
Cheng-I Jeff Lai
154 posts
Cheng-I Jeff Lai
@jefflai108
Voice AI @Meta l Ex @WaveFormsAI @GoogleDeepMind | phd @MIT_CSAIL
San Francisco 가입일 Ekim 2022
1.6K 팔로잉502 팔로워

Voice AI has grown a lot recently, and definitions of models/systems have become somewhat vague. Let's put down some basics.
1. AI "models" are not AI "systems".
Models are the core units that build up a system. For text-only systems, the two are trivially equivalent (discounting the BPE tokenizer/detokenizer), but not for voice. For voice AI systems, examples of model may be ASR, TTS, LLM, SpeechLLM, OmniLLM, etc.
2. A model is the smallest replaceable unit within a system.
For example, an STT model (user speech in / agent text out) often contains a speech encoder + an LLM, but neither of these components can be replaced without having to train the model again.
3. A speech-to-speech "system" (often called a voice agent) may take many forms and comprise many components, but it is always based on two requirements:
(A) response generation --> what/how to respond
(B) duplex control --> when to talk.
Traditionally, (A) has been handled through an ASR/LLM/TTS cascade. Most of the current S2S modeling research aims to replace this pipeline with fewer models (either STT+TTS or S2S).
Most systems still rely on external VADs and WebRTC for (B), with the famous exception of "full-duplex" models like Moshi.
4a. A SpeechLLM is a model that takes text+speech input, but only generates text output. It is also called a "speech understanding" model.
4b. An OmniLLM is a SpeechLLM that also generates speech (either codecs or continuous latents). It is also called a "speech generation" model (not to be confused with a TTS).
5. A speech-to-speech system is considered "realtime" if it satisfies 3 conditions: low latency (< 1s), streaming audio in/out, and barge-in/interruption handling. It can also be called a full-duplex system (not to be confused with a full-duplex "model").
English

English

🎓 Officially graduated from @WavLab @LTIatCMU @CarnegieMellon
Excited to start a new chapter as an Audio Researcher @AnuttaconGames 🚀
Grateful for amazing mentors @shinjiw_at_cmu , collaborators, and the speech/audio community along the way.
English
I’m happy to share that I’m starting a new position as Senior Research Scientist at @nvidia!
Looking forward to open science for speech full-duplex models :)

Desh Raj@rdesh26
After 2 wonderful years, I left Meta this week. During this time, I worked on several projects related to speech and LLMs: - Built the first multi-channel audio foundation model with M-BEST-RQ (arxiv.org/abs/2409.11494) - Made ASR with SpeechLLMs faster (arxiv.org/abs/2409.08148) and more accurate (ieeexplore.ieee.org/document/10890…) - Shipped the first production-ready full-duplex voice assistant (about.fb.com/news/2025/04/i…) - Improved Moshi’s reasoning capability with chain-of-thought (arxiv.org/abs/2510.07497) I am grateful to my managers for having my back on critical projects, and fortunate to have collaborated with several brilliant researchers and engineers during this time. As to what's next, I am still in NYC and continuing to do speech research. More on that later!
English

Ponodos makes some really interesting stuff...
podonos.com/resembleai/cha…
English


