Dylano Jr. de Bro
10.9K posts


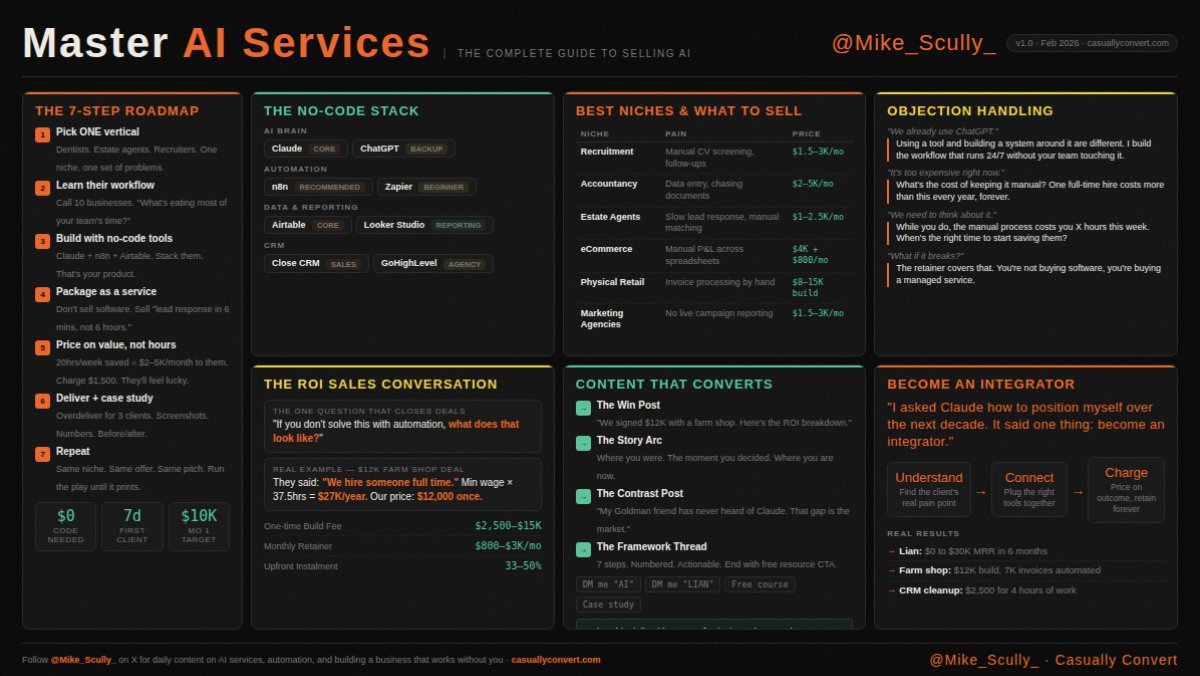
I condensed everything I know about selling AI services into one cheat sheet.
- Niche selection.
- Tech stack.
- ROI conversations that close deals.
- Objections and exactly how to handle them.
Free. Just save it.
If you want the full breakdown of how to go from zero to your first $10K month using this framework, drop "AI" in the comments and I'll send you the playbook.
(Must follow so I can dm you)
English


