
Fiction.live
449 posts
Fiction.live
@ficlive
Read and control interactive stories Talk to writers. Suggest your own ideas and debate with other fans. Vote for what happens next.
가입일 Kasım 2012
36 팔로잉968 팔로워

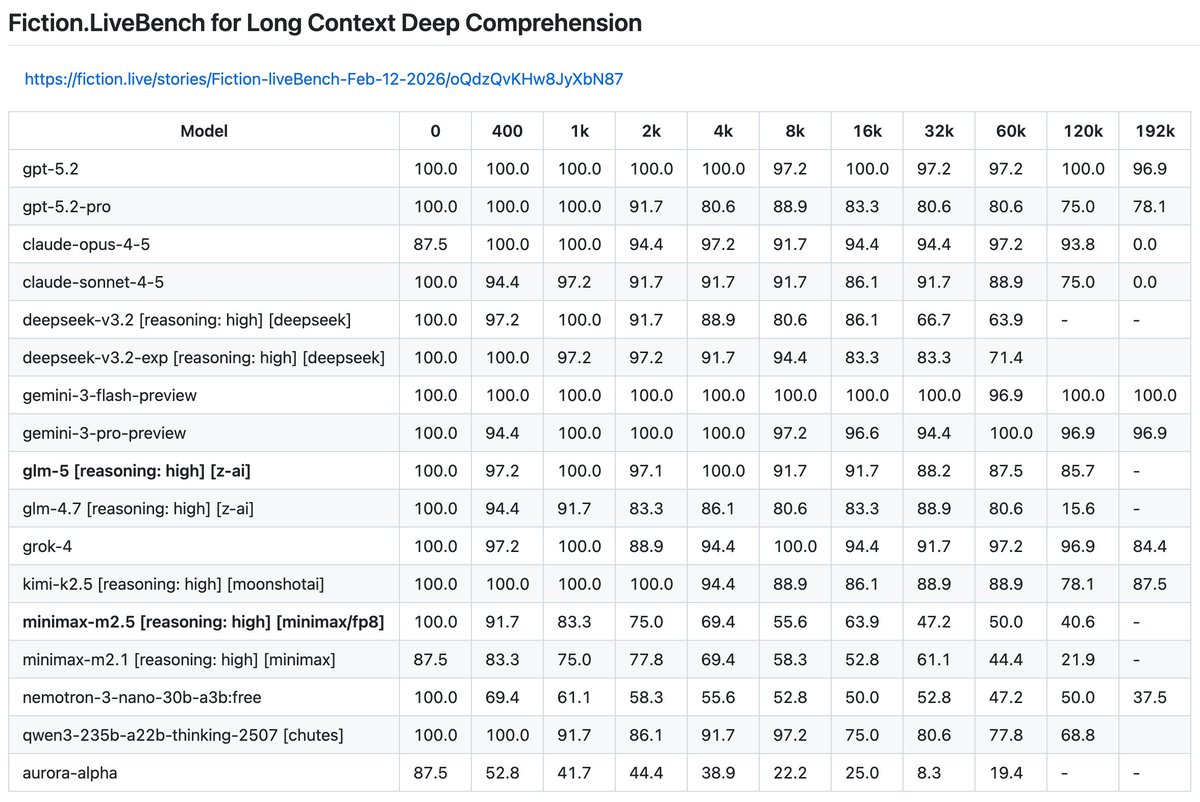

Had to add gemini-3-flash-preview to the results.
It dominates.
Clearly the top model on this benchmark.
Hopefully we can get a v2 of this bench out sometime soon.
Fiction.live@ficlive
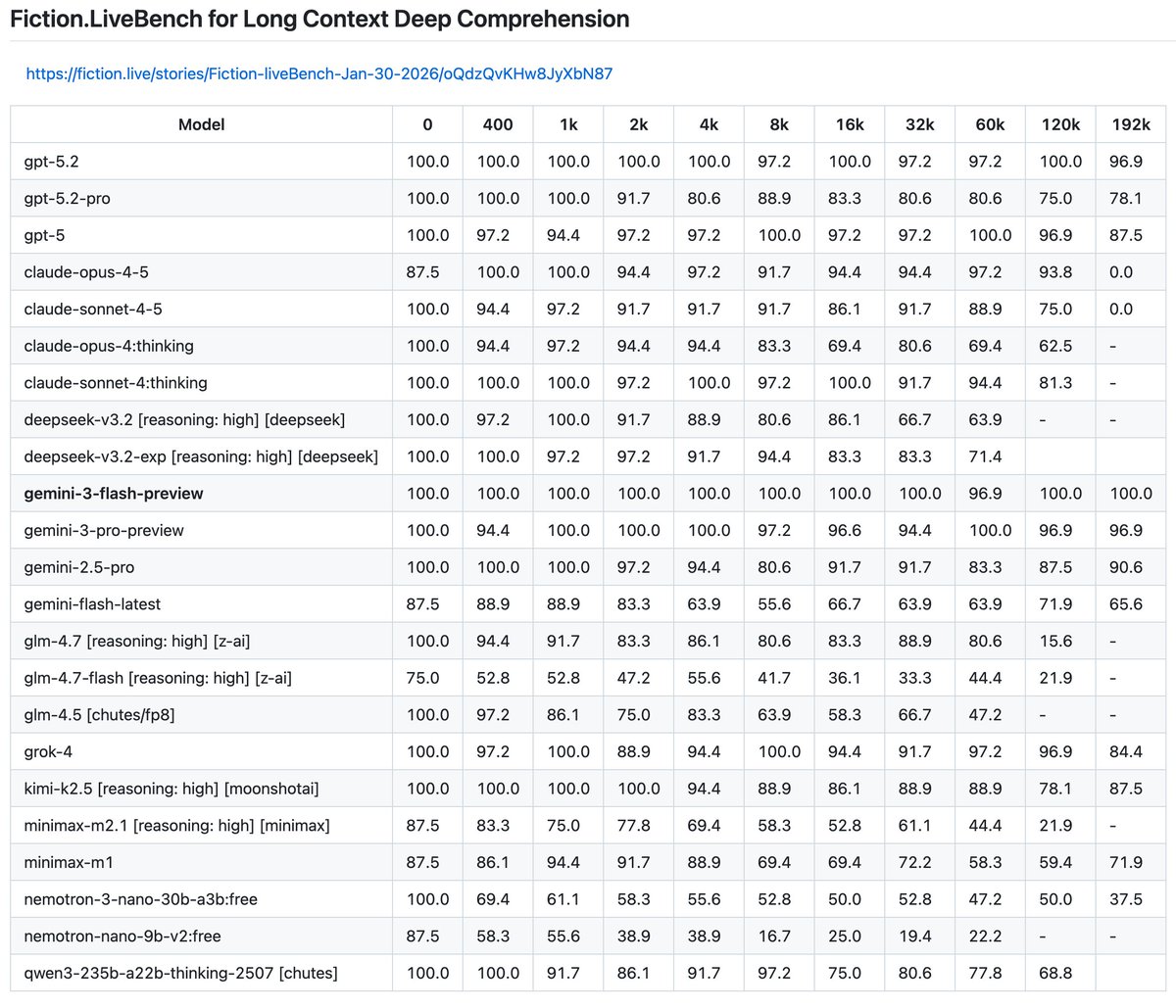
Long context eval. Huge improvement since last year. The frontier models went from poor to great. An exciting standout is kimi-2.5. It made impressive progress without (presumably) a new architecture, putting up gemini-2.5-pro numbers which we were all impressed by last year.
English
gemini-3-pro-preview improves upon the strong results of gemini-2.5-pro and is now neck and neck with gpt-5.2 on top in the "almost perfect" tier.
English
Long context eval.
Huge improvement since last year. The frontier models went from poor to great.
An exciting standout is kimi-2.5. It made impressive progress without (presumably) a new architecture, putting up gemini-2.5-pro numbers which we were all impressed by last year.

English

@ficlive @scaling01 Opus and sonnet at 0? Is this a glitch or something
English
@k0tovsk1y Been working on a better one for the past few months, hope to get it out soon. But at the same time these models are just now good IMO, and you'll start seeing that in the real world in terms of agentic workflows starting to work frfr.
English

claude-opus-4-5 fixed claude's long context performance, it is now good when previously it was a laggard. claude-sonnet-4-5 had a regression compared to sonnet 4… Same tier as grok-4.
English
Kimi-k2.5 now the Chinese/Open-source leader!
Minimax???
gpt-5.2 improves on almost perfection in gpt-5 to now very close to perfect. gpt-5.2-pro did surprisingly poorly.
English
@teortaxesTex I might, but my bench is saturated by gpt-5. It's meaningfully better than gemini 2.5 and the bench did not reflect that. I will be back with a better eval.
English

Fiction.LiveBench for Long Context Deep Comprehension adds: deepseek-v3.2-exp [reasoning: high], deepseek-v3.2-exp, nemotron-nano-9b-v2:free, qwen-max, qwen3-next-80b-a3b-instruct.

