No more waitlist. The GitHub Copilot app's technical preview is now available to everyone currently on Copilot Pro, Pro+, Max, Business, and Enterprise plans.
This agent-native desktop experience lets you decide what agents work on, how they work, and what ships. Go from issue to merge all in one place. ✨
Introducing Harness-1, a 20B search agent trained with a state-externalizing harness.
> frontier-level long-horizon search, rivaling Opus-4.6 and outperforming GPT-5.4
> Context-1-level cost and latency
> externalizes candidates, evidence, verification, and search history
> open-source
New course on serving LLMs efficiently -- how do you serve models to many concurrent users at low latency and reasonable cost? This short course is built with @RedHat and taught by @cedricclyburn.
Efficient LLM serving requires efficient memory management. A 70B-parameter model takes ~140 GB just to load the weights. On top of that, every active request needs its own chunk of GPU memory, the KV cache, to store the token context it has built up so far. In this course, you'll learn to reduce a model's memory footprint with quantization and serve it using vLLM, which handles many concurrent requests efficiently through smart memory management.
Skills you'll gain:
- Quantize a model and measure the accuracy tradeoff
- Serve a model with vLLM and watch it handle concurrent requests efficiently
- Benchmark your deployment and make informed tradeoffs between speed, cost, and accuracy
Join and learn to serve LLMs efficiently:
deeplearning.ai/courses/fast-a…
Ai Engineering from Scratch comes with 30+ Capstone Projects!
Why they're special.
You learn to build your own GPT, LLM, OPENCLAW, AGENT, HARNESS, and many more.
aiengineeringfromscratch.com
If you found this post helpful, follow me for more content like this.
I publish a weekly newsletter where I share practical insights on data and AI.
It focuses on projects I'm working on + interesting tools and resources I've recently tried: alexeyondata.substack.com
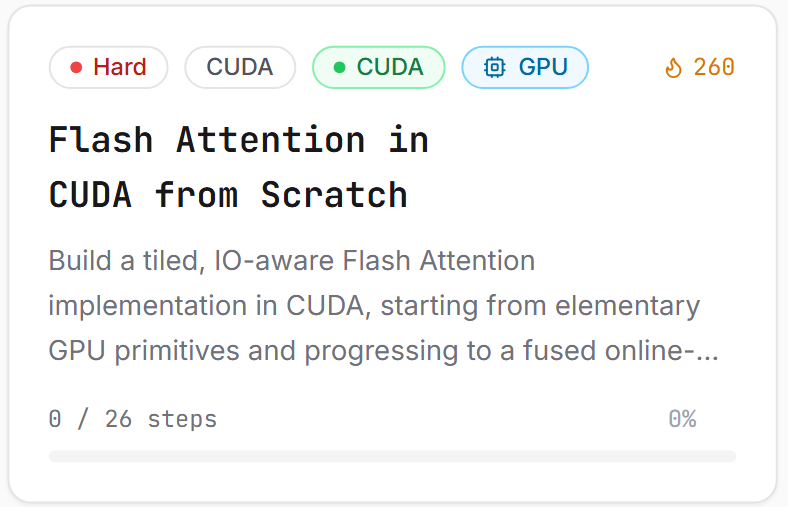
We just launched a new project that teaches you how to build Flash Attention with CUDA, step by step.
By the end, you’ll have a working Flash Attention kernel built from the ground up.
The project covers:
-CUDA primitives warm-up
-Matrix operations
-Naive attention baseline
-Online softmax math
-Tiled attention building blocks
-Fused Flash Attention kernel
-Causal Flash Attention
It will be open to everyone for the first 2 weeks, then it will become part of our premium projects.
For curious developers 🧠
I built "The Anatomy of an LLM", an interactive explainer showing how text becomes tokens, vectors, attention, transformer blocks, and finally generated text.
royvanrijn.com/anatomy-of-an-…
Build your own GPT model from scratch using only NumPy.
We broke the process down into small, approachable problems that each take around 2–20 minutes to solve.
The goal: make it possible for anyone to not just build a GPT, but truly understand how it works under the hood.