The next step after Karpathy's wiki idea:
Karpathy's LLM Wiki compiles raw sources into a persistent md wiki with backlinks and cross-references.
The LLM reads papers, extracts concepts, writes encyclopedia-style articles, and maintains an index. The knowledge is compiled once and kept current, so the LLM never re-derives context from scratch at query time.
This works because research is mostly about concepts and their relationships, which are relatively stable.
But this pattern breaks when you apply it to actual work, where context evolves across conversations constantly, like deadlines, plans, meetings, etc.
A compiled wiki would have a page about the project but it wouldn't track ground truth effectively.
Tracking this requires a different data structure altogether, which is not a wiki of summaries, but a knowledge graph of typed entities where people, decisions, commitments, and deadlines are separate nodes linked across conversations.
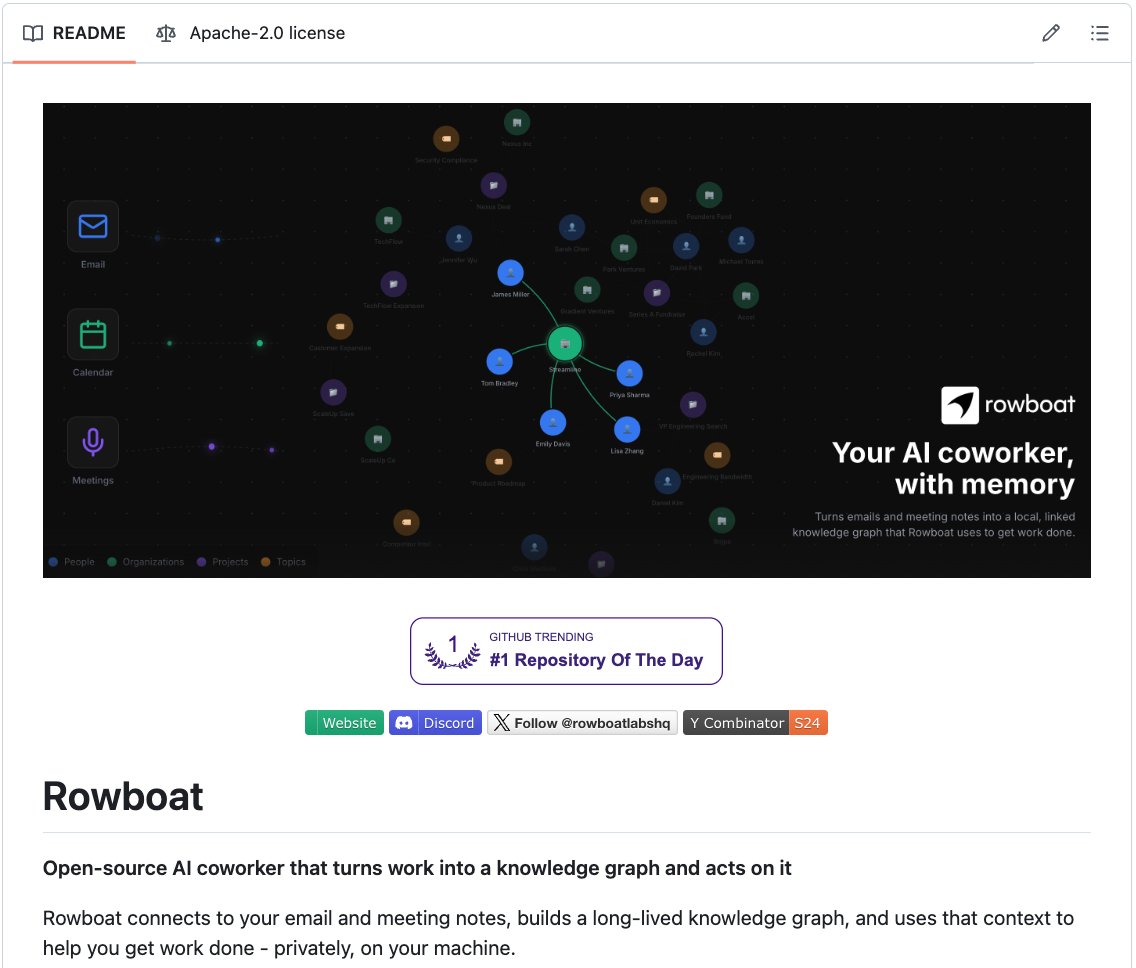
Rowboat is an open-source implementation of exactly this, built on top of the same Markdown-and-Obsidian foundation that Karpathy uses, but extended into work context.
The way it works is that it ingests conversations from Gmail, Granola, and Fireflies, and instead of writing a summary page per topic, it extracts each decision, commitment, and deadline as its own md file with backlinks to the people and projects involved.
That's structurally different from a wiki, because a wiki page about "Project X" gives you a summary of what was discussed.
A knowledge graph gives you every decision made, who made it, what was promised, when it was promised, and whether anything has shifted since.
It also runs background agents on a schedule, so something like a daily briefing gets assembled automatically from whatever shifted in your graph overnight. You control what runs and what gets written back into the vault.
You bring your own model through Ollama, LM Studio, or any hosted API, and everything is stored as plain Markdown you can open in Obsidian, edit, or delete.
Repo: github.com/rowboatlabs/ro…
TL;DR: Karpathy's LLM Wiki compiles research into a persistent Markdown wiki. It works well for concepts and their relationships but breaks down for real work where the context evolves over time. Rowboat builds a knowledge graph instead of a wiki, extracts typed entities with backlinks, and runs background agents that act on that accumulated context. Open-source, local-first, bring your own model.Karpathy nailed the foundation. The next layer is here.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@film_mars @thetransportcr Holy shit this is written horribly. As if I’m reading the thoughts of a little girl on here Facebook.
English



how did rocky know what grace looked like to send him the miniature when he needs echolocation to visualize but space is a vacuum where sound cant travel or am i misremembering the timeline/don't know how space works
English
@hanneke_z @YungFierens nji.nl/system/files/2…
Lees dit eerst. Daarna zelf onderzoek doen, zoek op ‘prenatale hechtingsproblemen bij geadopteerde kinderen’.
Nederlands

@YungFierens Maar dat vraag ik me dus af. Wat herkent een baby, aangezien er heel veel anders is in de buitenwereld. Bijvoorbeeld wat je noemt, geur, die is niet hetzelfde. Is er onderzoek gedaan naar kinderen die op deze manier worden "overgedragen"?
Nederlands

