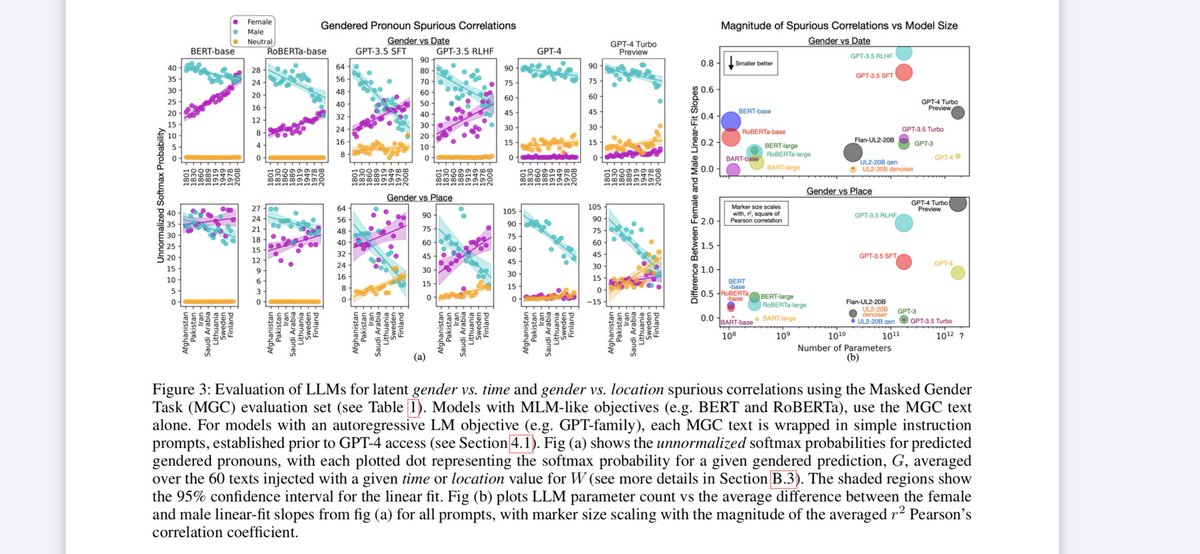
emily mcmilin 리트윗함

How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
English