By the end, you’ll walk away with code that can train a GPT model from scratch.
new in-depth blog post time: Inside the Transformer: The Life of a Token
a deep dive into a modern dense transformer, i cover YaRN (why does pairwise coordinate rotation induce positional information?), hybrid attention (getting to 160k context length), soft capping, QK normalization, etc. as the token flows through the transformer
bonus transformer math: FLOPs/token formula (and when is 6N formula broken), cluster sizing (how big of a cluster do you need given the model/data size and experiment throughput of interest), and more
DROP EVERYTHING
The ultimate step-by-step projects roadmap for BECOMING an AI Researcher is now available online to read FOR FREE
Covers building
- Tokenizers / embeddings
- Positional methods
- Attention / multi-head attention
- Transformer blocks
- Training loops / objectives
- Sampling dashboards
- Speculative decoding
- KV cache / MQA / GQA / MLA
- Long context
- FlashAttention / hardware budgets
- MoE routers
- State-space / diffusion LMs
- Data pipelines / synthetic data
- Scaling laws
- SFT / DPO / RLHF / GRPO / RLVR
- Quantization
- Serving systems
- Evaluation harnesses
- RAG / tools / agents
- Multimodal adapters
- Interpretability / safety
- Full capstone model system
The loop for every project
- Build it
- Plot it
- Break it
- Explain it
- Ship the artifact
You should read this, and if you cannot now then you most definitely wanna bookmark it for later
DM me when you're working at a frontier lab
New course: Build agents that respond to users with not only plaintext, but custom UIs like charts, forms, and whiteboards, generated on demand and displayed right in the chat. This short course is built in partnership with @CopilotKit and taught by @ataiiam, co-founder of CopilotKit.
You'll learn three approaches: Your agent can pick from custom components you build, like charts and forms. It can compose new layouts from a set of building blocks you provide, like rows, cards, and text. Or it can incorporate existing third-party apps, like a whiteboard or a calendar, right inside the conversation.
Skills you’ll gain:
- Build agents that render custom components like charts and forms on demand
- Build an app where the agent and user collaborate on shared data, beyond just the chat window
- Place third-party apps like maps, calendars, and whiteboards right in your interface
Join and build agents that give users something to see and act on! deeplearning.ai/short-courses/…
- Math behind Attention - Q, K, and V
- Math behind √dₖ Scaling Factor in Attention
- Math Behind Backpropagation
- Math Behind Gradient Descent
- Math Behind Cross-Entropy Loss
- Math Behind RoPE (Rotary Position Embedding)
- RMSNorm (Root Mean Square Layer Normalization)
INCREDIBLE
The MOST COMPLETE GUIDE for understanding LLMs from first principles is now available online to read for free
Covers the model mechanics
- Tokens / tokenizers
- Transformers
- Attention
- KV cache
- Prefill vs decode
- Decoding controls
- Model packages
- Chat templates
- Long context
- RAG
- Agents / tools
- Fine-tuning
- Multimodal models
Then connects that to running models locally
- What "local" really means
- Open-weight vs opensource
- Quantization
- VRAM math
- Hardware tiers
- File formats / load safety
- Runtimes / serving modes
- Model selection
- Privacy
- Failure modes
- Benchmarks
- Practical setup paths
You should read this, and if you cannot now then you most definitely wanna bookmark it for later
Opensource AI FTW
open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵
These 9 lectures from Stanford University are the BEST for anyone wanting to learn and understand LLMs in depth
Lecture 1 - Transformer: lnkd.in/dGnQW39t
Lecture 2 - Transformer-Based Models & Tricks: lnkd.in/dT_VEpVH
Lecture 3 - Tranformers & Large Language Models: lnkd.in/dwjjpjaP
Lecture 4 - LLM Training: lnkd.in/dSi_xCEN
Lecture 5 - LLM tuning: lnkd.in/dUK5djpB
Lecture 6 - LLM Reasoning: lnkd.in/dAGQTNAM
Lecture 7 - Agentic LLMs: lnkd.in/dWD4j7vm
Lecture 8 - LLM Evaluation: lnkd.in/ddxE5zvb
Lecture 9 - Recap & Current Trends: lnkd.in/dGsTd8jN
Start understanding LLMs in depth from the experts. Go through each step-by-step video
Start understanding LLMs in depth from the experts. Go through each step-by-step video