Weggerukt worden van de moeder, stem, geur, het geluid van haar hartslag is extreem traumatisch voor een baby. Degenen die hier schoonheid in zien, hebben geen idee van de gevolgen van scheidingstrauma en hoe dit de ontwikkeling van het kind levenslang beïnvloedt.
NOLLY@omoelerinjare1
After losing her son and going through countless rounds of IVF, she felt like the family they had dreamed of their whole lives would never come true. No hug and no words could give her the hope and strength she needed to keep going. If you’re feeling the same right now, my love — watch this. You’re not alone. You will get there.
Nederlands



@Fransisca1945 @MiesBee Contrast is omhoog gegooid waardoor de eieren zo kleurrijk zijn
Nederlands





Influencer (23) gepakt voor maken porno op Bali: riskeert tot 16 jaar cel #Echobox=1774010358" target="_blank" rel="nofollow noopener">telegraaf.nl/buitenland/inf…

Nederlands
leip
Yann LeCun@ylecun
Unveiling our new startup Advanced Machine Intelligence (AMI Labs). We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company. We're hiring! [the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling] More details here: techcrunch.com/2026/03/09/yan…
Lietuvių

Holy shit... someone just proved you can 10x prompt quality by adding one sentence.
It's called negative prompting and it quietly kills the "basic prompting" era.
Here's how it works (and why this changes everything):

English

@j_sperd__rcks Deze hele serie hoorcolleges is de meest insane shit die ik de afgelopen tijd heb gezien.
youtube.com/playlist?list=…
Nederlands


@44cj5tf9y9 @ConflictW95 @IranObserver0 Not true. It means chain of command and decision making is made by local command
English

@ConflictW95 @IranObserver0 No dummy. It means the chain of command has broken down and nobody wants to step up and be a target. It’s like saddam telling his troops to switch to an insurgency.
English

🚨🚨🚨 IRAN has activated Decentralized Mosaic Defense giving commanders full autonomy for decision making
English
@ADnl Wat een debiel plan. Hoogopgeleide- en goed verdienende vrouwen beginnen over het algemeen vrij laat aan kinderen, dit is weer een extra reden voor uitstel. Spijtig.
Nederlands

Wie straks met zwangerschapsverlof gaat, krijgt maandelijks een stuk minder uitgekeerd. Ook de uitkering voor ouderschapsverlof gaat omlaag ad.nl/economie/zwang…
Nederlands
@EdwinOosterhoff Internationaal recht faalt niet incidenteel, het mist structureel afdwinging. Zonder handhavingsmacht blijven veroordelingen papier en arrestatiebevelen symboliek. Dat is geen schild tegen agressie of onderdrukking. Hoe ga je morele statements serieus nemen als er een bom afgaat?
Nederlands

@GinodeRobles @Daytona3521 Je probeert het gesprek te verplaatsen van feiten naar speculatie omdat je inhoudelijk niets hebt om het patroon van staatsgeweld te ontkennen. Mossad/CIA zonder bewijs is geen analyse maar coping. Triest
Nederlands

@Daytona3521 1. Waar komen die cijfers vandaan? 2. Hoeveel zijn er gedood door het regime en hoeveel door agenten van de Mossad en de CIA? En voordat je dat in twijfel gaat trekken, het is al toegegeven door ‘Israëlische’ functionarissen.
Nederlands
40 meisjes (and counting) op een meisjesschool vermoord door de alliantie VS-‘Israël’, maar dat mag de pret op het Malieveld niet drukken.
Bob van Keulen@BobHGL
Grote vreugde op het Malieveld. Demonstratie op het Malieveld tegen het regime van Iran op de dag dat Israël en de Verenigde Staten zijn begonnen met aanvallen op #Iran #Teheran Islamic Regime ☀️🦁
Nederlands
@mntll80 @rick_tweets Mijn punt blijft simpel: regels zonder consistente handhaving verliezen legitimiteit. Dat zie je bij Rusland, Iran en andere staten. Dáár zit mijn kritiek. Als je dat na dit hele gesprek nog steeds niet ziet, ligt het probleem waarschijnlijk niet bij de uitleg. 🫧🫧🫧
Nederlands

@dylanderoo @rick_tweets Ik reageer al sinds je eerste bericht inhoudelijk, maat. Dat jij het niet kunt begrijpen, daar kan ik niets aan doen. Maar blijf vooral stug volhouden. Helemaal niet treurig gelukkig.
Nederlands
@mntll80 @rick_tweets Maat. Dat zeg je om niet inhoudelijk te hoeven reageren. Vanaf mijn eerste bericht wijs ik op jouw selectieve handhaving. Jij blijft doen alsof ik tegen regels ben. Dat is geen argument, dat is ontwijken. Inhoudelijk heb je nog 0 gezegd. Alleen verwijten. Treurig.
Nederlands
@dylanderoo @rick_tweets Daar had jij vanaf je eerste bericht al last van…
Nederlands