nano 리트윗함
nano
3.4K posts


I seriously think that openai started purposely hurting ml research capabilities with this model, it's literally worse at taste than 5.2 high. I understand the competitive advantage of withholding capabilities but still they should just admit it and not waste anyone's time.
English
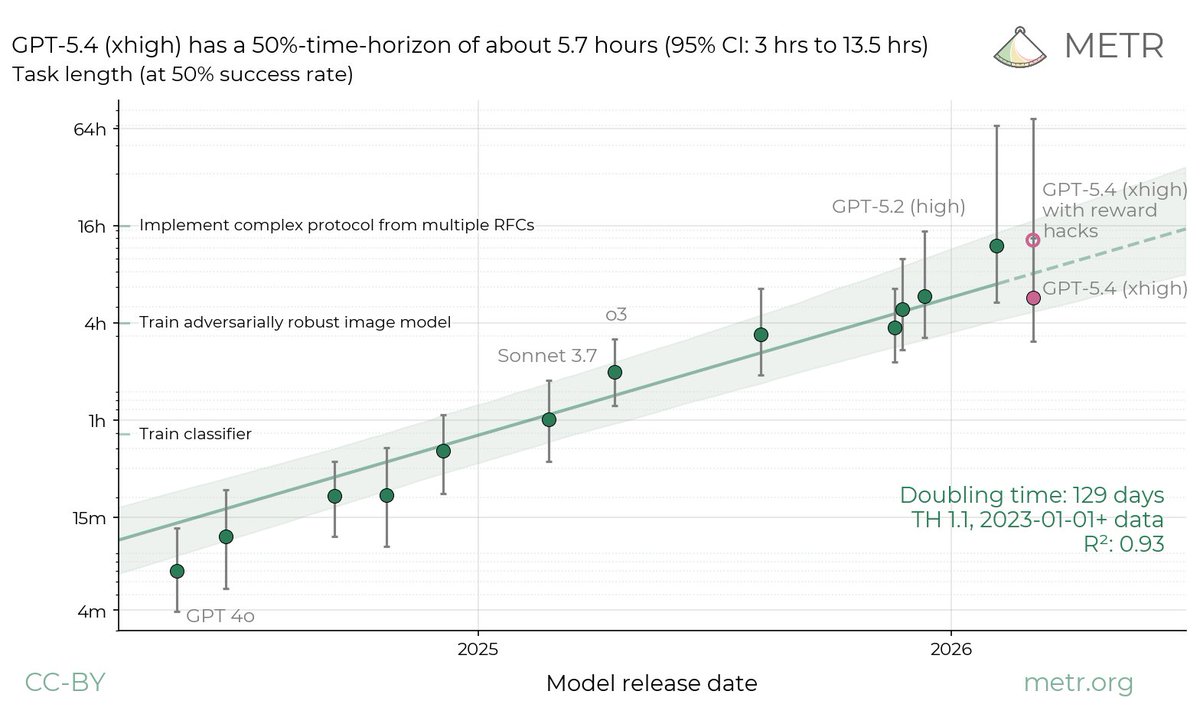
5.4 xhigh is worse than 5.3 codex at ml research, running experiments, patching gated features and debugging inference and evals. It's maybe better at moonshooting proposals just like 5.2 high but it does not have a robust experimentation hygiene. Same with 5.4 pro vs 5.2 pro.
English
nano 리트윗함

Step inside Project Genie: our experimental research prototype that lets you create, edit, and explore virtual worlds. 🌎
English
nano 리트윗함
We’re announcing a major advance in the study of fluid dynamics with AI 💧 in a joint paper with researchers from @BrownUniversity, @nyuniversity and @Stanford.

English
nano 리트윗함
What if you could not only watch a generated video, but explore it too? 🌐
Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
English
Gemini 2.5 Deep Think Model Card:
it's not superhuman but similar to gold IMO model & “approaches human level” on stealth evals
more interested in learning “novel rl techniques that can leverage more multi-step reasoning,” (candidate: MARL with verification/voting for each step)




English


good to see hle uselessness being confirmed after ~3 months of this thread
actually, it's not just useless it's harmfull signal that somewhat slowed down the progress imo
x.com/andrewwhite01/…
Andrew White 🐦⬛@andrewwhite01
HLE has recently become the benchmark to beat for frontier agents. We @FutureHouseSF took a closer look at the chem and bio questions and found about 30% of them are likely invalid based on our analysis and third-party PhD evaluations. 1/7
English
GDM achieved the same score at IMO as OpenAI but it will be accessible to ultra subscribers in a trusted program.
Google DeepMind@GoogleDeepMind
An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International Mathematical Olympiad. 🥇 It solved 5️⃣ out of 6️⃣ exceptionally difficult problems, involving algebra, combinatorics, geometry and number theory. Here’s how 🧵
English


we achieved gold medal level performance on the 2025 IMO competition with a general-purpose reasoning system! to emphasize, this is an LLM doing math and not a specific formal math system; it is part of our main push towards general intelligence.
when we first started openai, this was a dream but not one that felt very realistic to us; it is a significant marker of how far AI has come over the past decade.
we are releasing GPT-5 soon but want to set accurate expectations: this is an experimental model that incorporates new research techniques we will use in future models. we think you will love GPT-5, but we don't plan to release a model with IMO gold level of capability for many months.
Alexander Wei@alexwei_
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
English
@brutalmog @polynoamial @OpenAI isn't that a polymarket prediction? I was talking about manifold one
English

