@boringmarketer the 244-models-one-key part is the real unlock. half the friction of agentic workflows is just key management
English
Steven Zaa
1.2K posts

@StevenACZ
Building cross-platform apps I actually use daily 3 apps shipping 👉 https://t.co/kWZDEM9Tzi

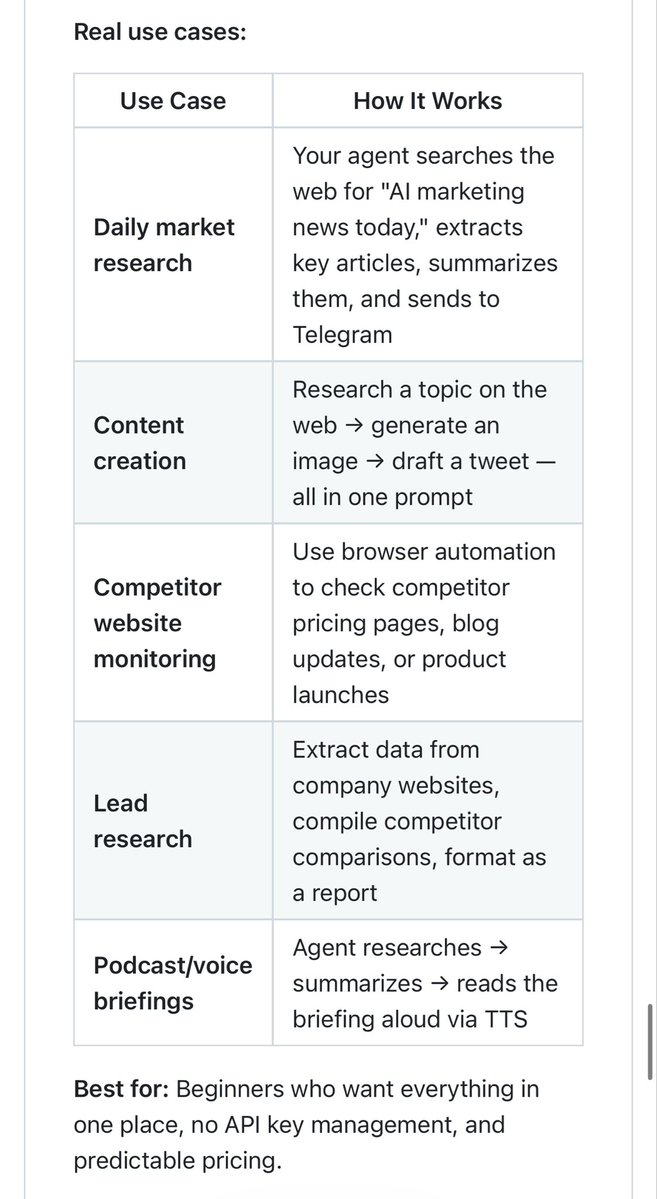







[1/4] The human eye doesn't process every single pixel of a video continuously—it focuses on what changes. So why are our video AI models wasting compute on redundant frames? Introducing Swift Sampling: a test-time technique inspired by the human visual system. 🧠👇




This guy built a local "video -> HLS -> R2" to pipeline, which is cool, but he uses an FFmpeg script to do it. The same task could've been achieved with Mediabunny in about ~10 lines of code, would not need a script, and would probably run 5x faster due to proper HW acceleration. The thing is: it's not like he didn't use Mediabunny because he hated it. He probably just didn't know Mediabunny existed or that it could do this. Marketing really is hard!



This might be a hot take but I know someone at meta who makes $400k a year and is quite literally capped at that number for life - likely will never get a promotion strong enough to change that. 9-5 until they’re what, 50? This is not living. No matter the salary.