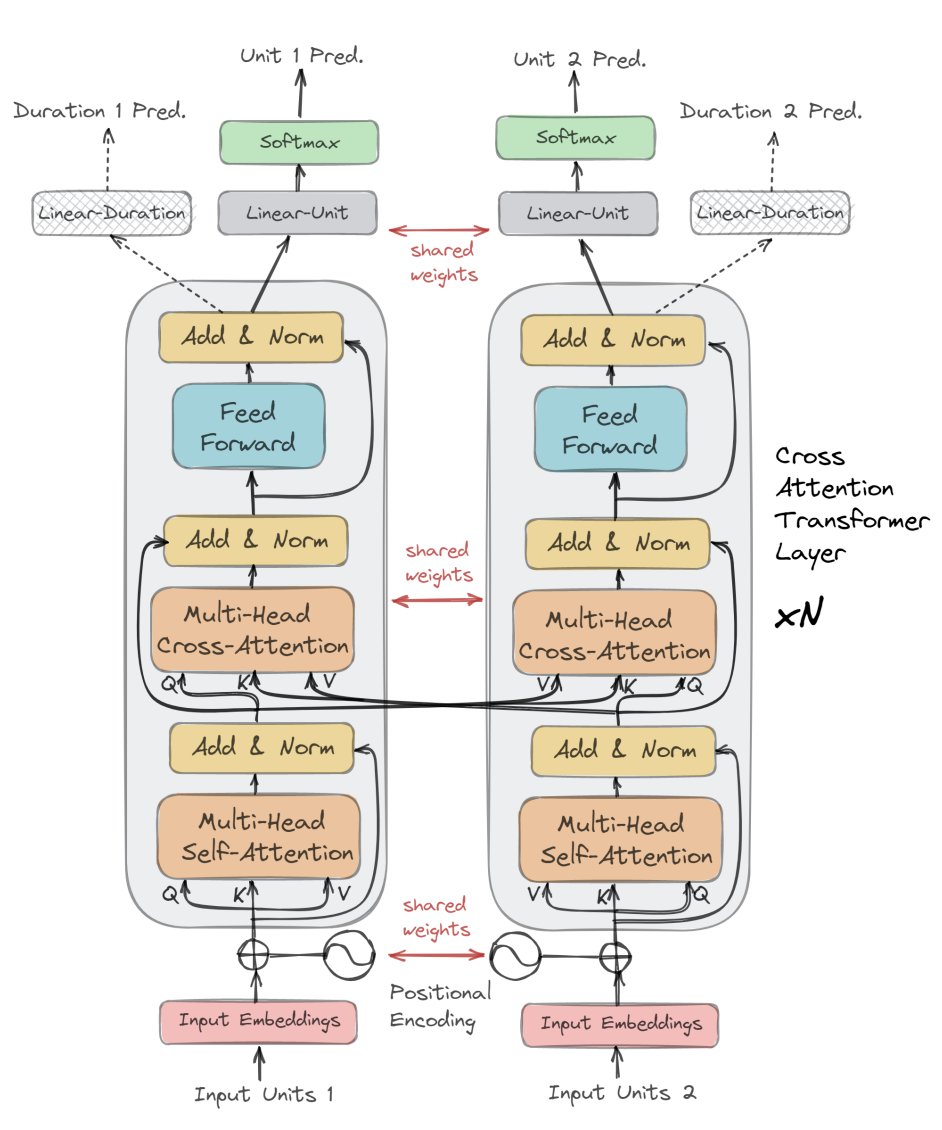
🔥 Generative Spoken Dialogue Language Modeling
Learning the joint distribution P(User, System) isn’t new. In fact, Nguyen et al. (dGSLM, 2021) did this using a dual-tower transformer (figure below + link: speechbot.github.io/dgslm/index.ht…)
Their recipe 👇
• HuBERT tokens
• 6-layer Transformer backbone
• Trained only on ~2k hrs of Fisher
Even with that modest setup, the generated dialogs were shockingly fluent. The model could continue conversations with turn-taking and backchannels. Pretty cool for its time. 🔥
Now imagine scaling this up with:
✨ modern codecs (Mimi, nano-codec)
✨ a bigger backbone (8B+ MoE)
✨ orders of magnitude more podcast data
…we likely get end-to-end, natural dialog generation that feels like two humans riffing on a topic. 🤯
So why didn’t we go all-in on this? I think there are two bottlenecks:
1. Two-channel dialog data is scarce + expensive.
2. Dual-tower limits utility: it only models 2-channel speech to 2-channel speech. No grounding. No knowledge infusion.
You can’t feed it text, images, a PDF, or a blog and expect a meaningful podcast out the other end.
The result?
A brilliant proof-of-concept that generates free-flowing chatter, but doesn’t carry the world knowledge or controllability required for real applications.
Still, dGSLM was quite ahead of its time and laid the foundations for modern FDX systems!
Desh Raj@rdesh26
🚀 Full-duplex (FDX) models are all the rage in voice AI right now — but what is “full-duplex”?
Think of it like the difference between a normal phone call 📞 and a walkie-talkie 🎙️:
• Half-duplex = only one side talks at a time
• Full-duplex = both sides can speak simultaneously
User (U): u u u u u u - - - - - - - - - - - u u u
System (S): - - - - - - - - s s s s s s s s s s s --
In theory, an FDX model tries to learn the joint probability P(U, S) — basically a language model over "user+system" token pairs.
Speech isn’t naturally discrete, so we use neural codecs 🎧 to turn waveforms into tokens (this itself is an entire field of research).
👉 In practice, we don’t model the full joint probability. Since the user audio is available, we instead learn the conditional distribution: P(s_t | U_{<=t}, S_{
English
It's another grad school application season. Some of you will get into your dream programs, while others will have to make compromises. Yet more will face disappointment all round.
But this won't be the end of the road. Here's something I wrote more than 8 years ago after getting 12/12 rejections in my first grad applications:
@rdesh26/what-i-learned-from-my-12-grad-school-rejections-ec7c6dc0f8b9" target="_blank" rel="nofollow noopener">medium.com/@rdesh26/what-…
English