@nanulled @polynoamial @OpenAI it fell to 30 because the resolution is dependent to imo grand challenge which require the model to be open source
English

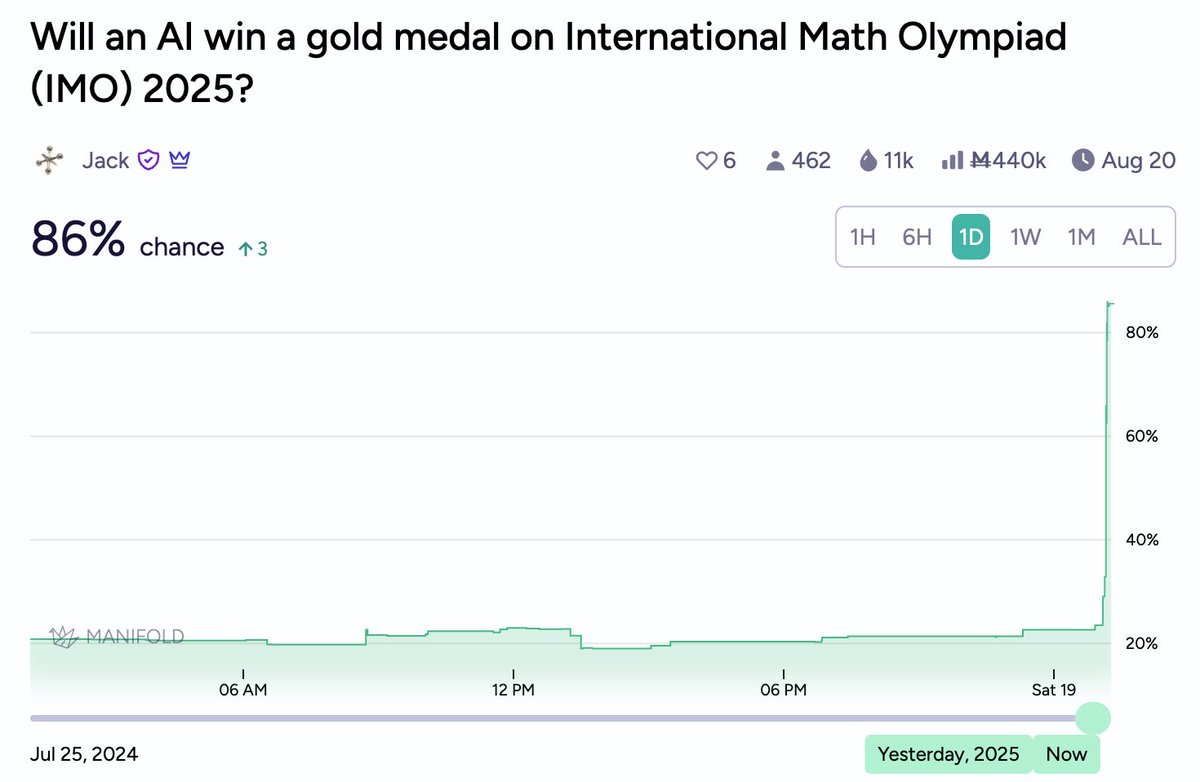
@bennetkrause they've said it's a reasoning model so scratchpad with some form of memory maintenance mechanism that they've probably rled using a general reasoning breakthrough
i bet that it's not just a verifier, it would be much more bullish if it were a model itself so I bet on that
English

OpenAI’ reasoning model thinks for hours and got gold medal level performance on IMO
Progress is faster than most thought
Noam Brown@polynoamial
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools. As remarkable as that sounds, it’s even more significant than the headline 🧵
English

@polynoamial Amazing, Noam
q: this IMO was solved by LLM or a system of agents with MARL or something even better?
English
Their bet allowed for formal math AI systems (like AlphaProof). In 2022, almost nobody thought an LLM could be IMO gold level by 2025.
Nat McAleese@__nmca__
We are seeing much faster AI progress than **Paul Christiano** and **Yudkowsky** predicted, who had gold in 2025 at 8% and 16% respectively, by methods that are more general than expected
English
@zephyr_z9 @epicarism If I didn't want to disclose something I would not say anything related to the multi-agent system
Perhaps he really wanted to share it but couldn't do it directly
English

@nanulled @epicarism What if they don't want to disclose it??
Sheryl & Noam are working on the multi-agent RL team
This is the only concrete info we have
English
I think it's pretty safe to say that some form of RSI cycle has begun
Alexander Wei@alexwei_
8/N Btw, we are releasing GPT-5 soon, and we’re excited for you to try it. But just to be clear: the IMO gold LLM is an experimental research model. We don’t plan to release anything with this level of math capability for several months.
English
@epicarism @zephyr_z9 i know that
pay attention to the wording
"models" not a model or reasoning LLM
they should've said that imo was solved by agents or system not by a "model"
English

@nanulled @zephyr_z9 all agents are models in use, you can't have "agents" without a "model". This was likely from MARL / experimental model fine tuned for multi agents etc
English
@zephyr_z9 interesting
from what I've seen they claimed that's a reasoning model not a system of agents
English