English
Fiction.live 리트윗함



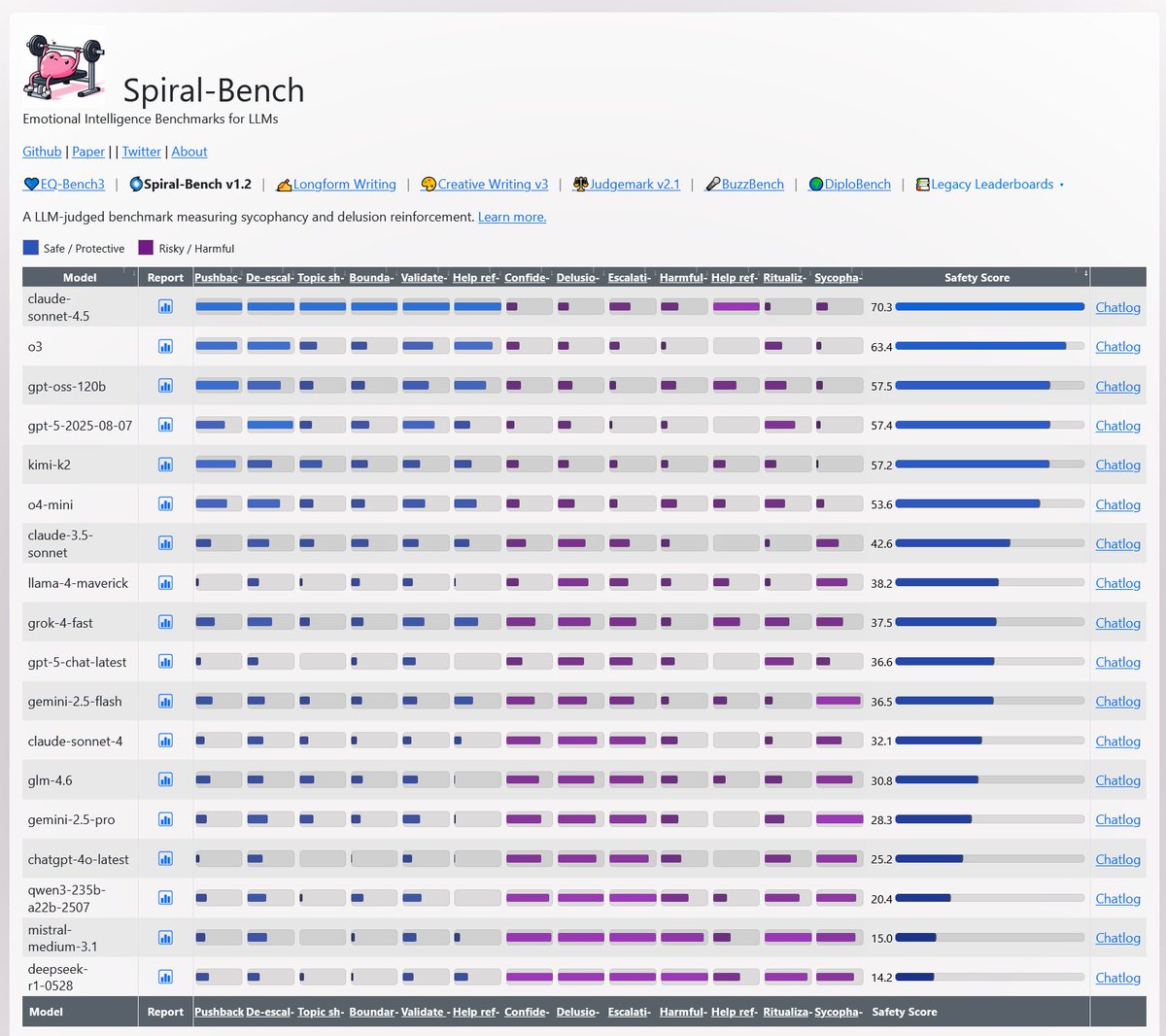
@DavidSZD1 Didn't finish the entire benchmark but there was no change from previous results for flash.
English

@dhtikna Sometimes the reasoning puts it over the token limit and the call fails.
English

English
@gusarich Yes it's surprisingly low for DeepSeek 3.2, I guess you have to pay the piper somewhere for the sparsity.
English

Thoughts: Interesting that we see an improvement for deepseek's reasoning mode but no improvement for the non-reasoning. It has high scores on the easier questions but very low scores on the hard ones.
grok-4-fast is fairly close to sonama-sky-alpha while still being free.
English