Jasper Obico 🍉 리트윗함

When predictor variables are too closely related, your regression model struggles to determine which one truly matters. This issue, known as multicollinearity, inflates standard errors, distorts coefficient estimates, and weakens model reliability. Variance Inflation Factor (VIF) helps detect and quantify this problem, ensuring more stable and interpretable results.
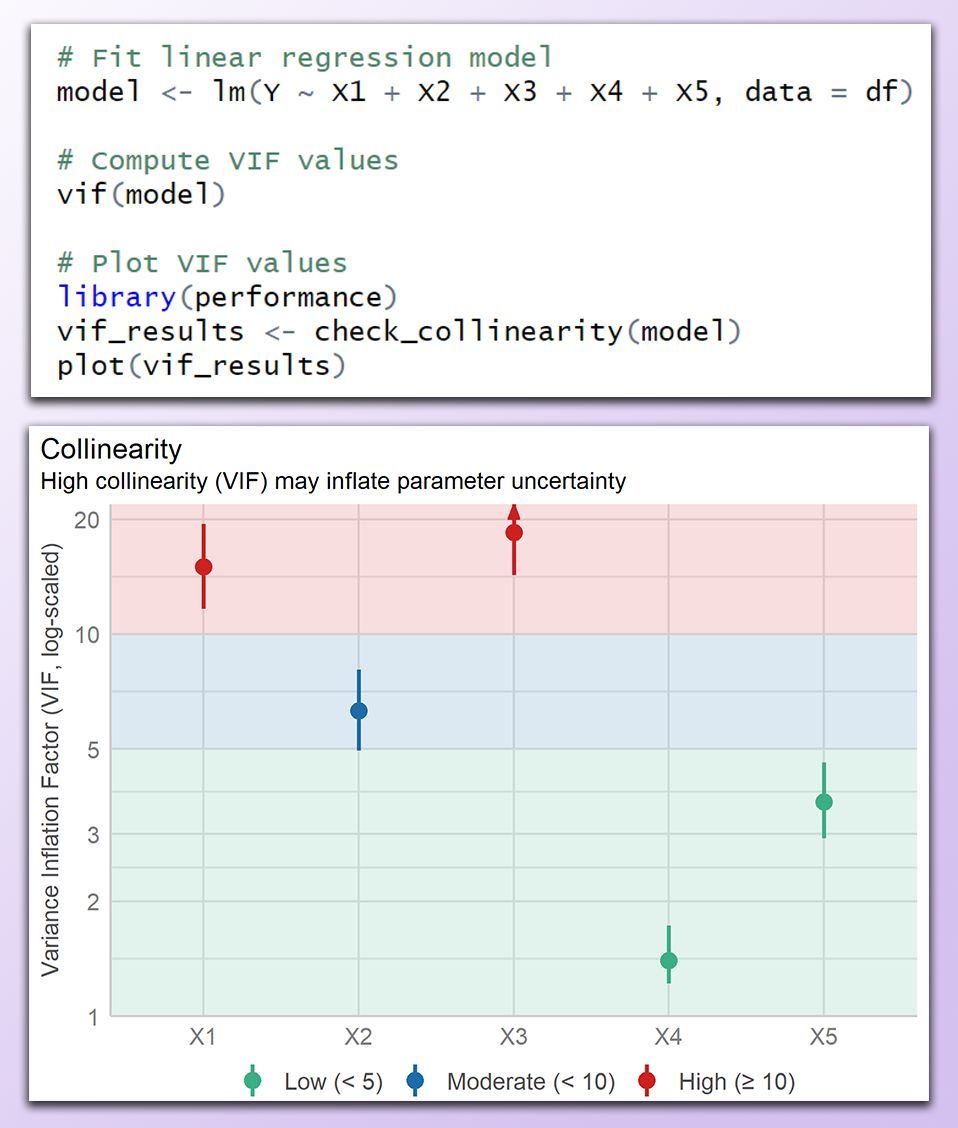
✔️ A VIF below 5 suggests low multicollinearity, while values between 5 and 10 indicate moderate correlation that may require attention. A VIF above 10 is considered problematic, as it can significantly distort regression estimates.
✔️ Addressing high VIF values improves model stability. Strategies include removing redundant variables, combining correlated predictors, using Principal Component Analysis (PCA), or applying regularization techniques like ridge regression.
❌ VIF only detects linear relationships, meaning nonlinear dependencies may go unnoticed. Alternative methods, such as Generalized Additive Models (GAMs) or mutual information, can capture nonlinear correlations.
❌ VIF does not indicate whether collinearity affects the target variable, so it should be used alongside domain knowledge and model evaluation techniques. Even if VIF is high, multicollinearity is only a concern if it negatively impacts model predictions or inference.
The image below was created in R and shows a VIF plot categorizing predictor variables into low (green), moderate (blue), and high (red) multicollinearity. Variables X1 and X3 have high VIF values, indicating strong collinearity that should be addressed before interpreting the model.
🔹 In R, vif() from the car package computes VIF, while check_collinearity() from performance provides visualization. Ridge regression with glmnet can mitigate multicollinearity by applying regularization.
🔹 In Python, variance_inflation_factor() from statsmodels.stats.outliers_influence quantifies multicollinearity, and ridge regression with sklearn.linear_model.Ridge() helps stabilize estimates by penalizing large coefficients.
Looking to improve your regression models? Check out my online course on Statistical Methods in R! Further details: statisticsglobe.com/online-course-…
#R4DS #DataViz #Statistical #RStats #pythonlearning #Python #datavis #Rpackage
English