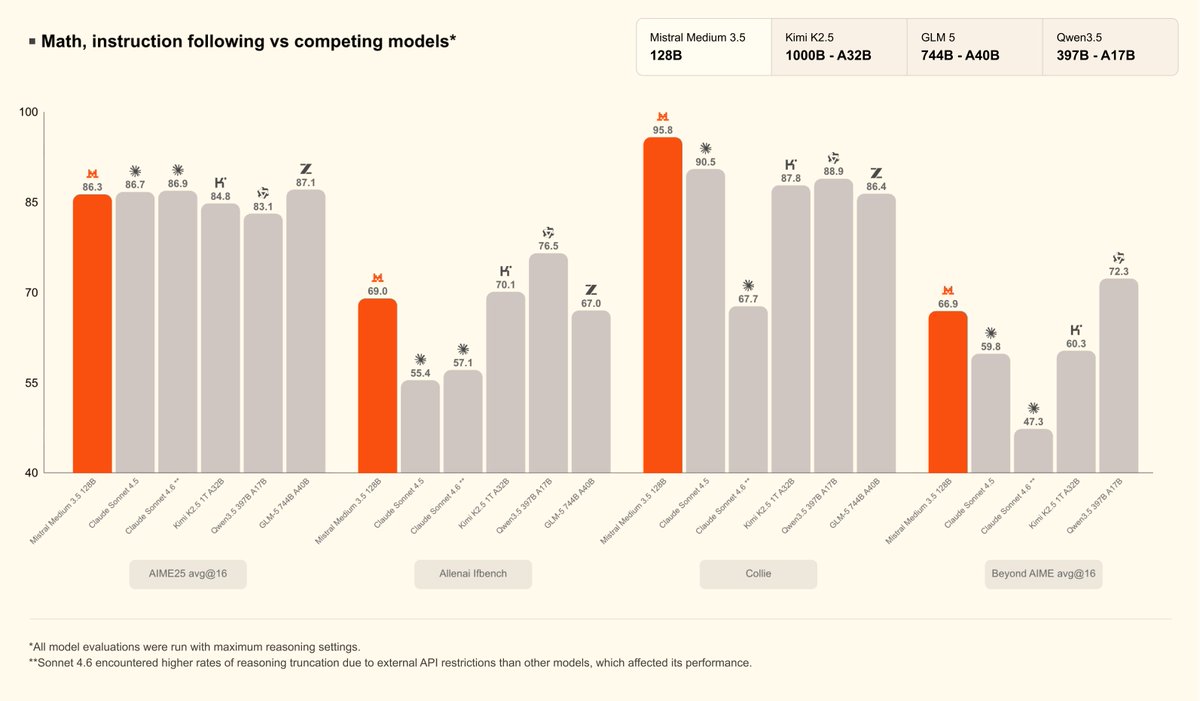
Mistral Medium 3.5, a new flagship model in public preview by @MistralAI that merges instruction-following, reasoning, and coding into a single 128B dense model with a 256k context window and configurable reasoning effort. It's a new default model for Mistral Vibe and Le Chat. Released as open weights, under a modified MIT license.