GDP@bookwormengr
DeepSeek V4 hits it out of the park and addresses HBM shortage:
DeepSeek proves why it is such a fundamental research lab.
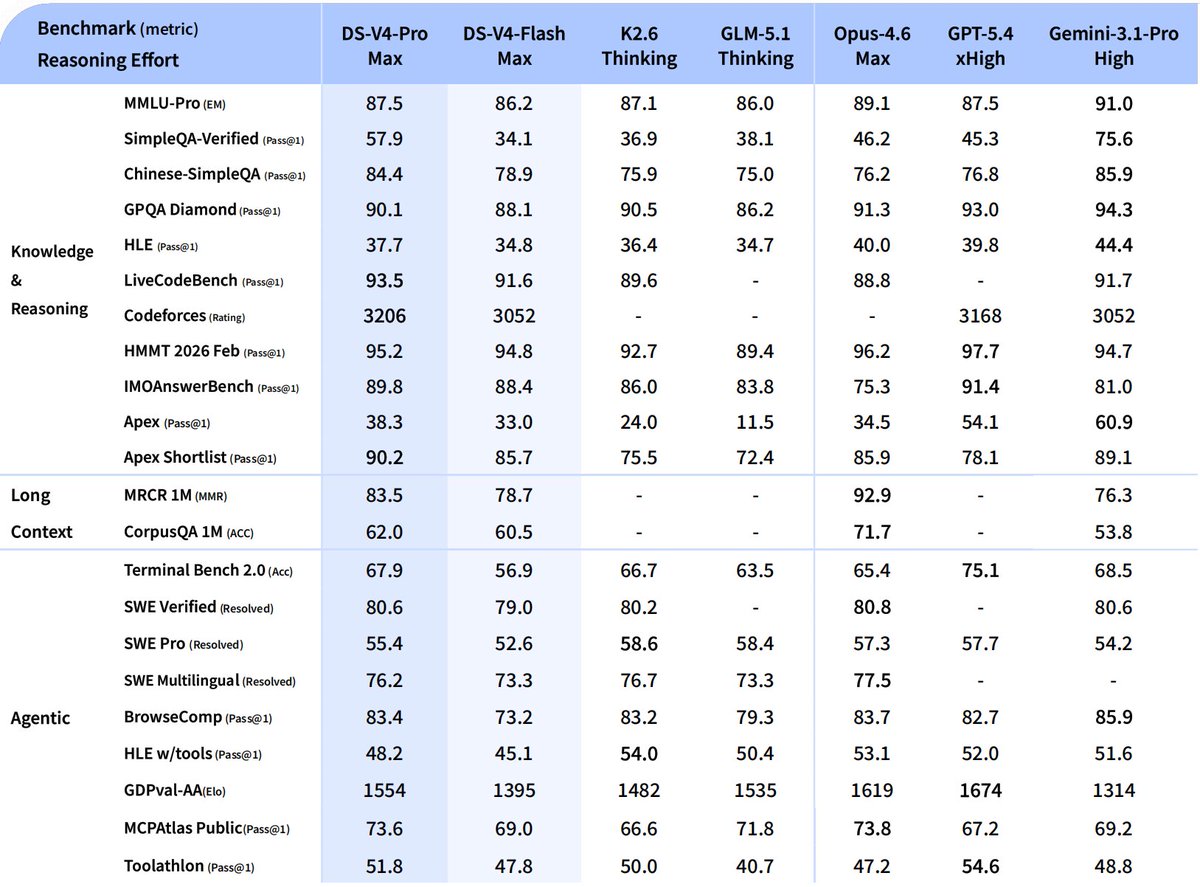
In addition to exceeding Opus 4.6 on Terminal Bench and virtually matching on other performance metrics, the most notable advancement is this statement:
"In the 1M-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2"
To understand significance of this point, consider below diagram that shows memory layout for Prefill and Decode nodes.
If you implement Decode with Data and Expert parallelism (DEP16) with 16 GPUs on GB200 or GB300 NVL72 rack with DeepSeek v3.2, you are left with 104GB or 176 GB HBRAM per GPU respectively. Here we are assuming MoE parameters are in NVFP4.
The remaining HBRAM per GPU dictates how large batch size you can have for inference, which determines how many concurrent request you can serve.
Consider GB300 with 176GB left:
1. For 128K context, you need 4.45 GB HBRam for KV Cache, and you can serve only 36 concurrent requests.
2. For 256K context, you need 8.90 GB HBRam for KV Cache, and you can serve only 18 concurrent requests.
3. For 512K context, you need 17.80 GB HBRam for KV Cache, and you can serve only 9 concurrent requests.
4. For 1M context, you need 35.60 GB HBRam for KV Cache, and you can serve only 4 concurrent requests.
You see the point. Now you imagine, you actually required 10 times less KV cache somehow at 1M!
It basically enables you to server 10 times more requests with same resources. Recall Decode is memory bound and not compute bound, unlike Prefill.
This is probably the most important contribution of DeepSeek V4.
@teortaxesTex @jukan05 @zephyr_z9