📢 Some big (& slightly belated) life updates!
1. I defended my PhD at MIT this summer! 🎓
2. I'm joining NYU as an Assistant Professor starting Fall 2026, with a joint appointment in Courant CS and the Center for Data Science. 🎉
🔬 My lab will focus on empirically studying the science of deep learning and applying deep learning to accelerate the natural sciences.
Very broadly interested in questions at the intersection of language, reasoning and sequential decision making. (Plus any other fun problems that catch our eye along the way!)
🚀 I am recruiting 2 PhD students for this cycle! If you're interested in joining, please apply here: cs.nyu.edu/dynamic/phd/ad… cds.nyu.edu/phd-admissions…



English
@jiatongshi Careful ablation studies are a thing of the past
English
This is exactly the reason we worked for ESPnet-Codec, but being really hard to keep tracking as people are fast nowadays.
The similar issue happens at most speech tasks from ASR, TTS, to general speech LLM. It's a bit sad time for driving scientific findings 🥲
🐿️🐒🗻📚🐹🦈@SythonUK
ヌラールオヂオーコデクの論文、全く違うデータで学習されたモデルを比較して「ワイらのモデル最強や!!😤😤😤」と主張しているものばかりで😩😩😩😩😩😩😩😩😩😩😩に関するMOS値が1000000になった
English

A company/org/institution that strips the people of their dignity can win but not earn respect. What's the point of anything if the people are marginalized?
English

Data is more important than ever
Karan Goel@krandiash
We've raised $100M from Kleiner Perkins, Index Ventures, Lightspeed, and NVIDIA. Today we're introducing Sonic-3 - the state-of-the-art model for realtime conversation. What makes Sonic-3 great: - Breakthrough naturalness - laughter and full emotional range - Lightning fast -
English

@jefflai108 I don’t know where those people are now, but it feels like the field has instead moved towards scaling supervised/pseudo-labeled data and focusing on the multi-task problem via LLMs. Obviously this works, but it has anti-synergy with the low-resource direction
English
a while back, almost all of the most well-known speech researchers were pushing for low-resource or even zero-resource speech. The premise of building speech technology for all spoken languages with min supervision was very alluring. I wonder what they’re up to now?
English



Hard to see the layoffs at Meta — so many brilliant people and mentors I learned from. I went through those same struggles @tydsh mentioned: the uncertainty, the long nights, the hope things would turn around — and the disappointment before finally deciding to leave.
After two months of rest and reflection, I’m grateful to be joining @_inception_ai to work on diffusion LLMs — continuing my research on discrete diffusion from FAIR and exploring its potential for ultrafast, scalable reasoning in language models. 🚀
Wishing my former teammates all the best as they carry the work forward.
Yuandong Tian@tydsh
Several of my team members + myself are impacted by this layoff today. Welcome to connect :)
English