고정된 트윗

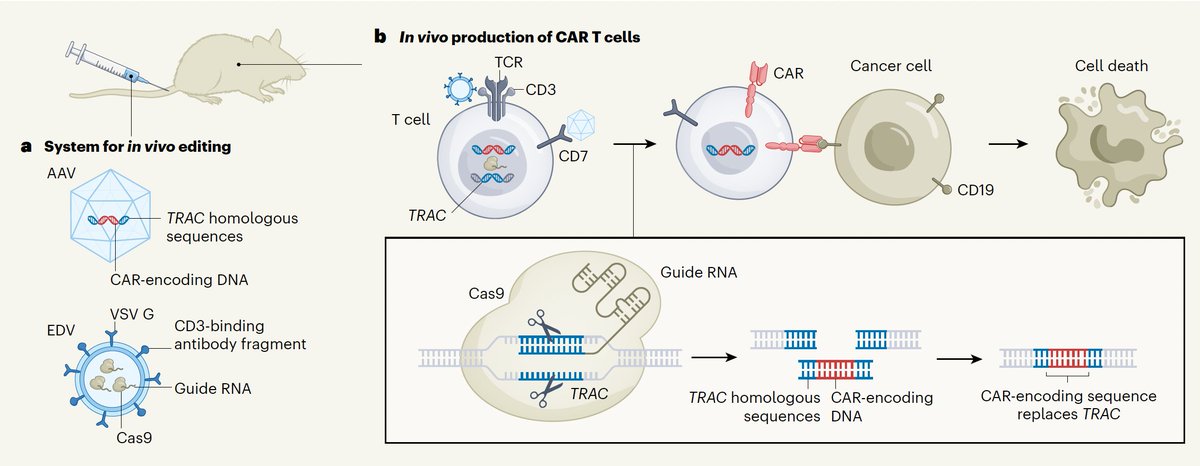
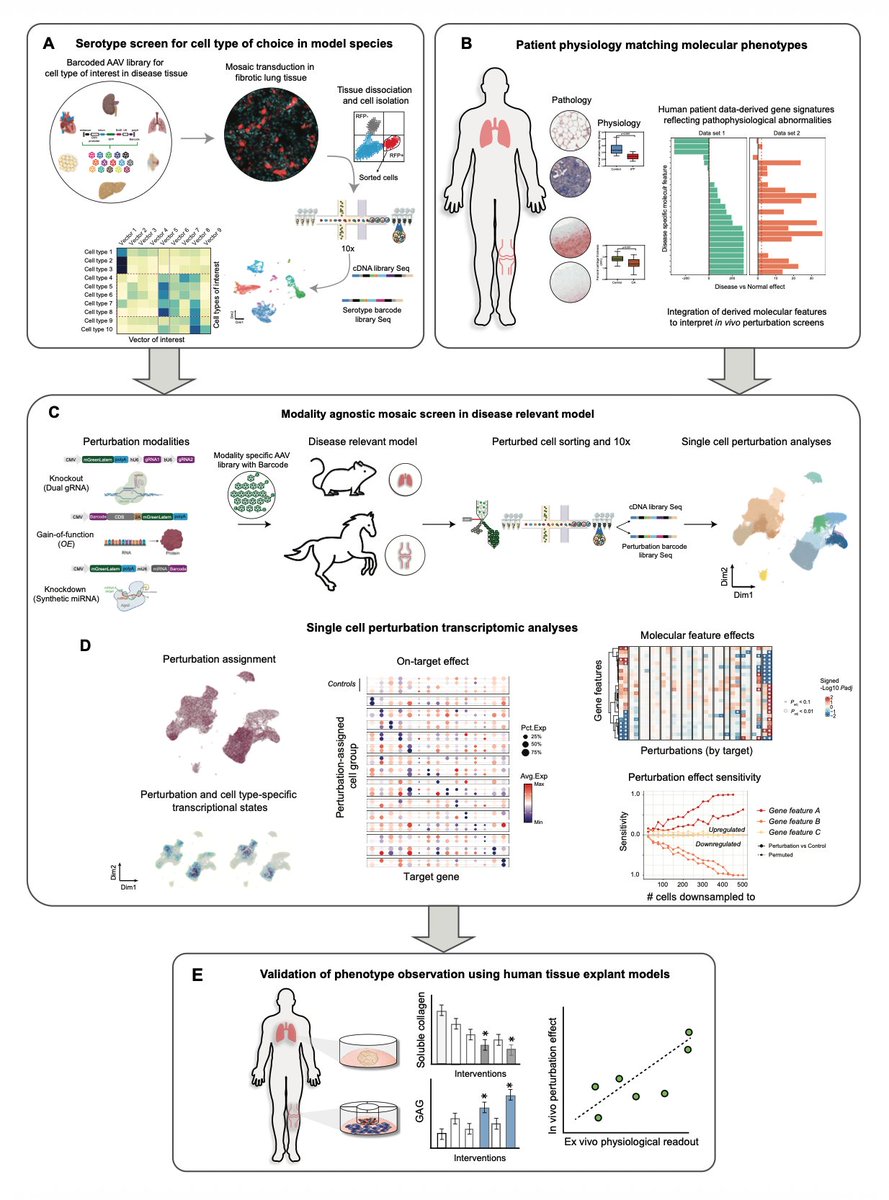
Why test #celltherapies one-by-one when you can use multiplexed #SynBio, #proteinengineering & #ML to design, measure & track them at scale?
The Goodman Lab @PennMedicine opens July 2025. We’re hiring Specialists & Postdocs!
Apply @ bit.ly/42BnJNJ
RTs appreciated!🙏

English